[SPARK-25207][SQL] Case-insensitve field resolution for filter pushdown when reading Parquet #22197
Conversation
…wn when reading Parquet
|
Test build #95147 has finished for PR 22197 at commit
|
|
Test build #95149 has finished for PR 22197 at commit
|
| // converted (`ParquetFilters.createFilter` returns an `Option`). That's why a `flatMap` | ||
| // is used here. | ||
| .flatMap(parquetFilters.createFilter(parquetSchema, _)) | ||
| .flatMap(parquetFilters.createFilter(parquetSchema, _, isCaseSensitive)) |
There was a problem hiding this comment.
can we pass this config when creating ParquetFilters?
There was a problem hiding this comment.
Yes, that way is better.
|
Test build #95247 has finished for PR 22197 at commit
|
| assertResult(None) { | ||
| caseInsensitiveParquetFilters.createFilter( | ||
| dupParquetSchema, sources.EqualTo("CINT", 1000)) | ||
| } |
There was a problem hiding this comment.
Can we add one negative test that having name names in case insensitive modes, for example, cInt, CINT and check if that throws an exception?
|
|
||
| /** | ||
| * Returns a map from name of the column to the data type, if predicate push down applies. | ||
| * Returns nameMap and typeMap based on different case sensitive mode, if predicate push |
There was a problem hiding this comment.
instead of returning 2 maps, can we just add a originalName field to ParquetSchemaType?
There was a problem hiding this comment.
+1 for avoiding returning 2maps if possible.
|
@cloud-fan @HyukjinKwon Seem cannot simply add Because we need exact ParquetSchemaType info for type match, like: I use a new case class Let me know if you are OK with this way. |
|
Test build #95253 has finished for PR 22197 at commit
|
| } else { | ||
| // Don't consider ambiguity here, i.e. more than one field is matched in case insensitive | ||
| // mode, just skip pushdown for these fields, they will trigger Exception when reading, | ||
| // See: SPARK-25132. |
There was a problem hiding this comment.
If we don't need to consider ambiguity, can't we just lowercase f.getName above instead of doing dedup here?
There was a problem hiding this comment.
It is a good question!
Let's see the scenario like below:
- parquet file has duplicate fields "a INT, A INT".
- user wants to pushdown "A > 0".
Without dedup, we possible pushdown "a > 0" instead of "A > 0",
although it is wrong, it will still trigger the Exception finally when reading parquet,
so whether dedup or not, we will get the same result.
@cloud-fan , @gatorsmile any idea?
There was a problem hiding this comment.
can we do the dedup before parquet filter pushdown and parquet column pruning? Then we can simplify the code in both cases.
There was a problem hiding this comment.
@cloud-fan, it is a great idea, thanks!
I think it is not to "dedup" before pushdown and pruning.
Maybe we should do parquet schema clip before pushdown and pruning.
If duplicated fields are detected, throw the exception.
If not, pass clipped parquet schema via hadoopconf to parquet lib.
catalystRequestedSchema = {
val conf = context.getConfiguration
val schemaString = conf.get(ParquetReadSupport.SPARK_ROW_REQUESTED_SCHEMA)
assert(schemaString != null, "Parquet requested schema not set.")
StructType.fromString(schemaString)
}
val caseSensitive = context.getConfiguration.getBoolean(SQLConf.CASE_SENSITIVE.key,
SQLConf.CASE_SENSITIVE.defaultValue.get)
val parquetRequestedSchema = ParquetReadSupport.clipParquetSchema(
context.getFileSchema, catalystRequestedSchema, caseSensitive)
I am trying this way, will update soon.
| val caseInsensitiveParquetFilters = | ||
| new ParquetFilters(conf.parquetFilterPushDownDate, conf.parquetFilterPushDownTimestamp, | ||
| conf.parquetFilterPushDownDecimal, conf.parquetFilterPushDownStringStartWith, | ||
| conf.parquetFilterPushDownInFilterThreshold, caseSensitive = false) |
There was a problem hiding this comment.
nit: add a method like:
def createParquetFilter(caseSensitive: Boolean) = {
new ParquetFilters(conf.parquetFilterPushDownDate, conf.parquetFilterPushDownTimestamp,
conf.parquetFilterPushDownDecimal, conf.parquetFilterPushDownStringStartWith,
conf.parquetFilterPushDownInFilterThreshold, caseSensitive = caseSensitive)
}| testCaseInsensitiveResolution( | ||
| schema, | ||
| FilterApi.gtEq(intColumn("cint"), 1000: Integer), | ||
| sources.GreaterThanOrEqual("CINT", 1000)) |
There was a problem hiding this comment.
nit: maybe we don't need to test against so many predicate. We just want to make sure case insensitive resolution work.
