[SPARK-40283][INFRA] Make MiMa check default exclude private object and bump previousSparkVersion to 3.3.0
#37741
Conversation
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Maybe, do you think you can clean up more like SPARK-36004?
like f2ed5d8? |
Seems failed. Let me check again |
project/MimaExcludes.scala
Outdated
| ProblemFilters.exclude[ReversedMissingMethodProblem]("org.apache.spark.shuffle.api.SingleSpillShuffleMapOutputWriter.transferMapSpillFile"), | ||
| ProblemFilters.exclude[ReversedMissingMethodProblem]("org.apache.spark.shuffle.api.ShuffleMapOutputWriter.commitAllPartitions"), | ||
|
|
||
| // [SPARK-39506] In terms of 3 layer namespace effort, add currentCatalog, setCurrentCatalog and listCatalogs API to Catalog interface |
There was a problem hiding this comment.
wrong place, will correct it later
There was a problem hiding this comment.
should be v34excludes
| // [SPARK-36173][CORE] Support getting CPU number in TaskContext | ||
| ProblemFilters.exclude[ReversedMissingMethodProblem]("org.apache.spark.TaskContext.cpus"), | ||
|
|
||
| // [SPARK-38679][CORE] Expose the number of partitions in a stage to TaskContext |
There was a problem hiding this comment.
wrong place, should in v34excludes
| ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.deploy.DeployMessages#RequestExecutors.apply") | ||
| ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.deploy.DeployMessages#RequestExecutors.apply"), | ||
|
|
||
| // [SPARK-38679][CORE] Expose the number of partitions in a stage to TaskContext |
There was a problem hiding this comment.
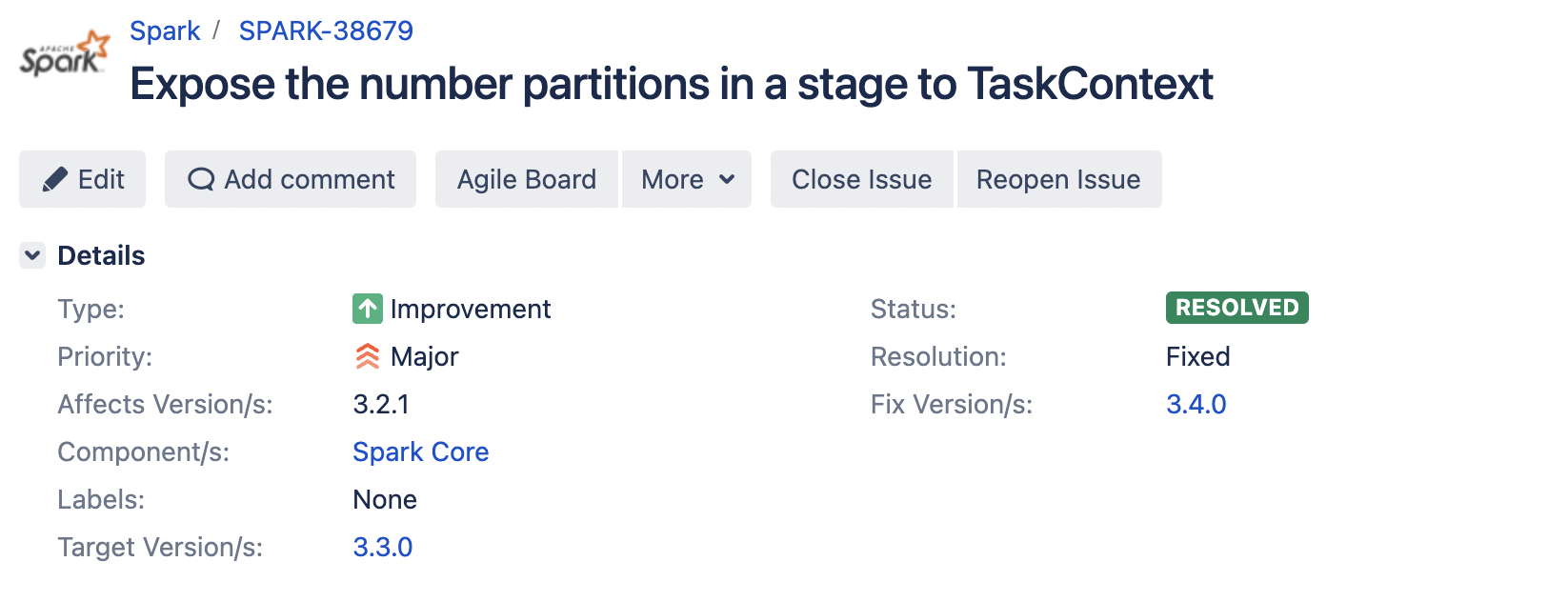
It was placed in v32excludes before, and move to v34excludes in this pr.
