Branch 2.3 #21726
Closed
Branch 2.3 #21726
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…edColumnReader ## What changes were proposed in this pull request? Re-add support for parquet binary DecimalType in VectorizedColumnReader ## How was this patch tested? Existing test suite Author: James Thompson <[email protected]> Closes #20580 from jamesthomp/jt/add-back-binary-decimal. (cherry picked from commit 5bb1141) Signed-off-by: gatorsmile <[email protected]>
…l schema doesn't have metadata. ## What changes were proposed in this pull request? This is a follow-up pr of #19231 which modified the behavior to remove metadata from JDBC table schema. This pr adds a test to check if the schema doesn't have metadata. ## How was this patch tested? Added a test and existing tests. Author: Takuya UESHIN <[email protected]> Closes #20585 from ueshin/issues/SPARK-22002/fup1. (cherry picked from commit 0c66fe4) Signed-off-by: gatorsmile <[email protected]>
## What changes were proposed in this pull request? This PR adds a migration guide documentation for ORC. 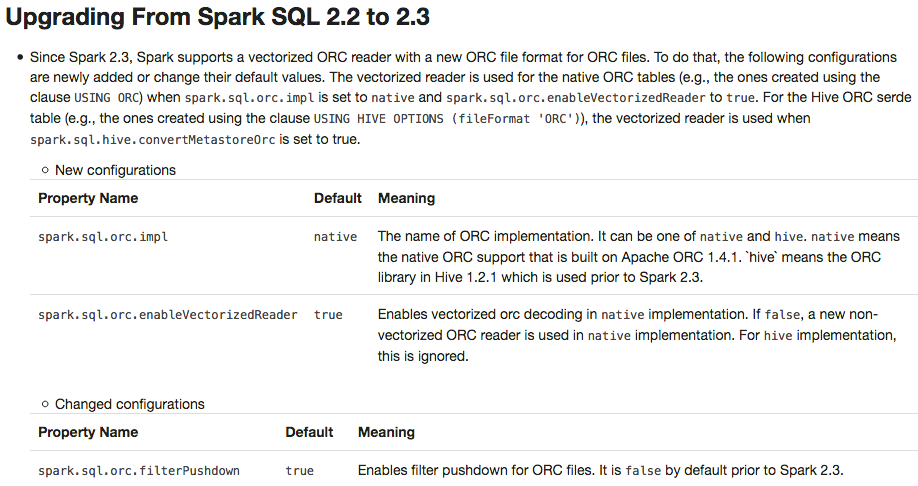 ## How was this patch tested? N/A. Author: Dongjoon Hyun <[email protected]> Closes #20484 from dongjoon-hyun/SPARK-23313. (cherry picked from commit 6cb5970) Signed-off-by: gatorsmile <[email protected]>
{kind=link}
…e types, create textfile table cause a serde error When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error. We should take the default type of textfile and sequencefile both as org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe. ``` set hive.default.fileformat=orc; create table tbl( i string ) stored as textfile; desc formatted tbl; Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde InputFormat org.apache.hadoop.mapred.TextInputFormat OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat ``` Author: sychen <[email protected]> Closes #20406 from cxzl25/default_serde. (cherry picked from commit 4104b68) Signed-off-by: gatorsmile <[email protected]>
…in Pandas UDFs ## What changes were proposed in this pull request? This PR backports #20531: It explicitly specifies supported types in Pandas UDFs. The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things. 1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see: ```python from pyspark.sql.functions import pandas_udf pudf = pandas_udf(lambda x: x, "binary") df = spark.createDataFrame([[bytearray(1)]]) df.select(pudf("_1")).show() ``` ``` ... TypeError: Unsupported type in conversion to Arrow: BinaryType ``` We can document this behaviour for its guide. 2. Since we can check the return type ahead, we can fail fast before actual execution. ```python # we can fail fast at this stage because we know the schema ahead pandas_udf(lambda x: x, BinaryType()) ``` ## How was this patch tested? Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added. Author: hyukjinkwon <[email protected]> Closes #20588 from HyukjinKwon/PR_TOOL_PICK_PR_20531_BRANCH-2.3.
