[SPARK-21646][SQL] Add new type coercion to compatible with Hive #18853
Conversation
|
Test build #80286 has finished for PR 18853 at commit
|
|
How about casting the |
|
Casting the |
|
retest this please |
|
Test build #80339 has finished for PR 18853 at commit
|
| p.makeCopy(Array(left, Cast(right, TimestampType))) | ||
|
|
||
| case p @ BinaryComparison(left, right) | ||
| if left.isInstanceOf[AttributeReference] && right.isInstanceOf[Literal] => |
There was a problem hiding this comment.
We need to cover all the same cases, but it seems this fix couldn't do, for example;
scala> spark.udf.register("testUdf", () => "85908509832958239058032")
scala> sql("select * from values (1) where testUdf() > 1").explain
== Physical Plan ==
*Filter (cast(UDF:testUdf() as int) > 1)
+- LocalTableScan [col1#104]
|
Thanks @maropu, There are some problems: So |
|
If we change this behaviour, I think we better modify code in As another option, we could cast |
|
Currently, the type casting has a few issues when types are different. So far, we do not have any good option to resolve all the issues. Thus, we are hesitant to introduce any behavior change unless this is well defined. Could you do a research to see how the others behave? Any rule? |
# Conflicts: # sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
|
Test build #81606 has finished for PR 18853 at commit
|
|
Test build #81605 has finished for PR 18853 at commit
|
| test("SPARK-17913: compare long and string type column may return confusing result") { | ||
| val df = Seq(123L -> "123", 19157170390056973L -> "19157170390056971").toDF("i", "j") | ||
| checkAnswer(df.select($"i" === $"j"), Row(true) :: Row(false) :: Nil) | ||
| checkAnswer(df.select($"i" === $"j"), Row(true) :: Row(true) :: Nil) |
There was a problem hiding this comment.
To compatible with Hive, MySQL and Oracle:
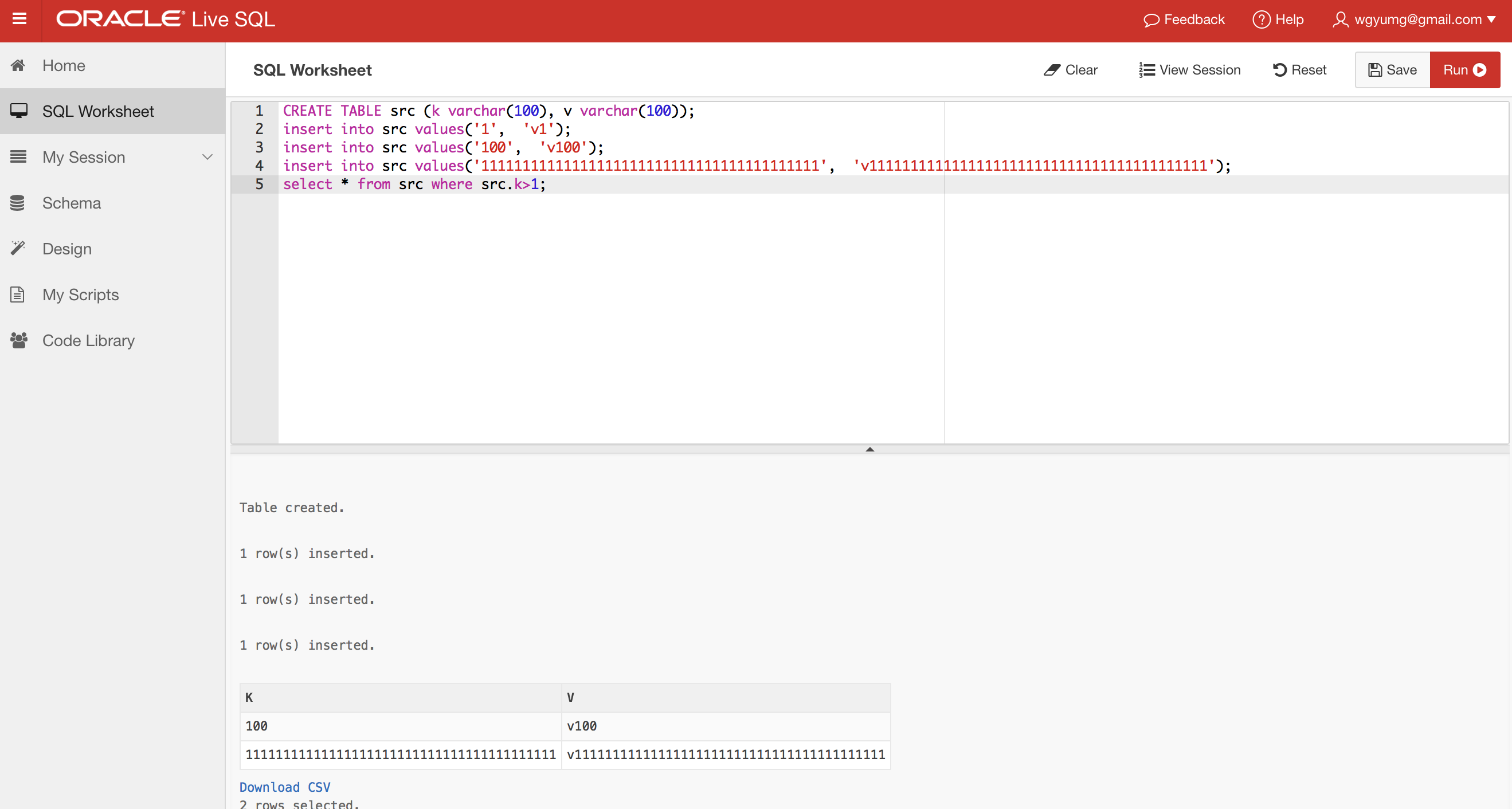
|
Test build #81613 has finished for PR 18853 at commit
|
|
Test build #81638 has finished for PR 18853 at commit
|
|
I provide 2 SQL scripts to validate the different result between Spark and Hive:
|
|
Thank you for your investigation! I think we need to introduce a type inference conf for it. To avoid impacting the existing Spark users, we should keep the existing behaviors, by default. |