There was a problem hiding this comment.
Each test is corresponding to one line code change in createFilter. Like:
case sources.IsNull(name) if canMakeFilterOn(name, null) =>
makeEq.lift(fieldMap(name).schema).map(_(fieldMap(name).name, null))
All tests together can cover all my change in createFilter.
| } | ||
|
|
||
| test("SPARK-25207: Case-insensitive field resolution for pushdown when reading parquet" + | ||
| " - exception when duplicate fields in case-insensitive mode") { |
There was a problem hiding this comment.
nit: We can have just exception when duplicate fields in case-insensitive mode as test title. Original one is too verbose.
| caseSensitive: Boolean) { | ||
|
|
||
| private case class ParquetField( | ||
| name: String, |
There was a problem hiding this comment.
resolvedName? This name and the name in schema looks confused in following code.
|
@dongjoon-hyun Do you think we face the same issue in ORC? |
| */ | ||
| def createFilter(schema: MessageType, predicate: sources.Filter): Option[FilterPredicate] = { | ||
| val nameToType = getFieldMap(schema) | ||
| val nameToParquet = getFieldMap(schema) |
|
This PR is basically trying to resolve case sensitivity when the logical schema and physical schema do not match. This sounds like a general issue in all the data sources. Could any of you do us a favor? Check whether all the built-in data sources respect the conf |
| pushDownInFilterThreshold: Int, | ||
| caseSensitive: Boolean) { | ||
|
|
||
| private case class ParquetField( |
There was a problem hiding this comment.
Add a description about these two fields? It is confusing what is resolvedName for the future code maintainer.
|
@gatorsmile I can help check |
|
Test build #95256 has finished for PR 22197 at commit
|
|
Test build #95258 has finished for PR 22197 at commit
|
|
Test build #95257 has finished for PR 22197 at commit
|
|
retest this please |
|
Test build #95264 has finished for PR 22197 at commit
|
|
Thanks, @yucai . Could you rebase your code to According to your example, this issue is a general regression introduced at Spark 2.4. It's not specific to schema mismatch case. For example, in the following schema matched case, the input size is less than or equal to
Also, if you don't mind, could you update the PR description? This PR doesn't generate new filters here. This only changes |

| } | ||
|
|
||
| test("SPARK-25207: exception when duplicate fields in case-insensitive mode") { | ||
| withTempDir { dir => |
|
@gatorsmile . I don't think so we have this regression on ORC data source. |
|
@dongjoon-hyun In the schema matched case as you listed, it is expected behavior in current master. This difference is probably introduced by #21573, @cloud-fan, current master read more data than 2.3 for top limit like in #22197 (comment) , is it a regression or not? Master: 2.3 branch: |
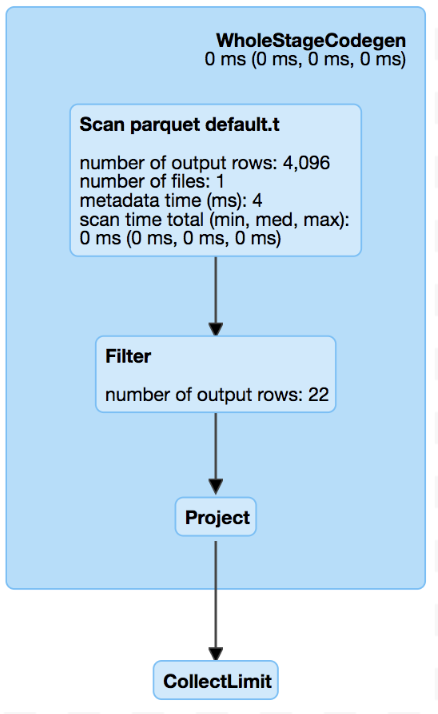