cc @vkorukanti and @cloud-fan SPARK-38679:
| // [SPARK-38679][CORE] Expose the number of partitions in a stage to TaskContext | ||
| ProblemFilters.exclude[ReversedMissingMethodProblem]("org.apache.spark.TaskContext.numPartitions"), | ||
|
|
||
| // [SPARK-39506] In terms of 3 layer namespace effort, add currentCatalog, setCurrentCatalog and listCatalogs API to Catalog interface |
There was a problem hiding this comment.
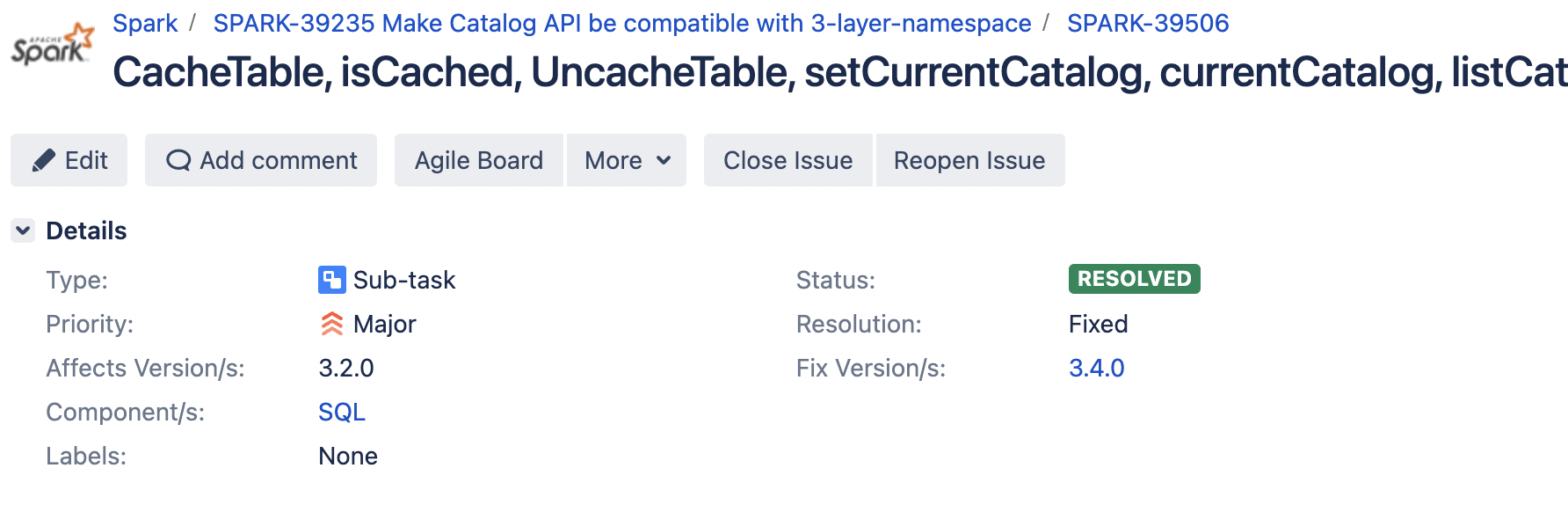
It was placed in v32excludes before, and move to v34excludes in this pr.
cc @amaliujia and @cloud-fan for SPARK-39506
| ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.sql.types.Decimal.fromStringANSI"), | ||
| ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.sql.types.Decimal.fromStringANSI$default$3"), | ||
|
|
||
| // [SPARK-39704][SQL] Implement createIndex & dropIndex & indexExists in JDBC (H2 dialect) |
There was a problem hiding this comment.
