[SPARK-42157][CORE] spark.scheduler.mode=FAIR should provide FAIR scheduler
#39703
Conversation
spark.scheduler.mode=FAIR should provide FAIR scheduler
| --> | ||
|
|
||
| <allocations> | ||
| <pool name="default"> |
There was a problem hiding this comment.
| <allocations> | ||
| <pool name="default"> | ||
| <schedulingMode>FAIR</schedulingMode> | ||
| <weight>1</weight> |
There was a problem hiding this comment.
| <pool name="default"> | ||
| <schedulingMode>FAIR</schedulingMode> | ||
| <weight>1</weight> | ||
| <minShare>0</minShare> |
There was a problem hiding this comment.
|
|
||
| val schedulerAllocFile = sc.conf.get(SCHEDULER_ALLOCATION_FILE) | ||
| val DEFAULT_SCHEDULER_FILE = "fairscheduler.xml" | ||
| val DEFAULT_SCHEDULER_TEMPLATE_FILE = "fairscheduler-default.xml.template" |
There was a problem hiding this comment.
To avoid any conflicts in the existing production jobs, this PR provide and use new file as .xml.template.
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Could you review this, @mridulm ? This bug was hidden and difficult to test in the unit test environment because we have fairscheduler.xml test resource.
https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml
| <weight>1</weight> | ||
| <minShare>0</minShare> | ||
| </pool> | ||
| </allocations> |
There was a problem hiding this comment.
There is a conf/fairscheduler.xml.template - why do we need this ?
If it is for testing, move it as a resource there instead of in conf ?
There was a problem hiding this comment.
This is not for testing, @mridulm . As mentioned in #39703 (review), we already have a testing resource, fairscheduler.xml, not a template.
In addition, the content of conf/fairscheduler.xml.template is not matched with the expected default behavior.
| s"FIFO order. To use fair scheduling, configure pools in $DEFAULT_SCHEDULER_FILE " + | ||
| s"or set ${SCHEDULER_ALLOCATION_FILE.key} to a file that contains the configuration.") | ||
| None | ||
| } |
There was a problem hiding this comment.
We should not be relying on template file - in deployments, template file can be invalid - admin's are not expecting it to be read by spark.
Instead, why not simply rely on returning None here ?
Note - if this is only for testing, we can special case it that way via spark.testing
There was a problem hiding this comment.
First of all, this is not a testing issue. As I wrote in the PR description, our documentation is wrong. It says spark.scheduler.mode=FAIR will return a FAIR scheduler. However, we are getting FIFO scheduler now.
Note - if this is only for testing, we can special case it that way via spark.testing
None is the previous behavior which ends up with FIFO scheduler with the WARNING message, 23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration file not found so jobs will be scheduled in FIFO order. To use fair scheduling, configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to a file that contains the configuration.
Instead, why not simply rely on returning None here ?
Got it. I understand your point about the template file. The reason why I tried to use template file is that I cannot put the real fairscheduler.xml file because it can be used already in the production.
We should not be relying on template file - in deployments, template file can be invalid - admin's are not expecting it to be read by spark.
|
Looks like I misunderstood the PR, I see what you mean @dongjoon-hyun. +CC @tgravescs, @Ngone51 in case you have thoughts. |
|
No problem. I totally understand your concern on the usage of template file. I'll also think about a new way. Thank you for your thoughtful review, @mridulm . |
|
I haven't used FAIR Scheduler much, but was wondering can we just have the defaults be in the code vs having to read a separate template file? ie if no file |
|
Thank you, @tgravescs . Yes, I agree with you to have the defaults in the code. |
|
I address the comments. Could you review this once more, @mridulm and @tgravescs ? |
|
All tests passed. |

|
Could you review this, @Ngone51 ? |
core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
Outdated
Show resolved
Hide resolved
 mridulm
left a comment
mridulm
left a comment
There was a problem hiding this comment.
Looks good to me, I was essentially toying with the same idea Tom had - but wanted to explore alternatives.
