[SPARK-41752][SQL][UI] Group nested executions under the root execution #39268
Conversation
There was a problem hiding this comment.
executionIdToSubExecutions(e.rootExecutionId) += e
|
also cc @ulysses-you |
sql/core/src/main/scala/org/apache/spark/sql/execution/SQLExecution.scala
Outdated
Show resolved
Hide resolved
|
The test failed at python linter. should be caused by some "connect" PRs. |
|
@zhengruifeng @HyukjinKwon are you aware of anything about this python failure? |
|
@cloud-fan I can not repro this fail in my local env the latest mypy check in master also succeed. https://github.com/apache/spark/actions/runs/3804744443/jobs/6472202104 |
|
@linhongliu-db can you rebase your branch and try again? |
There was a problem hiding this comment.
This PR introduces 4 config namespace groups like the following. Shall we simplify the config namespace?
spark.ui.sql.*
spark.ui.sql.group.*
spark.ui.sql.group.sub.*
spark.ui.sql.group.sub.execution.*
There was a problem hiding this comment.
changed to spark.ui.sql.groupSubExecutionEnabled but I'm glad to take any other naming suggestions. :)
There was a problem hiding this comment.
Do we have any other usage for this methods, setRootExecutionId and unsetRootExecutionId? These methods seem to be used once.
There was a problem hiding this comment.
yes, it's only used once. I personally think that using a function can better explain the logic since it's not a no-brainer.
There was a problem hiding this comment.
Just a question. Do we have a test coverage for only Spark event logs to validate this code path?
There was a problem hiding this comment.
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
Outdated
Show resolved
Hide resolved
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
This <tr> doesn't need additional indentation here. Could you align the indentation with the previous <tr> at line 389?
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
Outdated
Show resolved
Hide resolved
|
working on the comments |
c4b1583 to
4d3c15a
Compare
| /** | ||
| * Unset the "root" SQL Execution Id once the "root" SQL execution completes. | ||
| */ | ||
| private def unsetRootExecutionId(sc: SparkContext, executionId: String): Unit = { |
There was a problem hiding this comment.
This method is also misleading because we set EXECUTION_ROOT_ID_KEY to null only when it's equal to executionId.
There was a problem hiding this comment.
after a second thought, this function wrapper is misleading and doesn't make things clear. So I inlined it to the main function. Thanks for the suggestion.
| } finally { | ||
| executionIdToQueryExecution.remove(executionId) | ||
| sc.setLocalProperty(EXECUTION_ID_KEY, oldExecutionId) | ||
| unsetRootExecutionId(sc, executionId.toString) |
There was a problem hiding this comment.
If we need to define a new method, shall we define it to accept Long directly?
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
Thank you for updates, @linhongliu-db . I have only minor comments.
cc @gengliangwang , too
| case class SparkListenerSQLExecutionStart( | ||
| executionId: Long, | ||
| // if the execution is a root, then rootExecutionId == executionId | ||
| rootExecutionId: Long, |
There was a problem hiding this comment.
We need to refactor the code change in https://github.com/apache/spark/blob/master/core/src/main/protobuf/org/apache/spark/status/protobuf/store_types.proto#L387
|
|
||
| new SQLExecutionUIData( | ||
| executionId = ui.getExecutionId, | ||
| rootExecutionId = ui.getExecutionId, |
There was a problem hiding this comment.
This should be ui.getRootExecutionId after updating the protobuf definition.
|
|
||
| new SQLExecutionUIData( | ||
| executionId = 0, | ||
| rootExecutionId = 0, |
There was a problem hiding this comment.