|
Test build #81871 has finished for PR 18853 at commit
|
|
retest this please. |
|
Test build #81876 has finished for PR 18853 at commit
|
| buildConf("spark.sql.binary.comparison.compatible.with.hive") | ||
| .doc("Whether compatible with Hive when binary comparison.") | ||
| .booleanConf | ||
| .createWithDefault(true) |
| .createWithDefault(10000) | ||
|
|
||
| val BINARY_COMPARISON_COMPATIBLE_WITH_HIVE = | ||
| buildConf("spark.sql.binary.comparison.compatible.with.hive") |
There was a problem hiding this comment.
-> spark.sql.autoTypeCastingCompatibility
|
Test build #84516 has finished for PR 18853 at commit
|
|
Test build #84519 has finished for PR 18853 at commit
|
docs/sql-programming-guide.md
Outdated
| The <code>default</code> type coercion mode was used in spark prior to 2.3.0, and so it | ||
| continues to be the default to avoid breaking behavior. However, it has logical | ||
| inconsistencies. The <code>hive</code> mode is preferred for most new applications, though | ||
| it may require additional manual casting. |
There was a problem hiding this comment.
Since Spark 2.3, the <code>hive</code> mode is introduced for Hive compatiblity. Spark SQL has its native type cocersion mode, which is enabled by default.
| "and so it continues to be the default to avoid breaking behavior. " + | ||
| "However, it has logical inconsistencies. " + | ||
| "The 'hive' mode is preferred for most new applications, " + | ||
| "though it may require additional manual casting.") |
| } else { | ||
| commonTypeCoercionRules :+ | ||
| InConversion :+ | ||
| PromoteStrings |
There was a problem hiding this comment.
Rename them to NativeInConversion and NativePromoteStrings
| val findCommonTypeToCompatibleWithHive: (DataType, DataType) => Option[DataType] = { | ||
| // Follow hive's binary comparison action: | ||
| // https://github.com/apache/hive/blob/rel/storage-release-2.4.0/ql/src/java/ | ||
| // org/apache/hadoop/hive/ql/exec/FunctionRegistry.java#L781 |
There was a problem hiding this comment.
I saw the change history of this file. It sounds like Hive's type coercion rules are also evolving.