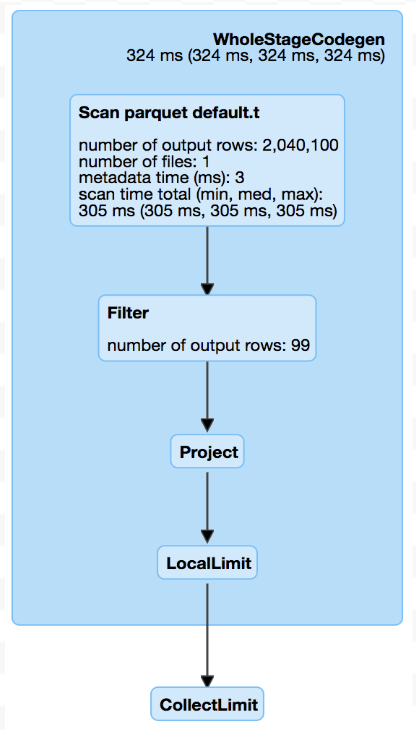
|
apparently not... OK let's just check duplicated filed names twice: one in filter pushdown, one in column pruning. And clean it up in followup PRs. |
|
@dongjoon-hyun Sorry for the late response, description is changed to:
Let me know if you have any suggestion :). |
|
@cloud-fan I reverted to the previous version. |
|
Test build #95454 has finished for PR 22197 at commit
|
|
Test build #95449 has finished for PR 22197 at commit
|
|
retest this please |
|
|
||
| withSQLConf(SQLConf.CASE_SENSITIVE.key -> "false") { | ||
| val e = intercept[SparkException] { | ||
| sql(s"select a from $tableName where b > 0").collect() |
There was a problem hiding this comment.
can we read this table with case-sensitive mode?
There was a problem hiding this comment.
Yes, we can, see below.
val tableName = "test"
val tableDir = "/tmp/data"
spark.conf.set("spark.sql.caseSensitive", true)
spark.range(10).selectExpr("id as A", "2 * id as B", "3 * id as b").write.mode("overwrite").parquet(tableDir)
sql(s"DROP TABLE $tableName")
sql(s"CREATE TABLE $tableName (A LONG, B LONG) USING PARQUET LOCATION '$tableDir'")
scala> sql("select A from test where B > 0").show
+---+
| A|
+---+
| 7|
| 8|
| 9|
| 2|
| 3|
| 4|
| 5|
| 6|
| 1|
+---+
Let me add one test case.
There was a problem hiding this comment.
nit: to be consistent with the following query, I'd make this query as select A from $tableName where B > 0 too.
|
Test build #95455 has finished for PR 22197 at commit
|
|
Test build #95456 has finished for PR 22197 at commit
|
|
retest this please |
|
LGTM |
|
Test build #95462 has finished for PR 22197 at commit
|
|
@cloud-fan, tests have passed. And I will use a followup PR to make it cleaner. |
| caseSensitive: Boolean) { | ||
|
|
||
| private case class ParquetField( | ||
| // field name in parquet file |
There was a problem hiding this comment.
I'd just move those into the doc for this case class above, for instance,
/**
* blabla
* @param blabla
*/
private case class ParquetField
|
Seems fine to me too. |
|
Test build #95517 has finished for PR 22197 at commit
|
|
retest this please |
|
One minor comment that can be addressed in a follow-up PR. LGTM. |
|
Test build #95524 has finished for PR 22197 at commit
|
|
thanks, merging to master! |
What changes were proposed in this pull request?
Currently, filter pushdown will not work if Parquet schema and Hive metastore schema are in different letter cases even spark.sql.caseSensitive is false.
Like the below case:
Although filter "ID < 100L" is generated by Spark, it fails to pushdown into parquet actually, Spark still does the full table scan when reading.
This PR provides a case-insensitive field resolution to make it work.
Before - "ID < 100L" fail to pushedown:


After - "ID < 100L" pushedown sucessfully:
How was this patch tested?
Added UTs.