There was a problem hiding this comment.
they should not be checked by mima... Does mima have a list to mark private APIs?
There was a problem hiding this comment.
Sure? we can add org.apache.spark.sql.jdbc.* as defaultExcludes.
There was a problem hiding this comment.
c2d9f37 add org.apache.spark.sql.jdbc.* as default excludes, is this ok?
project/MimaExcludes.scala
Outdated
| ProblemFilters.exclude[ReversedMissingMethodProblem]("org.apache.spark.sql.catalog.Catalog.setCurrentCatalog"), | ||
| ProblemFilters.exclude[ReversedMissingMethodProblem]("org.apache.spark.sql.catalog.Catalog.listCatalogs"), | ||
|
|
||
| // [SPARK-38929][SQL] Improve error messages for cast failures in ANSI |
There was a problem hiding this comment.
| ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.sql.jdbc.TeradataDialect.dropIndex"), | ||
| ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.sql.jdbc.TeradataDialect.indexExists"), | ||
|
|
||
| // [SPARK-39759][SQL] Implement listIndexes in JDBC (H2 dialect) |
There was a problem hiding this comment.
| ProblemFilters.exclude[IncompatibleMethTypeProblem]("org.apache.spark.sql.jdbc.TeradataDialect.listIndexes"), | ||
|
|
||
| // [SPARK-36511][MINOR][SQL] Remove ColumnIOUtil | ||
| ProblemFilters.exclude[MissingClassProblem]("org.apache.parquet.io.ColumnIOUtil") |
There was a problem hiding this comment.
| // Exclude rules for 3.2.x from 3.1.1 | ||
| lazy val v32excludes = Seq( | ||
| // Defulat exclude rules | ||
| lazy val defaultExcludes = Seq( |
There was a problem hiding this comment.
I keep
// Spark Internals
ProblemFilters.exclude[Problem]("org.apache.spark.rpc.*"),
ProblemFilters.exclude[Problem]("org.spark-project.jetty.*"),
ProblemFilters.exclude[Problem]("org.spark_project.jetty.*"),
ProblemFilters.exclude[Problem]("org.sparkproject.jetty.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.internal.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.unused.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.unsafe.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.memory.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.util.collection.unsafe.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.sql.catalyst.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.sql.execution.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.sql.internal.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.sql.errors.*"),
// DSv2 catalog and expression APIs are unstable yet. We should enable this back.
ProblemFilters.exclude[Problem]("org.apache.spark.sql.connector.catalog.*"),
ProblemFilters.exclude[Problem]("org.apache.spark.sql.connector.expressions.*"),
// Avro source implementation is internal.
ProblemFilters.exclude[Problem]("org.apache.spark.sql.v2.avro.*"),
(problem: Problem) => problem match {
case MissingClassProblem(cls) => !cls.fullName.startsWith("org.sparkproject.jpmml") &&
!cls.fullName.startsWith("org.sparkproject.dmg.pmml")
case _ => true
}
as defaultExcludes, is that right?
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Thank you for all clean-ups, @LuciferYang . It's really meaningful.
project/MimaExcludes.scala
Outdated
|
|
||
| // Exclude rules for 3.3.x from 3.2.0 | ||
| lazy val v33excludes = v32excludes ++ Seq( | ||
| lazy val v33excludes = defaultExcludes ++ Seq( |
There was a problem hiding this comment.
I thought we can remove v33excludes completely except defaultExcludes because it is a different from 3.2.0. Do we need this when we compare with v3.3.0?
There was a problem hiding this comment.
Do you mean val v34excludes = defaultExcludes ++ Seq(...)?
There was a problem hiding this comment.
v33excludes should not be needed
project/MimaExcludes.scala
Outdated
|
|
||
| def excludes(version: String) = version match { | ||
| case v if v.startsWith("3.4") => v34excludes | ||
| case v if v.startsWith("3.3") => v33excludes |
There was a problem hiding this comment.
