[SPARK-23313][DOC] Add a migration guide for ORC #20484
Conversation
|
cc @gatorsmile and @cloud-fan . |
docs/sql-programming-guide.md
Outdated
| native | ||
| </td> | ||
| <td> | ||
| The name of ORC implementation: 'native' means the native version of ORC support instead of the ORC library in Hive 1.2.1. It is 'hive' by default prior to Spark 2.3. |
There was a problem hiding this comment.
the native version of ORC support -> the native ORC support that is built on Apache ORC 1.4.1
docs/sql-programming-guide.md
Outdated
| </tr> | ||
| <tr> | ||
| <td> | ||
| spark.sql.orc.columnarReaderBatchSize |
There was a problem hiding this comment.
This is not available in 2.3, right?
docs/sql-programming-guide.md
Outdated
| true | ||
| </td> | ||
| <td> | ||
| Enables the built-in ORC reader and writer to process Hive ORC tables, instead of Hive serde. It is 'false' by default prior to Spark 2.3. |
There was a problem hiding this comment.
The end users might ask what is the built-in ORC reader/writer?
There was a problem hiding this comment.
What about the following?
Enable Spark's ORC support instead of Hive SerDe when reading from and writing to Hive metastore ORC tables
There was a problem hiding this comment.
Hive metastore ORC tables are still not straightforward. : )
There was a problem hiding this comment.
I borrowed it from the following in the same doc.
When reading from and writing to Hive metastore Parquet tables, Spark SQL will try to use its own Parquet support instead of Hive SerDe for better performance. This behavior is controlled by the spark.sql.hive.convertMetastoreParquet configuration, and is turned on by default.
There was a problem hiding this comment.
Then, Hive ORC tables?
Enable Spark's ORC support instead of Hive SerDe when reading from and writing to Hive ORC tables
|
Test build #86969 has finished for PR 20484 at commit
|
|
Test build #86970 has finished for PR 20484 at commit
|
|
Test build #86971 has finished for PR 20484 at commit
|
|
Test build #86973 has finished for PR 20484 at commit
|
 felixcheung
left a comment
felixcheung
left a comment
There was a problem hiding this comment.
TBH, it feels a bit verbose to fit into the migration guide section, perhaps it should have its own ORC section? anyway, just my 2c.
docs/sql-programming-guide.md
Outdated
|
|
||
| ## Upgrading From Spark SQL 2.2 to 2.3 | ||
|
|
||
| - Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC file format for ORC files and Hive ORC tables. To do that, the following configurations are newly added or change their default values. |
There was a problem hiding this comment.
re: the following configurations are newly added or change their default values.
these are all new, right?
There was a problem hiding this comment.
The last two are existing one~
docs/sql-programming-guide.md
Outdated
| true | ||
| </td> | ||
| <td> | ||
| Enables vectorized orc decoding in 'native' implementation. If 'false', a new non-vectorized ORC reader is used in 'native' implementation. |
There was a problem hiding this comment.
should say it doesn't affect the hive implementation perhaps?
docs/sql-programming-guide.md
Outdated
| native | ||
| </td> | ||
| <td> | ||
| The name of ORC implementation: 'native' means the native ORC support that is built on Apache ORC 1.4.1 instead of the ORC library in Hive 1.2.1. It is 'hive' by default prior to Spark 2.3. |
docs/sql-programming-guide.md
Outdated
| true | ||
| </td> | ||
| <td> | ||
| Enable Spark's ORC support instead of Hive SerDe when reading from and writing to Hive ORC tables. It is `false` by default prior to Spark 2.3. |
There was a problem hiding this comment.
How about?
Enable the Spark's ORC support, which can be configured by
spark.sql.orc.impl, instead of ...
There was a problem hiding this comment.