## What changes were proposed in this pull request? Deprecating the field `name` in PySpark is not expected. This PR is to revert the change. ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20595 from gatorsmile/removeDeprecate. (cherry picked from commit 407f672) Signed-off-by: hyukjinkwon <[email protected]>
…ns found, the last updated time is not formatted and client local time zone is not show in history server web ui. ## What changes were proposed in this pull request? When it has no incomplete(completed) applications found, the last updated time is not formatted and client local time zone is not show in history server web ui. It is a bug. fix before:  fix after:  ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <[email protected]> Closes #20573 from guoxiaolongzte/SPARK-23384. (cherry picked from commit 300c40f) Signed-off-by: Sean Owen <[email protected]>
{kind=link}
{kind=link}
…late in DagScheduler.submitMissingTasks should keep the same RDD checkpoint status ## What changes were proposed in this pull request? When we run concurrent jobs using the same rdd which is marked to do checkpoint. If one job has finished running the job, and start the process of RDD.doCheckpoint, while another job is submitted, then submitStage and submitMissingTasks will be called. In [submitMissingTasks](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L961), will serialize taskBinaryBytes and calculate task partitions which are both affected by the status of checkpoint, if the former is calculated before doCheckpoint finished, while the latter is calculated after doCheckpoint finished, when run task, rdd.compute will be called, for some rdds with particular partition type such as [UnionRDD](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/rdd/UnionRDD.scala) who will do partition type cast, will get a ClassCastException because the part params is actually a CheckpointRDDPartition. This error occurs because rdd.doCheckpoint occurs in the same thread that called sc.runJob, while the task serialization occurs in the DAGSchedulers event loop. ## How was this patch tested? the exist uts and also add a test case in DAGScheduerSuite to show the exception case. Author: huangtengfei <[email protected]> Closes #20244 from ivoson/branch-taskpart-mistype. (cherry picked from commit 091a000) Signed-off-by: Imran Rashid <[email protected]>
…IN query ## What changes were proposed in this pull request? Added flag ignoreNullability to DataType.equalsStructurally. The previous semantic is for ignoreNullability=false. When ignoreNullability=true equalsStructurally ignores nullability of contained types (map key types, value types, array element types, structure field types). In.checkInputTypes calls equalsStructurally to check if the children types match. They should match regardless of nullability (which is just a hint), so it is now called with ignoreNullability=true. ## How was this patch tested? New test in SubquerySuite Author: Bogdan Raducanu <[email protected]> Closes #20548 from bogdanrdc/SPARK-23316. (cherry picked from commit 05d0512) Signed-off-by: gatorsmile <[email protected]>
…r ML persistence ## What changes were proposed in this pull request? Added documentation about what MLlib guarantees in terms of loading ML models and Pipelines from old Spark versions. Discussed & confirmed on linked JIRA. Author: Joseph K. Bradley <[email protected]> Closes #20592 from jkbradley/SPARK-23154-backwards-compat-doc. (cherry picked from commit d58fe28) Signed-off-by: Joseph K. Bradley <[email protected]>
## What changes were proposed in this pull request? In this upcoming 2.3 release, we changed the interface of `ScalaUDF`. Unfortunately, some Spark packages (e.g., spark-deep-learning) are using our internal class `ScalaUDF`. In the release 2.3, we added new parameters into this class. The users hit the binary compatibility issues and got the exception: ``` > java.lang.NoSuchMethodError: org.apache.spark.sql.catalyst.expressions.ScalaUDF.<init>(Ljava/lang/Object;Lorg/apache/spark/sql/types/DataType;Lscala/collection/Seq;Lscala/collection/Seq;Lscala/Option;)V ``` This PR is to improve the backward compatibility. However, we definitely should not encourage the external packages to use our internal classes. This might make us hard to maintain/develop the codes in Spark. ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20591 from gatorsmile/scalaUDF. (cherry picked from commit 2ee76c2) Signed-off-by: Shixiong Zhu <[email protected]>
…olumnarBatchReader This PR aims to resolve an open file leakage issue reported at [SPARK-23390](https://issues.apache.org/jira/browse/SPARK-23390) by moving the listener registration position. Currently, the sequence is like the following. 1. Create `batchReader` 2. `batchReader.initialize` opens a ORC file. 3. `batchReader.initBatch` may take a long time to alloc memory in some environment and cause errors. 4. `Option(TaskContext.get()).foreach(_.addTaskCompletionListener(_ => iter.close()))` This PR moves 4 before 2 and 3. To sum up, the new sequence is 1 -> 4 -> 2 -> 3. Manual. The following test case makes OOM intentionally to cause leaked filesystem connection in the current code base. With this patch, leakage doesn't occurs. ```scala // This should be tested manually because it raises OOM intentionally // in order to cause `Leaked filesystem connection`. test("SPARK-23399 Register a task completion listener first for OrcColumnarBatchReader") { withSQLConf(SQLConf.ORC_VECTORIZED_READER_BATCH_SIZE.key -> s"${Int.MaxValue}") { withTempDir { dir => val basePath = dir.getCanonicalPath Seq(0).toDF("a").write.format("orc").save(new Path(basePath, "first").toString) Seq(1).toDF("a").write.format("orc").save(new Path(basePath, "second").toString) val df = spark.read.orc( new Path(basePath, "first").toString, new Path(basePath, "second").toString) val e = intercept[SparkException] { df.collect() } assert(e.getCause.isInstanceOf[OutOfMemoryError]) } } } ``` Author: Dongjoon Hyun <[email protected]> Closes #20590 from dongjoon-hyun/SPARK-23399. (cherry picked from commit 357babd) Signed-off-by: Wenchen Fan <[email protected]>
…tead of the IDs ## What changes were proposed in this pull request? Extending RDD storage page to show executor addresses in the block table. ## How was this patch tested? Manually:  Author: “attilapiros” <[email protected]> Closes #20589 from attilapiros/SPARK-23394. (cherry picked from commit 140f875) Signed-off-by: Marcelo Vanzin <[email protected]>
{kind=link}
This reverts commit f5f21e8.