For testing purpose, let's use a different value from executionId
|
Could you update your PR, @linhongliu-db ? We have Apache Spark 3.4 Feature Freeze schedule. Also, cc @xinrong-meng as Apache Spark 3.4. release manager. |
|
@dongjoon-hyun working on it |
|
The failed |
|
Thank you, @linhongliu-db and @cloud-fan . |
|
Thank you everyone for reviewing this! |
…nUIData ### What changes were proposed in this pull request? The new field `rootExecutionId` of `SQLExecutionUIData` is not correctly serialized/deserialized in #39268. This PR is to fix it. ### Why are the changes needed? Bug fix ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #39489 from gengliangwang/SPARK-41752. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Gengliang Wang <[email protected]>
… execution ### What changes were proposed in this pull request? #39268 / [SPARK-41752](https://issues.apache.org/jira/browse/SPARK-41752) added a new non-optional `rootExecutionId: Long` field to the SparkListenerSQLExecutionStart case class. When JsonProtocol deserializes this event it uses the "ignore missing properties" Jackson deserialization option, causing the rootExecutionField to be initialized with a default value of 0. The value 0 is a legitimate execution ID, so in the deserialized event we have no ability to distinguish between the absence of a value and a case where all queries have the first query as the root. Thanks JoshRosen for reporting and investigating this issue. ### Why are the changes needed? Bug fix ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #40403 from linhongliu-db/fix-nested-execution. Authored-by: Linhong Liu <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
… execution ### What changes were proposed in this pull request? #39268 / [SPARK-41752](https://issues.apache.org/jira/browse/SPARK-41752) added a new non-optional `rootExecutionId: Long` field to the SparkListenerSQLExecutionStart case class. When JsonProtocol deserializes this event it uses the "ignore missing properties" Jackson deserialization option, causing the rootExecutionField to be initialized with a default value of 0. The value 0 is a legitimate execution ID, so in the deserialized event we have no ability to distinguish between the absence of a value and a case where all queries have the first query as the root. Thanks JoshRosen for reporting and investigating this issue. ### Why are the changes needed? Bug fix ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #40403 from linhongliu-db/fix-nested-execution. Authored-by: Linhong Liu <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit 4db8e7b) Signed-off-by: Dongjoon Hyun <[email protected]>
… execution ### What changes were proposed in this pull request? apache/spark#39268 / [SPARK-41752](https://issues.apache.org/jira/browse/SPARK-41752) added a new non-optional `rootExecutionId: Long` field to the SparkListenerSQLExecutionStart case class. When JsonProtocol deserializes this event it uses the "ignore missing properties" Jackson deserialization option, causing the rootExecutionField to be initialized with a default value of 0. The value 0 is a legitimate execution ID, so in the deserialized event we have no ability to distinguish between the absence of a value and a case where all queries have the first query as the root. Thanks JoshRosen for reporting and investigating this issue. ### Why are the changes needed? Bug fix ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes #40403 from linhongliu-db/fix-nested-execution. Authored-by: Linhong Liu <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
… execution ### What changes were proposed in this pull request? apache#39268 / [SPARK-41752](https://issues.apache.org/jira/browse/SPARK-41752) added a new non-optional `rootExecutionId: Long` field to the SparkListenerSQLExecutionStart case class. When JsonProtocol deserializes this event it uses the "ignore missing properties" Jackson deserialization option, causing the rootExecutionField to be initialized with a default value of 0. The value 0 is a legitimate execution ID, so in the deserialized event we have no ability to distinguish between the absence of a value and a case where all queries have the first query as the root. Thanks JoshRosen for reporting and investigating this issue. ### Why are the changes needed? Bug fix ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? UT Closes apache#40403 from linhongliu-db/fix-nested-execution. Authored-by: Linhong Liu <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit 4db8e7b) Signed-off-by: Dongjoon Hyun <[email protected]>
|
@linhongliu-db It seems this patch makes CTAS missing the child info on UI: https://issues.apache.org/jira/browse/SPARK-44213 |
What changes were proposed in this pull request?
This PR proposes to group all sub-executions together in SQL UI if they belong to the same root execution.
This feature is controlled by conf
spark.ui.sql.groupSubExecutionEnabledand the default value is set totrueWe can have some follow-up improvements after this PR:
Why are the changes needed?
better user experience.
