[SPARK-42698][CORE] SparkSubmit should also stop SparkContext when exit program in yarn mode and pass exitCode to AM side #40314
Conversation
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Do you think you can add a test case, @AngersZhuuuu ?
| !isConnectServer(args.mainClass)) { | ||
| try { | ||
| SparkContext.getActive.foreach(_.stop()) | ||
| SparkContext.getActive.foreach(_.stop(exitCode)) |
There was a problem hiding this comment.
I don't think this is related to YARN AM because this is guarded by if (args.master.startsWith("k8s"). Is this K8s patch instead of YARN AM?
There was a problem hiding this comment.
I don't know too much about K8S scheduler, but for yarn client mode we also need to keep a same exit code.
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Hi, @AngersZhuuuu .
This PR seems to have insufficient information. Could you provide more details about how to validate this in what environment?
We run a client mode SparkSubmit job and throw below exception This job failed, but with call So here for normal job, I think we should pass the exit code to SchedulerBackend, right? Then after your mention, I see that #33403 change the behavior that only k8s call After this pr, we also need to check if k8s backend exit code is same as client side in client mode too. |
|
Does YARN still have this issue with Spark 3.4? |
|
cc @mridulm and @tgravescs , too |
Didn't see such fix in current code. |
|
This seems to be a revert of #33403 as now we stop SparkContext in YARN environment as well. We should justify it in the PR description. This is not simply passing the exitCode. Please update the PR title as well. |
DOne |
|
@dongjoon-hyun do you have more context about #33403? Why do we limit the stopping spark context behavior to k8s only? |
|
Failed UT should not related to this pr. |
|
@cloud-fan Seems this code #32283 first want to fix issue in k8s, then @dongjoon-hyun make it limit in k8s env. But this also can work for yarn env.... |
|
To @cloud-fan and all. Here is the full context.
Three months later after merging the second commit, there was a post-commit review. Since SPARK-34674 was released already to Spark 3.1.2, according to the post-commit comment, I made a new JIRA, SPARK-36193 (#33403) which was released as 3.1.3.
|
|
@AngersZhuuuu can you comment on the original discussion thread and convince related people to add back |
TBH, you can think it as a new feature, since they first just want to only support k8s, and this pr support yarn too |
|
I believe people in that discussion thread have the most context (some of them are committers) and I'm not comfortable merging it without them taking a look. |
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
What changes were proposed in this pull request?
Currently when we run yarn-client mode in SparkSubmit, when we catch exceptions during
runMain()Spark won't call
SparkContext.stop()since pr #33403 remove the behavior.Then AM side will mark the application as SUCCESS.
In this pr, we will revert the behavior of #33403 then YARN mode, it will call
sc.stop()in YARN env, and also, the client side will pass the correct exit code to the YARN AM side.This pr fixes this issue.
Why are the changes needed?
Keep the same exit code between the client and AM
Does this PR introduce any user-facing change?
No
How was this patch tested?
Mannul tested
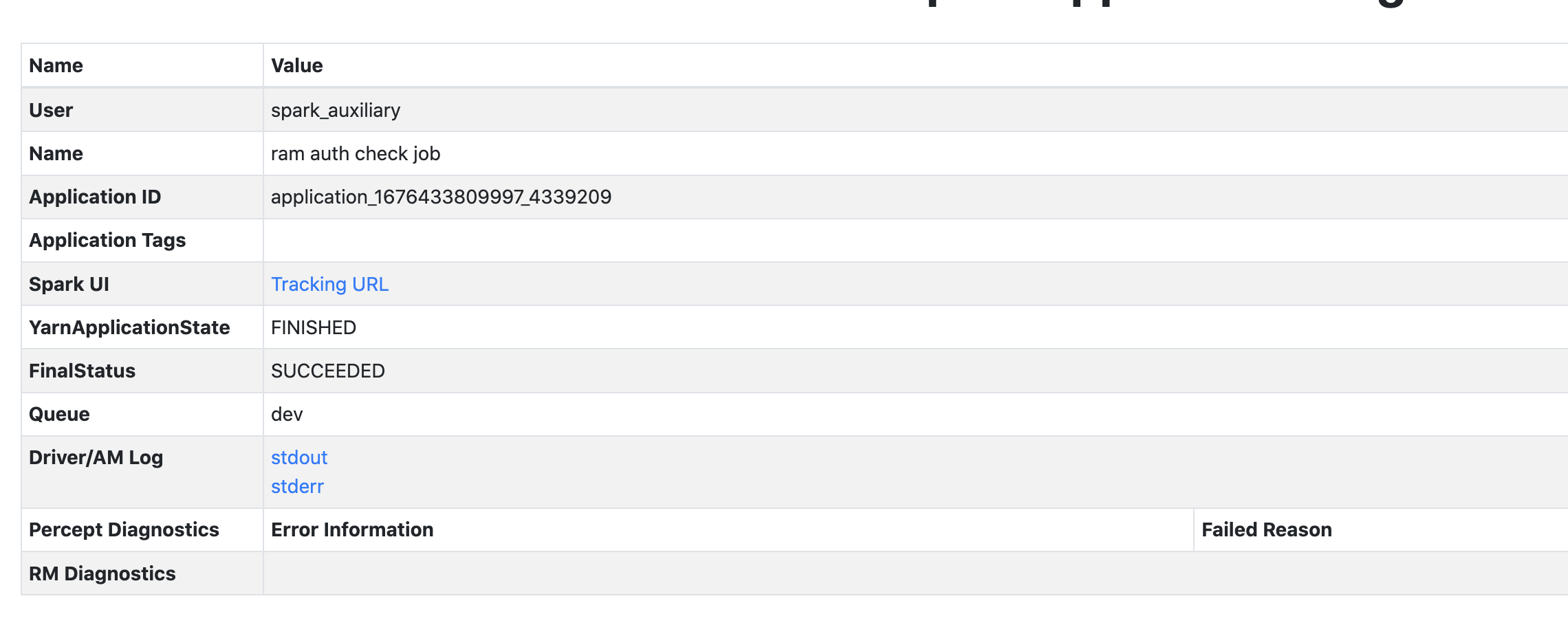
The screenshot is our internal platform to show each app's status, the application status information is from YARN rm and timeline service.
Before change
After change