## What changes were proposed in this pull request? #19579 introduces a behavior change. We need to document it in the migration guide. ## How was this patch tested? Also update the HiveExternalCatalogVersionsSuite to verify it. Author: gatorsmile <[email protected]> Closes #20606 from gatorsmile/addMigrationGuide. (cherry picked from commit a77ebb0) Signed-off-by: gatorsmile <[email protected]>
## What changes were proposed in this pull request? This PR is to revert the PR #20302, because it causes a regression. ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20614 from gatorsmile/revertJsonFix. (cherry picked from commit 95e4b49) Signed-off-by: gatorsmile <[email protected]>
…row interruption exceptions directly ## What changes were proposed in this pull request? Streaming execution has a list of exceptions that means interruption, and handle them specially. `WriteToDataSourceV2Exec` should also respect this list and not wrap them with `SparkException`. ## How was this patch tested? existing test. Author: Wenchen Fan <[email protected]> Closes #20605 from cloud-fan/write. (cherry picked from commit f38c760) Signed-off-by: Wenchen Fan <[email protected]>
…D_CLASSES set to 1 ## What changes were proposed in this pull request? YarnShuffleIntegrationSuite fails when SPARK_PREPEND_CLASSES set to 1. Normally mllib built before yarn module. When SPARK_PREPEND_CLASSES used mllib classes are on yarn test classpath. Before 2.3 that did not cause issues. But 2.3 has SPARK-22450, which registered some mllib classes with the kryo serializer. Now it dies with the following error: ` 18/02/13 07:33:29 INFO SparkContext: Starting job: collect at YarnShuffleIntegrationSuite.scala:143 Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: breeze/linalg/DenseMatrix ` In this PR NoClassDefFoundError caught only in case of testing and then do nothing. ## How was this patch tested? Automated: Pass the Jenkins. Author: Gabor Somogyi <[email protected]> Closes #20608 from gaborgsomogyi/SPARK-23422. (cherry picked from commit 44e20c4) Signed-off-by: Marcelo Vanzin <[email protected]>
## What changes were proposed in this pull request? To prevent any regressions, this PR changes ORC implementation to `hive` by default like Spark 2.2.X. Users can enable `native` ORC. Also, ORC PPD is also restored to `false` like Spark 2.2.X.  ## How was this patch tested? Pass all test cases. Author: Dongjoon Hyun <[email protected]> Closes #20610 from dongjoon-hyun/SPARK-ORC-DISABLE. (cherry picked from commit 2f0498d) Signed-off-by: gatorsmile <[email protected]>
{kind=link}
## What changes were proposed in this pull request?
This replaces `Sparkcurrently` to `Spark currently` in the following error message.
```scala
scala> sql("insert into t2 select * from v1")
org.apache.spark.sql.AnalysisException: Output Hive table `default`.`t2`
is bucketed but Sparkcurrently does NOT populate bucketed ...
```
## How was this patch tested?
Manual.
Author: Dongjoon Hyun <[email protected]>
Closes #20617 from dongjoon-hyun/SPARK-ERROR-MSG.
(cherry picked from commit 6968c3c)
Signed-off-by: gatorsmile <[email protected]>
## What changes were proposed in this pull request? #### Problem: Since 2.3, `Bucketizer` supports multiple input/output columns. We will check if exclusive params are set during transformation. E.g., if `inputCols` and `outputCol` are both set, an error will be thrown. However, when we write `Bucketizer`, looks like the default params and user-supplied params are merged during writing. All saved params are loaded back and set to created model instance. So the default `outputCol` param in `HasOutputCol` trait will be set in `paramMap` and become an user-supplied param. That makes the check of exclusive params failed. #### Fix: This changes the saving logic of Bucketizer to handle this case. This is a quick fix to catch the time of 2.3. We should consider modify the persistence mechanism later. Please see the discussion in the JIRA. Note: The multi-column `QuantileDiscretizer` also has the same issue. ## How was this patch tested? Modified tests. Author: Liang-Chi Hsieh <[email protected]> Closes #20594 from viirya/SPARK-23377-2. (cherry picked from commit db45daa) Signed-off-by: Joseph K. Bradley <[email protected]>
…e page
## What changes were proposed in this pull request?
Fixing exception got at sorting tasks by Host / Executor ID:
```
java.lang.IllegalArgumentException: Invalid sort column: Host
at org.apache.spark.ui.jobs.ApiHelper$.indexName(StagePage.scala:1017)
at org.apache.spark.ui.jobs.TaskDataSource.sliceData(StagePage.scala:694)
at org.apache.spark.ui.PagedDataSource.pageData(PagedTable.scala:61)
at org.apache.spark.ui.PagedTable$class.table(PagedTable.scala:96)
at org.apache.spark.ui.jobs.TaskPagedTable.table(StagePage.scala:708)
at org.apache.spark.ui.jobs.StagePage.liftedTree1$1(StagePage.scala:293)
at org.apache.spark.ui.jobs.StagePage.render(StagePage.scala:282)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
```
Moreover some refactoring to avoid similar problems by introducing constants for each header name and reusing them at the identification of the corresponding sorting index.
## How was this patch tested?
Manually:
(cherry picked from commit 1dc2c1d)
Author: “attilapiros” <[email protected]>
Closes #20623 from squito/fix_backport.