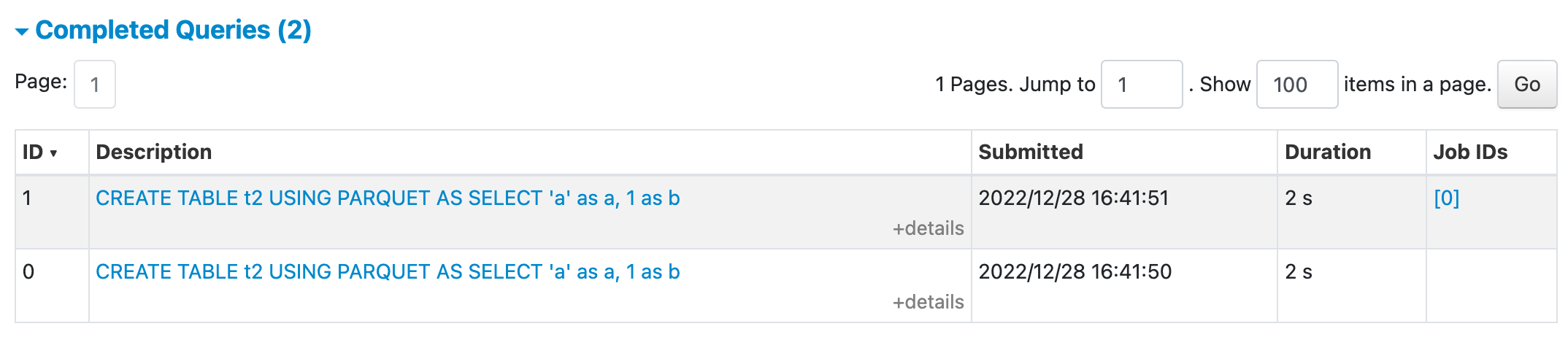
In PR #39220, the CTAS query will trigger a sub-execution to perform the data insertion. But the current UI will display the two executions separately which may confuse the users.
In addition, this change should also help the structured streaming cases
Does this PR introduce any user-facing change?
Yes, the screenshot of the UI change is shown below
SQL Query:
UI before this PR
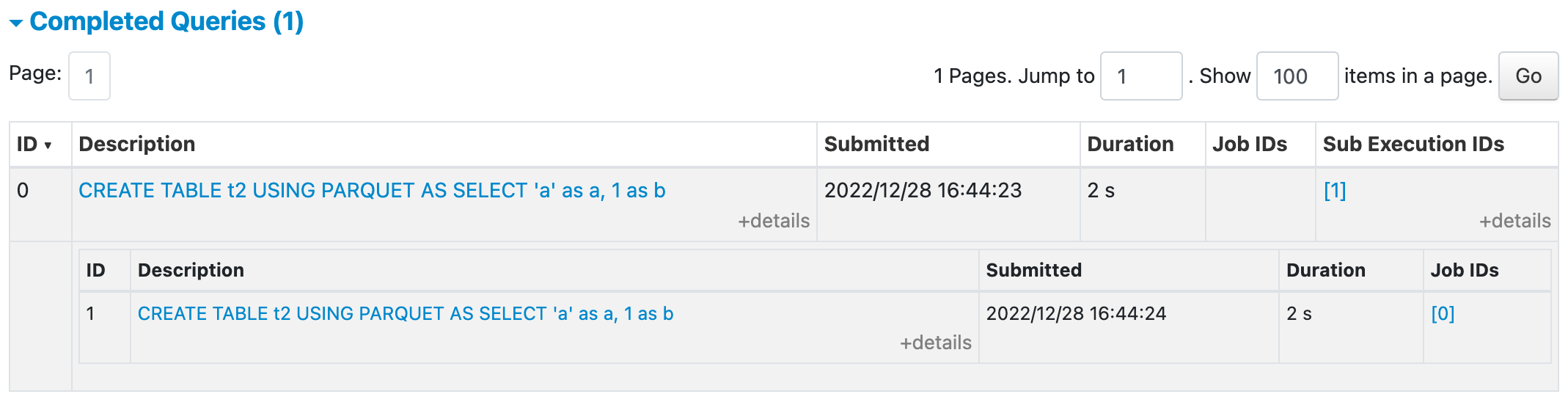
UI after this PR with sub executions collapsed

UI after this PR with sub execution expanded
How was this patch tested?
UT