Sounds good. I'll update like this.
docs/sql-programming-guide.md
Outdated
| <code>true</code> | ||
| </td> | ||
| <td> | ||
| Enable Spark's ORC support instead of Hive SerDe when reading from and writing to Hive ORC tables. It is <code>false</code> by default prior to Spark 2.3. |
There was a problem hiding this comment.
How about?
Enable the Spark's ORC support, which can be configured by spark.sql.orc.impl, instead of ...
|
Test build #86978 has finished for PR 20484 at commit
|
|
Test build #86977 has finished for PR 20484 at commit
|
docs/sql-programming-guide.md
Outdated
| <th> | ||
| <b>Meaning</b> | ||
| </th> | ||
| </tr> |
There was a problem hiding this comment.
Can we layout the above html tags similarly with other tables in this doc? E.g.,
<table class="table">
<tr><th>Property Name</th><th>Meaning</th></tr>
<tr>| ## Upgrading From Spark SQL 2.2 to 2.3 | ||
|
|
||
| - Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC file format for ORC files and Hive ORC tables. To do that, the following configurations are newly added or change their default values. | ||
|
|
There was a problem hiding this comment.
Shall we separate newly added configurations and changed ones?
There was a problem hiding this comment.
Yep. Now, we have two tables.
docs/sql-programming-guide.md
Outdated
| <code>native</code> | ||
| </td> | ||
| <td> | ||
| The name of ORC implementation: <code>native</code> means the native ORC support that is built on Apache ORC 1.4.1 instead of the ORC library in Hive 1.2.1. It is <code>hive</code> by default prior to Spark 2.3. |
There was a problem hiding this comment.
I think this is newly added config. So It is <code>hive</code> by default prior to Spark 2.3. sounds like it is an existing config before 2.3.
|
Test build #86984 has finished for PR 20484 at commit
|
|
@dongjoon-hyun Do our native readers respect Hive confs? If not, we need to clearly document it. I think this is a common question from the existing users of ORC readers, since they are respected in the prior versions. |
|
Actually, I handed over all confs to ORC library. The following is all supported ORC configuration. Please note that the confs are interpreted by both Hive Conf Name and ORC Conf Names. Yesterday, @tgravescs asked about cc @tgravescs . |
docs/sql-programming-guide.md
Outdated
| </tr> | ||
| </table> | ||
|
|
||
| - Since Apache ORC 1.4.1 is a standalone library providing a subset of Hive ORC related configurations, you can use ORC configuration name and Hive configuration name. To see a full list of supported ORC configurations, see <a href="https://github.com/apache/orc/blob/master/java/core/src/java/org/apache/orc/OrcConf.java">OrcConf.java</a>. |
There was a problem hiding this comment.
We might need to explicitly mention they need to specify the corresponding ORC configuration names when they explicitly or implicitly use the native readers.
There was a problem hiding this comment.
For supported confs, OrcConf provides a pair of ORC/Hive key names. ORC keys are recommended but not needed.
STRIPE_SIZE("orc.stripe.size", "hive.exec.orc.default.stripe.size",
64L * 1024 * 1024, "Define the default ORC stripe size, in bytes."),
There was a problem hiding this comment.
You mean these hive conf works for our native readers? Could you add test cases for them?
There was a problem hiding this comment.
It's possible in another PR. BTW, about the test coverage,
- Do you want to see specifically
orc.stripe.sizeandhive.exec.orc.default.stripe.sizeonly? - Do we have a test coverage before for old Hive ORC code path?
There was a problem hiding this comment.
You can do a search. We need to improve our ORC test coverage for sure.
If possible, please add test cases to see whether both orc.stripe.size and hive.exec.orc.default.stripe.size work for two Spark's ORC readers. We also need the same tests for checking whether hive.exec.orc.default.stripe.size works for Hive serde tables.
To ensure the correctness of the documentation, I hope we can at least submit a PR for testing them before merging this PR?
There was a problem hiding this comment.
Yep. +1. I'll make another PR for that today. @gatorsmile .
(I was wondering if I need to do for all the other Hive/ORC configurations.)
