[SPARK-21087] [ML] CrossValidator, TrainValidationSplit should preserve all models after fitting: Scala #18313
Conversation
|
Test build #78085 has started for PR 18313 at commit |
|
Test build #78554 has finished for PR 18313 at commit
|
|
Test build #78647 has finished for PR 18313 at commit
|
| logWarning(models(i).uid + " did not implement MLWritable. Serialization omitted.") | ||
| } | ||
| } | ||
| metrics(i) += metric |
There was a problem hiding this comment.
ping @hhbyyh @jkbradley
I am sorry but I want to say that this code is incorrect. Inside fit method save the list of fitted models help nothing.
What we need is to let CrossValidatorModel/TrainValidationSplitModel preserve the full list of fitted models, when save CrossValidatorModel/TrainValidationSplitModel we can save the list of models, also we can choose not to save, controlled by a parameter.
There was a problem hiding this comment.
so you want to keep all the trained models in CrossValidatorModel?
There was a problem hiding this comment.
Yes I think so.
In order to save time, I would like to take over this feature, if you don't mind.
ping @jkbradley
There was a problem hiding this comment.
That's interesting...
If somehow we follow your suggestion, with numFolds = 10, and param grid size = 8, you'll be holding 80 models in the driver memory (CrossValidatorModel) at the same time. I would be very surprised to see anyone go along with your suggestion.
I'll happily close the PR if your suggestion turns out to be good.
There was a problem hiding this comment.
@hhbyyh So I we need to set parameter default value false, only when user really need this they turn on this feature... I will discuss with @jkbradley later.
There was a problem hiding this comment.
I agree that 80 models in driver memory sounds like a lot. However, we already are holding that many in driver memory at once in val models = est.fit(trainingDataset, epm), so that should not be a problem for current use cases.
Scaling to large models which do not fit in memory is a different problem, but your PR does bring up the issue that exposing something like models: Seq[...] could cause problems in the future if we want to scale more. I'd suggest 2 things:
- The models could be exposed via a getter, rather than a val. In the future, if the models are not available, the getter could throw a nice exception.
- In the future, we could add the Param which you are suggesting for dumping the models to some directory during training. Feel free to preserve this PR for that, but I think this PR is overkill for most users' needs.
|
Current implementation of With all due respect @jkbradley , for the record, I strongly vote against keeping all the models in the CrossValidatorModel in any way, which makes the feature impractical for any production usage. |
|
Oh, you're right; I overlooked that it only holds all of the models for a single split. In that case, I agree it could be problematic to keep all in memory by default. How does this sound then: We can do 2 separate PRs, each of which adds a separate option:
What do you think? If this sounds good, feel free to reopen your current PR. |
|
@jkbradley Thanks for the suggestion. After the discussion, I found that actually we can reduce the memory requirement for the tuning process. Check https://issues.apache.org/jira/browse/SPARK-21535 if you have some time. And I agree to your suggestion overall, About 1, better have a proper way to manage the cached models for indexing, another hint is that we may calculate the driver memory requirement in advance and send warning or error if necessary. About 2, if we want to use indices rather than the param combination for model names, we probably need to save a summary table with the models. perhaps like #16158 ? |
|
@jkbradley @hhbyyh Your new PR #18733 is meaningful I think, which make the memory cost to be O(1), but we need to consider the case of parallelism, in #16774 , maybe we should wait the #16774 merged, then consider how to optimize the memory usage. |
|
I commented on the JIRA. I would like to better understand the use case more of keeping all the models (as per my JIRA comment). I suspect that #16158 may be the more useful approach in practice. But overall, if there is a use case for keeping the models, I would agree with @jkbradley's suggestion that we offer a simple "keep all sub-models as a field in the model" approach, as well as consider the large-scale case with possibly the "dump to file" option. In addition, we could have an option to keep "best", "all" or "k" models (user-specified as a number or %)? |
|
+1 for merging #16774 before proceeding with the other work since it will affect everything else. @MLnick I'd be Ok with adding options for best/all/k models in the future, but I'm not convinced it's needed since the topK could be computed post-hoc and since the 2 approaches for keeping all models should handle big & small use cases. |
|
The idea with best/all/k is to to allow use cases with fairly large models (say large enough that all 100 or 1000 or whatever param combinations is not feasible to collect to driver) to still store more than just the best model. So it's a way to satisfy both the small-to-medium use case of storing "all", the default use case of "best" and a part solution to the large-model use case using "k". So the idea with the "k" version is to not do a full "collect then top k" but instead keep a running top-k (PriorityQueue perhaps) in order to limit memory consumption. But I agree if we have both solutions (memory and file-based) then it's not necessary (though if one did want to do a top-k on the file-based scenario it would be quite clunky to do). So if that is the end goal then let's do the 2-step process suggested above. |
|
That's all right. Please just proceed. |
What changes were proposed in this pull request?
Allow
CrossValidatorModelandTrainValidationSplitModelpreserve all the of trained models.add a new string param
modelPath, If set, all the models fitted during the training will be saved under the specific directory path. By default the models will not be saved.Save the models during the training to avoid expensive memory consumption from caching the models,
For CrossValidator, it avoids caching all the trained models in memory, and no extra memory consumption is required. (GC can kick in and clear up the models trained for previous splits.)
Allow some models to be preserved even if the training process are interrupted or stopped by exception.
Sample for cross validation models:
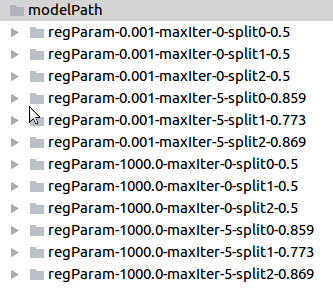
file name pattern: paramMap-split#-metric
Sample for train validation split:

file name pattern: paramMap-metric
How was this patch tested?
new unit tests and local test.