{kind=link}
## What changes were proposed in this pull request?
This PR explicitly specifies and checks the types we supported in `toPandas`. This was a hole. For example, we haven't finished the binary type support in Python side yet but now it allows as below:
```python
spark.conf.set("spark.sql.execution.arrow.enabled", "false")
df = spark.createDataFrame([[bytearray("a")]])
df.toPandas()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
df.toPandas()
```
```
_1
0 [97]
_1
0 a
```
This should be disallowed. I think the same things also apply to nested timestamps too.
I also added some nicer message about `spark.sql.execution.arrow.enabled` in the error message.
## How was this patch tested?
Manually tested and tests added in `python/pyspark/sql/tests.py`.
Author: hyukjinkwon <[email protected]>
Closes #20625 from HyukjinKwon/pandas_convertion_supported_type.
(cherry picked from commit c5857e4)
Signed-off-by: gatorsmile <[email protected]>
…er implementations ## What changes were proposed in this pull request? Murmur3 hash generates a different value from the original and other implementations (like Scala standard library and Guava or so) when the length of a bytes array is not multiple of 4. ## How was this patch tested? Added a unit test. **Note: When we merge this PR, please give all the credits to Shintaro Murakami.** Author: Shintaro Murakami <mrkm4ntrgmail.com> Author: gatorsmile <[email protected]> Author: Shintaro Murakami <[email protected]> Closes #20630 from gatorsmile/pr-20568. (cherry picked from commit d5ed210) Signed-off-by: gatorsmile <[email protected]>
…iption. This is much faster than finding out what the last attempt is, and the data should be the same. There's room for improvement in this page (like only loading data for the jobs being shown, instead of loading all available jobs and sorting them), but this should bring performance on par with the 2.2 version. Author: Marcelo Vanzin <[email protected]> Closes #20644 from vanzin/SPARK-23470. (cherry picked from commit 2ba77ed) Signed-off-by: Sameer Agarwal <[email protected]>
…tials. The secret is used as a string in many parts of the code, so it has to be turned into a hex string to avoid issues such as the random byte sequence not containing a valid UTF8 sequence. Author: Marcelo Vanzin <[email protected]> Closes #20643 from vanzin/SPARK-23468. (cherry picked from commit 6d398c0) Signed-off-by: Marcelo Vanzin <[email protected]>
…treaming programming guide ## What changes were proposed in this pull request? - Added clear information about triggers - Made the semantics guarantees of watermarks more clear for streaming aggregations and stream-stream joins. ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Tathagata Das <[email protected]> Closes #20631 from tdas/SPARK-23454. (cherry picked from commit 601d653) Signed-off-by: Tathagata Das <[email protected]>
## What changes were proposed in this pull request? Change insert input schema type: "insertRelationType" -> "insertRelationType.asNullable", in order to avoid nullable being overridden. ## How was this patch tested? Added one test in InsertSuite. Author: Maryann Xue <[email protected]> Closes #21585 from maryannxue/spark-24583. (cherry picked from commit bc0498d) Signed-off-by: Xiao Li <[email protected]>
## What changes were proposed in this pull request? This PR tries to fix the performance regression introduced by SPARK-21517. In our production job, we performed many parallel computations, with high possibility, some task could be scheduled to a host-2 where it needs to read the cache block data from host-1. Often, this big transfer makes the cluster suffer time out issue (it will retry 3 times, each with 120s timeout, and then do recompute to put the cache block into the local MemoryStore). The root cause is that we don't do `consolidateIfNeeded` anymore as we are using ``` Unpooled.wrappedBuffer(chunks.length, getChunks(): _*) ``` in ChunkedByteBuffer. If we have many small chunks, it could cause the `buf.notBuffer(...)` have very bad performance in the case that we have to call `copyByteBuf(...)` many times. ## How was this patch tested? Existing unit tests and also test in production Author: Wenbo Zhao <[email protected]> Closes #21593 from WenboZhao/spark-24578. (cherry picked from commit 3f4bda7) Signed-off-by: Shixiong Zhu <[email protected]>
…ator. When an output stage is retried, it's possible that tasks from the previous attempt are still running. In that case, there would be a new task for the same partition in the new attempt, and the coordinator would allow both tasks to commit their output since it did not keep track of stage attempts. The change adds more information to the stage state tracked by the coordinator, so that only one task is allowed to commit the output in the above case. The stage state in the coordinator is also maintained across stage retries, so that a stray speculative task from a previous stage attempt is not allowed to commit. This also removes some code added in SPARK-18113 that allowed for duplicate commit requests; with the RPC code used in Spark 2, that situation cannot happen, so there is no need to handle it. Author: Marcelo Vanzin <[email protected]> Closes #21577 from vanzin/SPARK-24552. (cherry picked from commit c8e909c) Signed-off-by: Thomas Graves <[email protected]>