There was a problem hiding this comment.
Yes. We can check whether some important conf works
For example,
create table if not exists vectororc (s1 string, s2 string)
stored as ORC tblproperties(
"orc.row.index.stride"="1000",
"hive.exec.orc.default.stripe.size"="100000",
"orc.compress.size"="10000");After auto conversion, do these confs in tblproperties are still being used by our native readers?
We also need to check whether the confs set in the configuration file are also recognized by our native readers.
There was a problem hiding this comment.
Sorry for late response. @gatorsmile .
Here, your example is a mixed scenario. First of all, I made a PR, #20517, for "Add ORC configuration tests for ORC data source". It adds a test coverage for ORC and Hive configuration names for native and hive OrcFileFormat. The PR aims to focus on name compatibility for those important confs.
For convertMetastoreOrc, the table properties are retained when we check by using spark.sessionState.catalog.getTableMetadata(TableIdentifier(tableName)). However, it seems to be ignored on some cases. I guess it also does in Parquet. I'm working on it separately.
|
Test build #87011 has finished for PR 20484 at commit
|
I just want to confirm whether all the Hive readers work fine. Could you add a test case like what we did in |
|
@dongjoon-hyun This is still a regression to the existing Hive ORC users. cc @cloud-fan @sameeragarwal Maybe we should fix it before the release? |
docs/sql-programming-guide.md
Outdated
| <tr> | ||
| <td><code>spark.sql.hive.convertMetastoreOrc</code></td> | ||
| <td><code>true</code></td> | ||
| <td>Enable the Spark's ORC support, which can be configured by <code>spark.sql.orc.impl</code>, instead of Hive SerDe when reading from and writing to Hive ORC tables. It is <code>false</code> by default prior to Spark 2.3.</td> |
There was a problem hiding this comment.
this isn't entirely clear to me. I assume this has to be true for spark.sql.orc.impl to work? If so perhaps we should mention it above in spark.sql.orc.impl. If this is false what happens, it can't read Orc format? or it just falls back to spark.sql.orc.impl=hive
There was a problem hiding this comment.
Yes. This has to be true for only Hive ORC table.
But, for the other Spark tables created by 'USING ORC', this is irrelevant.
spark.sql.orc.impl and spark.sql.hive.convertMetastoreOrc is orthogonal.
spark.sql.orc.impl=hive and spark.sql.hive.convertMetastoreOrc=true converts Hive ORC tables into legacy OrcFileFormat based on Hive 1.2.1.
docs/sql-programming-guide.md
Outdated
| </tr> | ||
| </table> | ||
|
|
||
| - Since Apache ORC 1.4.1 is a standalone library providing a subset of Hive ORC related configurations, see <a href="https://orc.apache.org/docs/hive-config.html">Hive Configuration</a> of Apache ORC project for a full list of supported ORC configurations. |
There was a problem hiding this comment.
how does one specify these configurations, is it simply --conf hive.stats.gather.num.threads=8 or do you still have to specify spark.hadoop.hive.stats.gather.num.threads?
There was a problem hiding this comment.
It might be more clear here if we say something like: The native ORC implementation uses the Apache ORC 1.4.1 standalone library. This means only a subset of the Hive ORC related configurations are supported. See ...
There was a problem hiding this comment.
For user configurations, both spark.hadoop. or hive-site.xml works.
|
Just FYI, #20536 is reverting the conf Thanks! |
|
I see. I removed |
|
why did you remove the bit about the orc configs? |
|
Test build #87177 has finished for PR 20484 at commit
|
|
Oh, I thought in this way, @tgravescs .
|
|
ok |
|
Test build #87342 has finished for PR 20484 at commit
|
docs/sql-programming-guide.md
Outdated
|
|
||
| ## Upgrading From Spark SQL 2.2 to 2.3 | ||
|
|
||
| - Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC file format for ORC files. To do that, the following configurations are newly added or change their default values. For creating ORC tables, `USING ORC` or `USING HIVE` syntaxes are recommended. |
There was a problem hiding this comment.