Shall we remove this line too?
There was a problem hiding this comment.
org.apache.spark.sql.catalog.* also add to default excludes
There was a problem hiding this comment.
I've got the wrong idea
There was a problem hiding this comment.
case v if v.startsWith("3.3") => v33excludes deleted
project/MimaExcludes.scala
Outdated
| ProblemFilters.exclude[Problem]("org.apache.spark.sql.internal.*"), | ||
| ProblemFilters.exclude[Problem]("org.apache.spark.sql.errors.*"), | ||
| // SPARK-40283: add jdbc as default excludes | ||
| ProblemFilters.exclude[Problem]("org.apache.spark.sql.jdbc.*"), |
There was a problem hiding this comment.
We do have developer APIs in this package (e.g. JdbcDialect), but dialect implementations are private (e.g. private object DB2Dialect extends JdbcDialect). I have no idea why mima still checks these dialect implementations...
There was a problem hiding this comment.
I have add org.apache.spark.sql.jdbc.* into default excludes list
There was a problem hiding this comment.
We have developer APIs there so we can't simply exclude the entire package. If we can't figure out how to fix mima (will it help to add @Private for these private classes/objects?), then we have to add exclude rules one by one for each class in org.apache.spark.sql.jdbc
There was a problem hiding this comment.
ignore the class with org.apache.spark.annotation.Private ? The code should be feasible, what do you think about this @dongjoon-hyun
There was a problem hiding this comment.
@cloud-fan Are all XXDialect extends JdbcDialect identified as @Private? Let me test it first
There was a problem hiding this comment.
So we want to skip all private object?
There was a problem hiding this comment.
yea, mima is for checking binary compatibility and why do we care about private APIs?
There was a problem hiding this comment.
Yes, that's reasonable. Let me check why GenerateMIMAIgnore didn't ignore them
There was a problem hiding this comment.
ad543c0 add moduleSymbol.isPrivate condition to directlyPrivateSpark check, then private object will ignore as default.
But we still need explicitly add ProblemFilters.exclude[Problem]("org.apache.spark.sql.jdbc.JdbcDialect.*") due to JdbcDialect is a abstract class now
There was a problem hiding this comment.
And @DeveloperApi(for example JdbcDialect) can not be ignore as default due to #11751
project/MimaExcludes.scala
Outdated
| ProblemFilters.exclude[Problem]("org.apache.spark.sql.internal.*"), | ||
| ProblemFilters.exclude[Problem]("org.apache.spark.sql.errors.*"), | ||
| // SPARK-40283: add jdbc.JdbcDialect as default excludes | ||
| ProblemFilters.exclude[Problem]("org.apache.spark.sql.jdbc.JdbcDialect.*"), |
There was a problem hiding this comment.
JdbcDialect is a developer API and should be tracked. Can we track it explicitly instead of skipping the entire package?
 cloud-fan
left a comment
cloud-fan
left a comment
There was a problem hiding this comment.
looks pretty good now, thanks for working on it!
private object by default and bump MiMa's previousSparkVersion to 3.3.0
private object by default and bump MiMa's previousSparkVersion to 3.3.0private object by default and bump MiMa's previousSparkVersion to 3.3.0
private object by default and bump MiMa's previousSparkVersion to 3.3.0private object and bump MiMa's previousSparkVersion to 3.3.0
private object and bump MiMa's previousSparkVersion to 3.3.0private object and bump previousSparkVersion to 3.3.0
dongjoon-hyun
left a comment
There was a problem hiding this comment.
+1, LGTM. Thank you, @LuciferYang and all!
|
Merged to master for Apache Spark 3.4.0. |
What changes were proposed in this pull request?
The main change of this pr as follows:
private objectby defaultpreviousSparkVersionto 3.3.0ProblemFilterstoMimaExcludesWhy are the changes needed?
To ensure that MiMa checks cover new APIs added in Spark 3.3.0.
Does this PR introduce any user-facing change?
No.
How was this patch tested?
Scala 2.12
Scala 2.13