…ning from children ## What changes were proposed in this pull request? In #19080 we simplified the distribution/partitioning framework, and make all the join-like operators require `HashClusteredDistribution` from children. Unfortunately streaming join operator was missed. This can cause wrong result. Think about ``` val input1 = MemoryStream[Int] val input2 = MemoryStream[Int] val df1 = input1.toDF.select('value as 'a, 'value * 2 as 'b) val df2 = input2.toDF.select('value as 'a, 'value * 2 as 'b).repartition('b) val joined = df1.join(df2, Seq("a", "b")).select('a) ``` The physical plan is ``` *(3) Project [a#5] +- StreamingSymmetricHashJoin [a#5, b#6], [a#10, b#11], Inner, condition = [ leftOnly = null, rightOnly = null, both = null, full = null ], state info [ checkpoint = <unknown>, runId = 54e31fce-f055-4686-b75d-fcd2b076f8d8, opId = 0, ver = 0, numPartitions = 5], 0, state cleanup [ left = null, right = null ] :- Exchange hashpartitioning(a#5, b#6, 5) : +- *(1) Project [value#1 AS a#5, (value#1 * 2) AS b#6] : +- StreamingRelation MemoryStream[value#1], [value#1] +- Exchange hashpartitioning(b#11, 5) +- *(2) Project [value#3 AS a#10, (value#3 * 2) AS b#11] +- StreamingRelation MemoryStream[value#3], [value#3] ``` The left table is hash partitioned by `a, b`, while the right table is hash partitioned by `b`. This means, we may have a matching record that is in different partitions, which should be in the output but not. ## How was this patch tested? N/A Author: Wenchen Fan <[email protected]> Closes #21587 from cloud-fan/join. (cherry picked from commit dc8a6be) Signed-off-by: Xiao Li <[email protected]>
… number for writes . This passes a unique attempt id instead of attempt number to v2 data sources and hadoop APIs, because attempt number is reused when stages are retried. When attempt numbers are reused, sources that track data by partition id and attempt number may incorrectly clean up data because the same attempt number can be both committed and aborted. Author: Marcelo Vanzin <[email protected]> Closes #21615 from vanzin/SPARK-24552-2.3.
…t dependent caches Wrap the logical plan with a `AnalysisBarrier` for execution plan compilation in CacheManager, in order to avoid the plan being analyzed again. Add one test in `DatasetCacheSuite` Author: Maryann Xue <[email protected]> Closes #21602 from maryannxue/cache-mismatch.
findTightestCommonTypeOfTwo has been renamed to findTightestCommonType ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Fokko Driesprong <[email protected]> Closes #21597 from Fokko/fd-typo. (cherry picked from commit 6a97e8e) Signed-off-by: hyukjinkwon <[email protected]>
(cherry picked from commit d54d8b8) Signed-off-by: Xiao Li <[email protected]>
The ColumnPruning rule tries adding an extra Project if an input node produces fields more than needed, but as a post-processing step, it needs to remove the lower Project in the form of "Project - Filter - Project" otherwise it would conflict with PushPredicatesThroughProject and would thus cause a infinite optimization loop. The current post-processing method is defined as:
```
private def removeProjectBeforeFilter(plan: LogicalPlan): LogicalPlan = plan transform {
case p1 Project(_, f Filter(_, p2 Project(_, child)))
if p2.outputSet.subsetOf(child.outputSet) =>
p1.copy(child = f.copy(child = child))
}
```
This method works well when there is only one Filter but would not if there's two or more Filters. In this case, there is a deterministic filter and a non-deterministic filter so they stay as separate filter nodes and cannot be combined together.
An simplified illustration of the optimization process that forms the infinite loop is shown below (F1 stands for the 1st filter, F2 for the 2nd filter, P for project, S for scan of relation, PredicatePushDown as abbrev. of PushPredicatesThroughProject):
```
F1 - F2 - P - S
PredicatePushDown => F1 - P - F2 - S
ColumnPruning => F1 - P - F2 - P - S
=> F1 - P - F2 - S (Project removed)
PredicatePushDown => P - F1 - F2 - S
ColumnPruning => P - F1 - P - F2 - S
=> P - F1 - P - F2 - P - S
=> P - F1 - F2 - P - S (only one Project removed)
RemoveRedundantProject => F1 - F2 - P - S (goes back to the loop start)
```
So the problem is the ColumnPruning rule adds a Project under a Filter (and fails to remove it in the end), and that new Project triggers PushPredicateThroughProject. Once the filters have been push through the Project, a new Project will be added by the ColumnPruning rule and this goes on and on.
The fix should be when adding Projects, the rule applies top-down, but later when removing extra Projects, the process should go bottom-up to ensure all extra Projects can be matched.
Added a optimization rule test in ColumnPruningSuite; and a end-to-end test in SQLQuerySuite.
Author: maryannxue <[email protected]>
Closes #21674 from maryannxue/spark-24696.