When users create tables by USING HIVE, we are using the ORC library in Hive 1.2.1 to read/write ORC tables unless they manually change spark.sql.hive.convertMetastoreOrc to true.
The last message is confusing to me.
There was a problem hiding this comment.
Hm. Right. What about mentioning convertMetastoreOrc is safe with USING HIVE then?
There was a problem hiding this comment.
Just describe the scenario in which the new vectorized ORC reader will be used. I think that will be enough.
There was a problem hiding this comment.
Okay. I see. Thanks!
docs/sql-programming-guide.md
Outdated
|
|
||
| ## Upgrading From Spark SQL 2.2 to 2.3 | ||
|
|
||
| - Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC file format for ORC files. To do that, the following configurations are newly added or change their default values. For ORC tables, the vectorized reader will be used for the tables created by `USING ORC`. With `spark.sql.hive.convertMetastoreOrc=true`, it will for the tables created by `USING HIVE OPTIONS (fileFormat 'ORC')`, too. |
There was a problem hiding this comment.
The vectorized reader is used for the native ORC tables (e.g., the ones created using the clause
USING ORC) whenspark.sql.orc.implis set tonativeandspark.sql.orc.enableVectorizedReadertotrue. For the Hive ORC serde table (e.g., the ones created using the clauseUSING HIVE OPTIONS (fileFormat 'ORC')), the vectorized reader is used whenspark.sql.hive.convertMetastoreOrcis set totrue.
|
LGTM except the above comment. |
|
Test build #87351 has finished for PR 20484 at commit
|
|
Test build #87353 has finished for PR 20484 at commit
|
|
Test build #87354 has finished for PR 20484 at commit
|
## What changes were proposed in this pull request? This PR adds a migration guide documentation for ORC. 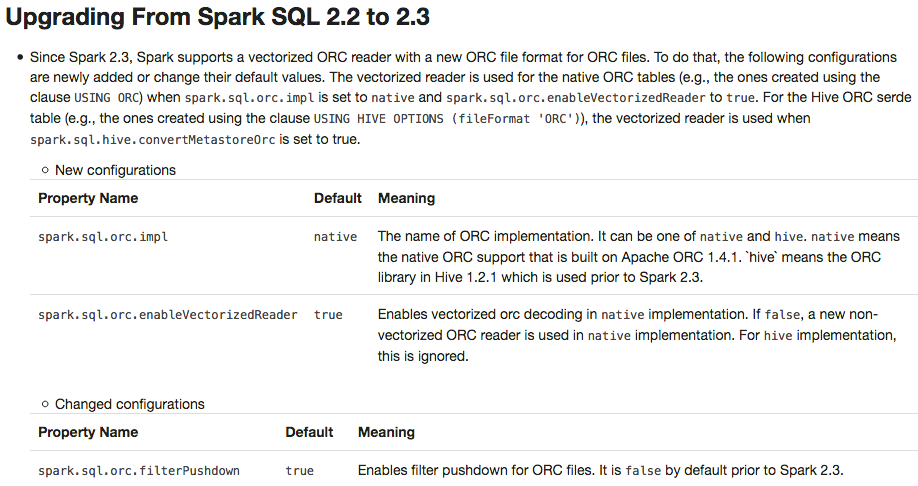 ## How was this patch tested? N/A. Author: Dongjoon Hyun <[email protected]> Closes #20484 from dongjoon-hyun/SPARK-23313. (cherry picked from commit 6cb5970) Signed-off-by: gatorsmile <[email protected]>
{kind=link}
|
Thanks! Merged to master and 2.3. |
|
Thank you, @gatorsmile , @tgravescs , @felixcheung . |
What changes were proposed in this pull request?
This PR adds a migration guide documentation for ORC.
How was this patch tested?
N/A.