Unfortunately, could not come up with anything better
…der.scala Co-authored-by: Mridul Muralidharan <[email protected]>
|
Thank you, @mridulm ! |
…cheduler ### What changes were proposed in this pull request? Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR Scheduling Within an Application`. https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application  This bug is hidden in our CI because we have `fairscheduler.xml` always as one of test resources. - https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml ### Why are the changes needed? Currently, when `spark.scheduler.mode=FAIR` is given without scheduler allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler which is wrong. We need to switch the mode to `FAIR` from `FIFO`. **BEFORE** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration file not found so jobs will be scheduled in FIFO order. To use fair scheduling, configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to a file that contains the configuration. Spark context Web UI available at http://localhost:4040 ``` 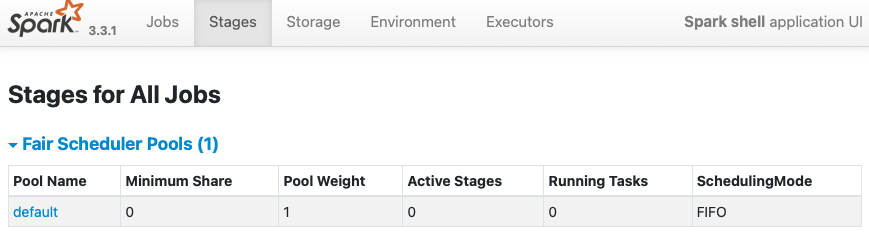 **AFTER** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://localhost:4040 ``` 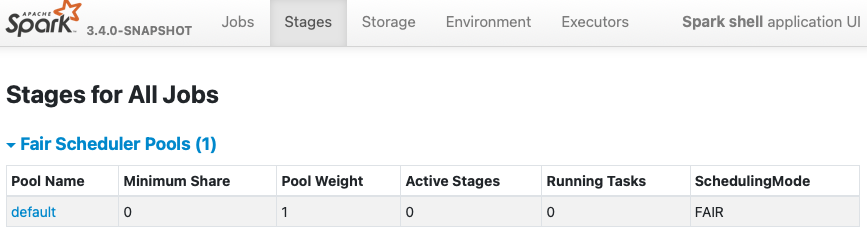 ### Does this PR introduce _any_ user-facing change? Yes, but this is a bug fix to match with Apache Spark official documentation. ### How was this patch tested? Pass the CIs. Closes #39703 from dongjoon-hyun/SPARK-42157. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit 4d51bfa) Signed-off-by: Dongjoon Hyun <[email protected]>
{kind=link}
{kind=link}
{kind=link}
…cheduler ### What changes were proposed in this pull request? Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR Scheduling Within an Application`. https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application  This bug is hidden in our CI because we have `fairscheduler.xml` always as one of test resources. - https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml ### Why are the changes needed? Currently, when `spark.scheduler.mode=FAIR` is given without scheduler allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler which is wrong. We need to switch the mode to `FAIR` from `FIFO`. **BEFORE** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration file not found so jobs will be scheduled in FIFO order. To use fair scheduling, configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to a file that contains the configuration. Spark context Web UI available at http://localhost:4040 ```  **AFTER** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://localhost:4040 ```  ### Does this PR introduce _any_ user-facing change? Yes, but this is a bug fix to match with Apache Spark official documentation. ### How was this patch tested? Pass the CIs. Closes #39703 from dongjoon-hyun/SPARK-42157. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit 4d51bfa) Signed-off-by: Dongjoon Hyun <[email protected]>
|
Merged to master/3.3/3.2. |
|
Thank you again, @mridulm and @tgravescs . |
|
cc @kazuyukitanimura since this lands at branch-3.2 |
…cheduler ### What changes were proposed in this pull request? Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR Scheduling Within an Application`. https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application  This bug is hidden in our CI because we have `fairscheduler.xml` always as one of test resources. - https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml ### Why are the changes needed? Currently, when `spark.scheduler.mode=FAIR` is given without scheduler allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler which is wrong. We need to switch the mode to `FAIR` from `FIFO`. **BEFORE** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration file not found so jobs will be scheduled in FIFO order. To use fair scheduling, configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to a file that contains the configuration. Spark context Web UI available at http://localhost:4040 ```  **AFTER** ``` $ bin/spark-shell -c spark.scheduler.mode=FAIR Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://localhost:4040 ```  ### Does this PR introduce _any_ user-facing change? Yes, but this is a bug fix to match with Apache Spark official documentation. ### How was this patch tested? Pass the CIs. Closes apache#39703 from dongjoon-hyun/SPARK-42157. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit 4d51bfa) Signed-off-by: Dongjoon Hyun <[email protected]>
What changes were proposed in this pull request?
Like our documentation,
spark.sheduler.mode=FAIRshould provide aFAIR Scheduling Within an Application.https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application
This bug is hidden in our CI because we have
fairscheduler.xmlalways as one of test resources.Why are the changes needed?
Currently, when
spark.scheduler.mode=FAIRis given without scheduler allocation file, Spark createsFair Scheduler PoolswithFIFOscheduler which is wrong. We need to switch the mode toFAIRfromFIFO.BEFORE
AFTER
Does this PR introduce any user-facing change?
Yes, but this is a bug fix to match with Apache Spark official documentation.
How was this patch tested?
Pass the CIs.