## What changes were proposed in this pull request? Updated streaming guide for direct stream and link to integration guide. ## How was this patch tested? jekyll build Author: Rekha Joshi <[email protected]> Closes #21683 from rekhajoshm/SPARK-24507. (cherry picked from commit f599cde) Signed-off-by: hyukjinkwon <[email protected]>
…lSafe ## What changes were proposed in this pull request? In Dataset.join we have a small hack for resolving ambiguity in the column name for self-joins. The current code supports only `EqualTo`. The PR extends the fix to `EqualNullSafe`. Credit for this PR should be given to daniel-shields. ## How was this patch tested? added UT Author: Marco Gaido <[email protected]> Closes #21605 from mgaido91/SPARK-24385_2. (cherry picked from commit a7c8f0c) Signed-off-by: Wenchen Fan <[email protected]>
## What changes were proposed in this pull request? change to skip tests if - couldn't determine java version fix problem on windows ## How was this patch tested? unit test, manual, win-builder Author: Felix Cheung <[email protected]> Closes #21666 from felixcheung/rjavaskip. (cherry picked from commit 141953f) Signed-off-by: Felix Cheung <[email protected]>
|
Can one of the admins verify this patch? |
Member
|
Could you please close this? |
## What changes were proposed in this pull request?
This PR proposes to make PySpark compatible with Python 3.7. There are rather radical change in semantic of `StopIteration` within a generator. It now throws it as a `RuntimeError`.
To make it compatible, we should fix it:
```python
try:
next(...)
except StopIteration
return
```
See [release note](https://docs.python.org/3/whatsnew/3.7.html#porting-to-python-3-7) and [PEP 479](https://www.python.org/dev/peps/pep-0479/).
## How was this patch tested?
Manually tested:
```
$ ./run-tests --python-executables=python3.7
Running PySpark tests. Output is in /.../spark/python/unit-tests.log
Will test against the following Python executables: ['python3.7']
Will test the following Python modules: ['pyspark-core', 'pyspark-ml', 'pyspark-mllib', 'pyspark-sql', 'pyspark-streaming']
Starting test(python3.7): pyspark.mllib.tests
Starting test(python3.7): pyspark.sql.tests
Starting test(python3.7): pyspark.streaming.tests
Starting test(python3.7): pyspark.tests
Finished test(python3.7): pyspark.streaming.tests (130s)
Starting test(python3.7): pyspark.accumulators
Finished test(python3.7): pyspark.accumulators (8s)
Starting test(python3.7): pyspark.broadcast
Finished test(python3.7): pyspark.broadcast (9s)
Starting test(python3.7): pyspark.conf
Finished test(python3.7): pyspark.conf (6s)
Starting test(python3.7): pyspark.context
Finished test(python3.7): pyspark.context (27s)
Starting test(python3.7): pyspark.ml.classification
Finished test(python3.7): pyspark.tests (200s) ... 3 tests were skipped
Starting test(python3.7): pyspark.ml.clustering
Finished test(python3.7): pyspark.mllib.tests (244s)
Starting test(python3.7): pyspark.ml.evaluation
Finished test(python3.7): pyspark.ml.classification (63s)
Starting test(python3.7): pyspark.ml.feature
Finished test(python3.7): pyspark.ml.clustering (48s)
Starting test(python3.7): pyspark.ml.fpm
Finished test(python3.7): pyspark.ml.fpm (0s)
Starting test(python3.7): pyspark.ml.image
Finished test(python3.7): pyspark.ml.evaluation (23s)
Starting test(python3.7): pyspark.ml.linalg.__init__
Finished test(python3.7): pyspark.ml.linalg.__init__ (0s)
Starting test(python3.7): pyspark.ml.recommendation
Finished test(python3.7): pyspark.ml.image (20s)
Starting test(python3.7): pyspark.ml.regression
Finished test(python3.7): pyspark.ml.regression (58s)
Starting test(python3.7): pyspark.ml.stat
Finished test(python3.7): pyspark.ml.feature (90s)
Starting test(python3.7): pyspark.ml.tests
Finished test(python3.7): pyspark.ml.recommendation (82s)
Starting test(python3.7): pyspark.ml.tuning
Finished test(python3.7): pyspark.ml.stat (27s)
Starting test(python3.7): pyspark.mllib.classification
Finished test(python3.7): pyspark.sql.tests (362s) ... 102 tests were skipped
Starting test(python3.7): pyspark.mllib.clustering
Finished test(python3.7): pyspark.ml.tuning (29s)
Starting test(python3.7): pyspark.mllib.evaluation
Finished test(python3.7): pyspark.mllib.classification (39s)
Starting test(python3.7): pyspark.mllib.feature
Finished test(python3.7): pyspark.mllib.evaluation (30s)
Starting test(python3.7): pyspark.mllib.fpm
Finished test(python3.7): pyspark.mllib.feature (44s)
Starting test(python3.7): pyspark.mllib.linalg.__init__
Finished test(python3.7): pyspark.mllib.linalg.__init__ (0s)
Starting test(python3.7): pyspark.mllib.linalg.distributed
Finished test(python3.7): pyspark.mllib.clustering (78s)
Starting test(python3.7): pyspark.mllib.random
Finished test(python3.7): pyspark.mllib.fpm (33s)
Starting test(python3.7): pyspark.mllib.recommendation
Finished test(python3.7): pyspark.mllib.random (12s)