|
Could you please do it? This must take a lot of efforts, but it really helps us to find all the holes. Appreciate it! |
|
Let me open an umbrella JIRA for tracking it. We can do it for both native and Hive compatibility mode. |
|
The JIRA https://issues.apache.org/jira/browse/SPARK-22722 was just opened. I will create an example and open many sub-tasks. Feel free to take them if you have bandwidth. |
|
cc @wangyum |
# Conflicts: # sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala # sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala
|
Test build #85840 has finished for PR 18853 at commit
|
|
Test build #85841 has finished for PR 18853 at commit
|
|
retest this please |
|
Test build #85846 has finished for PR 18853 at commit
|
|
Test build #85849 has finished for PR 18853 at commit
|
# Conflicts: # sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala # sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercionSuite.scala
|
Test build #88778 has finished for PR 18853 at commit
|
|
retest this please |
|
Test build #88780 has finished for PR 18853 at commit
|
|
Spark vs Teradata:
|
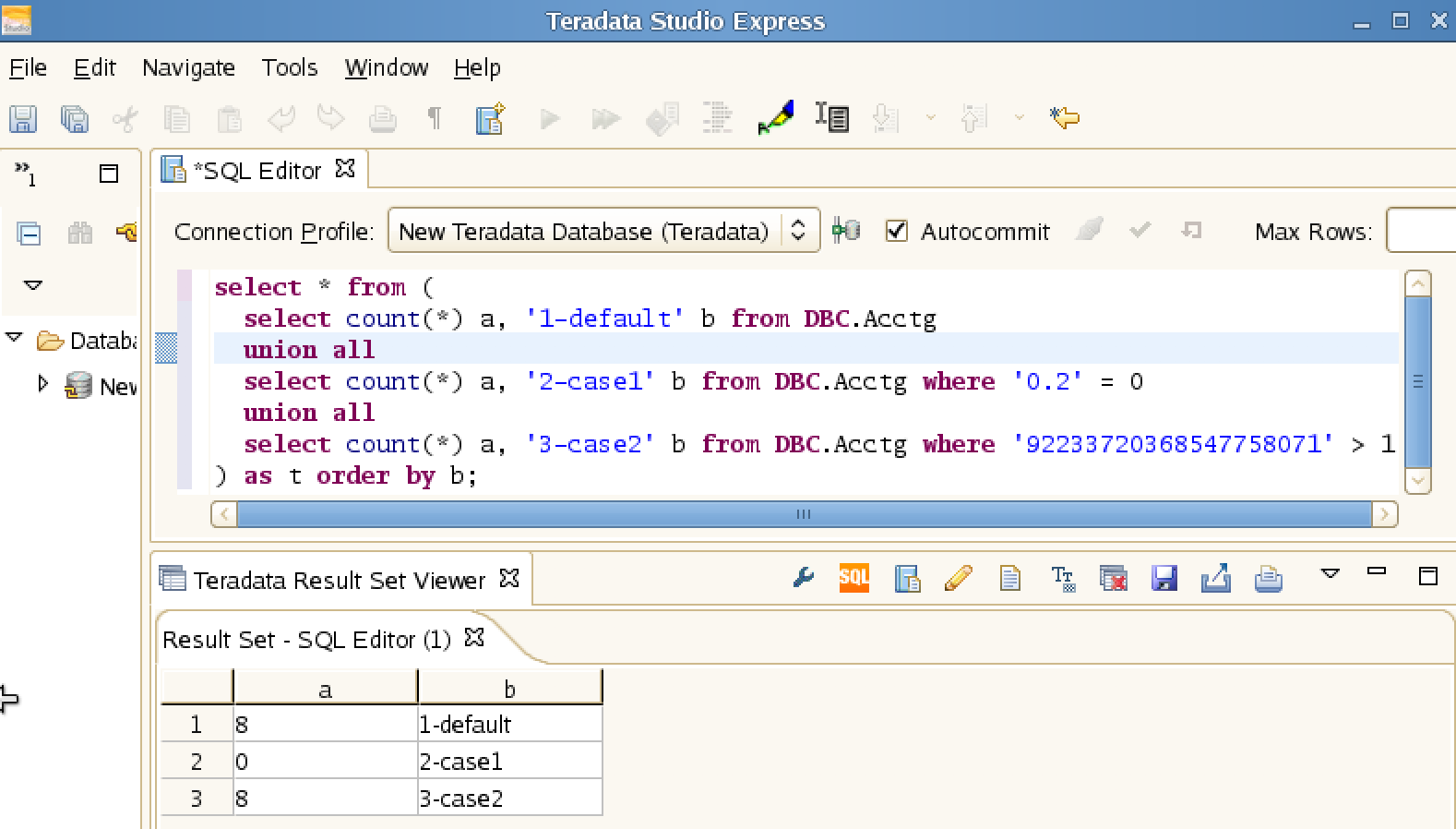

|
Test build #91633 has finished for PR 18853 at commit
|
|
Test build #95733 has finished for PR 18853 at commit
|
What changes were proposed in this pull request?
Add
HiveInConversionandHivePromoteStringsrules toTypeCoercion.scalato compatible with Hive.Add SQL configuration
spark.sql.typeCoercion.modeto configure whether usehivecompatibility mode or defaultdefaultmode.All difference between
defaultmode andhivemode:defaultmode (default mode)hivemode (compatible with Hive)The design doc:
https://issues.apache.org/jira/secure/attachment/12891695/Type_coercion_rules_to_compatible_with_Hive.pdf
How was this patch tested?
unit tests