Starting test(python3.7): pyspark.mllib.regression
Finished test(python3.7): pyspark.mllib.linalg.distributed (45s)
Starting test(python3.7): pyspark.mllib.stat.KernelDensity
Finished test(python3.7): pyspark.mllib.stat.KernelDensity (0s)
Starting test(python3.7): pyspark.mllib.stat._statistics
Finished test(python3.7): pyspark.mllib.recommendation (41s)
Starting test(python3.7): pyspark.mllib.tree
Finished test(python3.7): pyspark.mllib.regression (44s)
Starting test(python3.7): pyspark.mllib.util
Finished test(python3.7): pyspark.mllib.stat._statistics (20s)
Starting test(python3.7): pyspark.profiler
Finished test(python3.7): pyspark.mllib.tree (26s)
Starting test(python3.7): pyspark.rdd
Finished test(python3.7): pyspark.profiler (11s)
Starting test(python3.7): pyspark.serializers
Finished test(python3.7): pyspark.mllib.util (24s)
Starting test(python3.7): pyspark.shuffle
Finished test(python3.7): pyspark.shuffle (0s)
Starting test(python3.7): pyspark.sql.catalog
Finished test(python3.7): pyspark.serializers (15s)
Starting test(python3.7): pyspark.sql.column
Finished test(python3.7): pyspark.rdd (27s)
Starting test(python3.7): pyspark.sql.conf
Finished test(python3.7): pyspark.sql.catalog (24s)
Starting test(python3.7): pyspark.sql.context
Finished test(python3.7): pyspark.sql.conf (8s)
Starting test(python3.7): pyspark.sql.dataframe
Finished test(python3.7): pyspark.sql.column (29s)
Starting test(python3.7): pyspark.sql.functions
Finished test(python3.7): pyspark.sql.context (26s)
Starting test(python3.7): pyspark.sql.group
Finished test(python3.7): pyspark.sql.dataframe (51s)
Starting test(python3.7): pyspark.sql.readwriter
Finished test(python3.7): pyspark.ml.tests (266s)
Starting test(python3.7): pyspark.sql.session
Finished test(python3.7): pyspark.sql.group (36s)
Starting test(python3.7): pyspark.sql.streaming
Finished test(python3.7): pyspark.sql.functions (57s)
Starting test(python3.7): pyspark.sql.types
Finished test(python3.7): pyspark.sql.session (25s)
Starting test(python3.7): pyspark.sql.udf
Finished test(python3.7): pyspark.sql.types (10s)
Starting test(python3.7): pyspark.sql.window
Finished test(python3.7): pyspark.sql.readwriter (31s)
Starting test(python3.7): pyspark.streaming.util
Finished test(python3.7): pyspark.sql.streaming (22s)
Starting test(python3.7): pyspark.util
Finished test(python3.7): pyspark.util (0s)
Finished test(python3.7): pyspark.streaming.util (0s)
Finished test(python3.7): pyspark.sql.udf (16s)
Finished test(python3.7): pyspark.sql.window (12s)
```
In my local (I have two Macs but both have the same issues), I currently faced some issues for now to install both extra dependencies PyArrow and Pandas same as Jenkins's, against Python 3.7.
Author: hyukjinkwon <[email protected]>
Closes #21714 from HyukjinKwon/SPARK-24739.
(cherry picked from commit 74f6a92)
Signed-off-by: hyukjinkwon <[email protected]>
… via environment variable, SPHINXPYTHON ## What changes were proposed in this pull request? This PR proposes to add `SPHINXPYTHON` environment variable to control the Python version used by Sphinx. The motivation of this environment variable is, it seems not properly rendering some signatures in the Python documentation when Python 2 is used by Sphinx. See the JIRA's case. It should be encouraged to use Python 3, but looks we will probably live with this problem for a long while in any event. For the default case of `make html`, it keeps previous behaviour and use `SPHINXBUILD` as it was. If `SPHINXPYTHON` is set, then it forces Sphinx to use the specific Python version. ``` $ SPHINXPYTHON=python3 make html python3 -msphinx -b html -d _build/doctrees . _build/html Running Sphinx v1.7.5 ... ``` 1. if `SPHINXPYTHON` is set, use Python. If `SPHINXBUILD` is set, use sphinx-build. 2. If both are set, `SPHINXBUILD` has a higher priority over `SPHINXPYTHON` 3. By default, `SPHINXBUILD` is used as 'sphinx-build'. Probably, we can somehow work around this via explicitly setting `SPHINXBUILD` but `sphinx-build` can't be easily distinguished since it (at least in my environment and up to my knowledge) doesn't replace `sphinx-build` when newer Sphinx is installed in different Python version. It confuses and doesn't warn for its Python version. ## How was this patch tested? Manually tested: **`python` (Python 2.7) in the path with Sphinx:** ``` $ make html sphinx-build -b html -d _build/doctrees . _build/html Running Sphinx v1.7.5 ... ``` **`python` (Python 2.7) in the path without Sphinx:** ``` $ make html Makefile:8: *** The 'sphinx-build' command was not found. Make sure you have Sphinx installed, then set the SPHINXBUILD environment variable to point to the full path of the 'sphinx-build' executable. Alternatively you can add the directory with the executable to your PATH. If you don't have Sphinx installed, grab it from http://sphinx-doc.org/. Stop. ``` **`SPHINXPYTHON` set `python` (Python 2.7) with Sphinx:** ``` $ SPHINXPYTHON=python make html Makefile:35: *** Note that Python 3 is required to generate PySpark documentation correctly for now. Current Python executable was less than Python 3. See SPARK-24530. To force Sphinx to use a specific Python executable, please set SPHINXPYTHON to point to the Python 3 executable.. Stop. ``` **`SPHINXPYTHON` set `python` (Python 2.7) without Sphinx:** ``` $ SPHINXPYTHON=python make html Makefile:35: *** Note that Python 3 is required to generate PySpark documentation correctly for now. Current Python executable was less than Python 3. See SPARK-24530. To force Sphinx to use a specific Python executable, please set SPHINXPYTHON to point to the Python 3 executable.. Stop. ``` **`SPHINXPYTHON` set `python3` with Sphinx:** ``` $ SPHINXPYTHON=python3 make html python3 -msphinx -b html -d _build/doctrees . _build/html Running Sphinx v1.7.5 ... ``` **`SPHINXPYTHON` set `python3` without Sphinx:** ``` $ SPHINXPYTHON=python3 make html Makefile:39: *** Python executable 'python3' did not have Sphinx installed. Make sure you have Sphinx installed, then set the SPHINXPYTHON environment variable to point to the Python executable having Sphinx installed. If you don't have Sphinx installed, grab it from http://sphinx-doc.org/. Stop. ``` **`SPHINXBUILD` set:** ``` $ SPHINXBUILD=sphinx-build make html sphinx-build -b html -d _build/doctrees . _build/html Running Sphinx v1.7.5 ... ``` **Both `SPHINXPYTHON` and `SPHINXBUILD` are set:** ``` $ SPHINXBUILD=sphinx-build SPHINXPYTHON=python make html sphinx-build -b html -d _build/doctrees . _build/html Running Sphinx v1.7.5 ... ``` Author: hyukjinkwon <[email protected]> Closes #21659 from HyukjinKwon/SPARK-24530. (cherry picked from commit 1f94bf4) Signed-off-by: hyukjinkwon <[email protected]>
A self-join on a dataset which contains a `FlatMapGroupsInPandas` fails because of duplicate attributes. This happens because we are not dealing with this specific case in our `dedupAttr` rules. The PR fix the issue by adding the management of the specific case added UT + manual tests Author: Marco Gaido <[email protected]> Author: Marco Gaido <[email protected]> Closes #21737 from mgaido91/SPARK-24208. (cherry picked from commit ebf4bfb) Signed-off-by: Xiao Li <[email protected]>
…t not work
## What changes were proposed in this pull request?
When we use a reference from Dataset in filter or sort, which was not used in the prior select, an AnalysisException occurs, e.g.,
```scala
val df = Seq(("test1", 0), ("test2", 1)).toDF("name", "id")
df.select(df("name")).filter(df("id") === 0).show()
```
```scala
org.apache.spark.sql.AnalysisException: Resolved attribute(s) id#6 missing from name#5 in operator !Filter (id#6 = 0).;;
!Filter (id#6 = 0)
+- AnalysisBarrier
+- Project [name#5]
+- Project [_1#2 AS name#5, _2#3 AS id#6]
+- LocalRelation [_1#2, _2#3]
```
This change updates the rule `ResolveMissingReferences` so `Filter` and `Sort` with non-empty `missingInputs` will also be transformed.
## How was this patch tested?
Added tests.
Author: Liang-Chi Hsieh <[email protected]>
Closes #21745 from viirya/SPARK-24781.
(cherry picked from commit dfd7ac9)
Signed-off-by: Xiao Li <[email protected]>
…till flaky; fall back to Apache archive ## What changes were proposed in this pull request? Try only unique ASF mirrors to download Spark release; fall back to Apache archive if no mirrors available or release is not mirrored ## How was this patch tested? Existing HiveExternalCatalogVersionsSuite Author: Sean Owen <[email protected]> Closes #21776 from srowen/SPARK-24813. (cherry picked from commit bbc2ffc) Signed-off-by: hyukjinkwon <[email protected]>
…ite still flaky; fall back to Apache archive ## What changes were proposed in this pull request? Test HiveExternalCatalogVersionsSuite vs only current Spark releases ## How was this patch tested? `HiveExternalCatalogVersionsSuite` Author: Sean Owen <[email protected]> Closes #21793 from srowen/SPARK-24813.3. (cherry picked from commit 5215344) Signed-off-by: Sean Owen <[email protected]>
## What changes were proposed in this pull request? When speculation is enabled, TaskSetManager#markPartitionCompleted should write successful task duration to MedianHeap, not just increase tasksSuccessful. Otherwise when TaskSetManager#checkSpeculatableTasks,tasksSuccessful non-zero, but MedianHeap is empty. Then throw an exception successfulTaskDurations.median java.util.NoSuchElementException: MedianHeap is empty. Finally led to stopping SparkContext. ## How was this patch tested? TaskSetManagerSuite.scala unit test:[SPARK-24677] MedianHeap should not be empty when speculation is enabled Author: sychen <[email protected]> Closes #21656 from cxzl25/fix_MedianHeap_empty. (cherry picked from commit c8bee93) Signed-off-by: Thomas Graves <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
70 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.