[SPARK-18724][ML] Add TuningSummary for TrainValidationSplit and CrossValidator #16158
Conversation
| def summary: TuningSummary = trainingSummary.getOrElse { | ||
| throw new SparkException( | ||
| s"No training summary available for the ${this.getClass.getSimpleName}") | ||
| } |
There was a problem hiding this comment.
I'm thinking we should add a new trait hasSummary to wrap the summary-related code. I can create another jira if that's reasonable.
|
Test build #69690 has finished for PR 16158 at commit
|
|
@MLnick Does this match your thoughts? Appreciate your opinions. |
 MLnick
left a comment
MLnick
left a comment
There was a problem hiding this comment.
Will go through in more detail but just a quick comment about needing the DataFrame ref in the summary ctor.
| val bestModel = est.fit(dataset, epm(bestIndex)).asInstanceOf[Model[_]] | ||
| copyValues(new TrainValidationSplitModel(uid, bestModel, metrics).setParent(this)) | ||
| val model = copyValues(new TrainValidationSplitModel(uid, bestModel, metrics).setParent(this)) | ||
| val summary = new TuningSummary(bestModel.transform(dataset), epm, metrics, bestIndex) |
There was a problem hiding this comment.
It seems wasteful to do bestModel.transform(dataset) just to get access to the sqlContext. Is it really necessary?
There was a problem hiding this comment.
Indeed that's not necessary. I just replaced it with SparkSession.builder().getOrCreate(). Is there a better way to get the default contexts? Thanks
|
Test build #70097 has finished for PR 16158 at commit
|
|
Test build #71393 has finished for PR 16158 at commit
|
|
Test build #73262 has finished for PR 16158 at commit
|
|
Sorry this slipped! I'd like to revisit soon after 2.2. settles down. I think we may need to consider how this integrates with training / evaluation summaries to create a holistic solution (see SPARK-19053) |
|
@MLnick Thanks for your attention. I'm not sure if SPARK-19053 is still active and maybe it's not a blocking issue for this change. If you don't mind, I'll extend the jira/PR scope to involve CrossValidator to have an integrated improvement. |
|
Yeah maybe do the CV one in this PR too. |
|
Test build #79249 has finished for PR 16158 at commit
|
|
Test build #79251 has finished for PR 16158 at commit
|
|
add tuning summary for crossValidator. |
|
Test build #79919 has finished for PR 16158 at commit
|
| def hasSummary: Boolean = trainingSummary.nonEmpty | ||
|
|
||
| /** | ||
| * Gets summary of model on training set. An exception is |
There was a problem hiding this comment.
Should probably rather be "summary of model performance on the validation set"?
| def hasSummary: Boolean = trainingSummary.nonEmpty | ||
|
|
||
| /** | ||
| * Gets summary of model on training set. An exception is |
There was a problem hiding this comment.
Likewise, "cross-validation performance of each model" or similar?
| copyValues(new CrossValidatorModel(uid, bestModel, metrics).setParent(this)) | ||
| val model = new CrossValidatorModel(uid, bestModel, metrics).setParent(this) | ||
| val summary = new TuningSummary(epm, metrics, bestIndex) | ||
| model.setSummary(Some(summary)) |
There was a problem hiding this comment.
Just to confirm, the tuning summary will not be saved? Since it's a small dataframe, perhaps we should consider saving it with the model? (Can do that in a later PR however)
There was a problem hiding this comment.
If we want to just save the tuning summary in the model, perhaps we can just discard the TuningSummary, and add a tuningSummary: DataFrame field/function in the models. Sounds good?
There was a problem hiding this comment.
Are there other obvious things that might go into the summary in future, that would make a TuningSummary class a better fit?
Future support for say, multiple metrics, could simply extend the dataframe columns so that is ok. But is there anything else you can think of?
There was a problem hiding this comment.
There might be something like detailed training log and training time for each model. But I'm thinking the current Summary pattern does have some room for improvement (e.g., save/load and API), it makes me feel bad when I have to duplicate the code like
def hasSummary: Boolean = trainingSummary.nonEmpty. Thus saving it to the models sounds like a good idea to me.
There was a problem hiding this comment.
The latest implementation does not need to save the extra dataframe. Since basically the dataframe can be generated from $(estimatorParamMaps) and avgMetrics.
| val spark = SparkSession.builder().getOrCreate() | ||
| val sqlContext = spark.sqlContext | ||
| val sc = spark.sparkContext | ||
| val fields = params(0).toSeq.sortBy(_.param.name).map(_.param.name) ++ Seq("metrics") |
There was a problem hiding this comment.
"metrics" is a bit generic. Perhaps it's better (and more user-friendly) to make this be something like metric_name metric so that it's obvious what metric was being optimized for? such as ROC metric or AUC metric or MSE metric? etc
| private[tuning] class TuningSummary private[tuning]( | ||
| private[tuning] val params: Array[ParamMap], | ||
| private[tuning] val metrics: Array[Double], | ||
| private[tuning] val bestIndex: Int) { |
There was a problem hiding this comment.
It appears bestIndex is never used?
| } | ||
| assert(cvModel.summary.trainingMetrics.collect().toSet === expected.toSet) | ||
| } | ||
|
|
There was a problem hiding this comment.
Shall we add a test for the exception being thrown if no summary?
|
@hhbyyh sorry for the delay. Left a few review comments. Tested the examples and it looks cool! Very useful |
|
Move the tuningSummary to Models, and updated the name of the metrics column. |

|
Test build #80467 has finished for PR 16158 at commit
|
 WeichenXu123
left a comment
WeichenXu123
left a comment
There was a problem hiding this comment.
Thanks for the PR ! I leave some comments.
| val rows = sc.parallelize(params.zip(metrics)).map { case (param, metric) => | ||
| val values = param.toSeq.sortBy(_.param.name).map(_.value.toString) ++ Seq(metric.toString) | ||
| Row.fromSeq(values) | ||
| } |
There was a problem hiding this comment.
Here the var names is a little confusing,
params ==> paramMaps
case (param, metric) ==> case (paramMap, metric)
will be more clear.
| val fields = params(0).toSeq.sortBy(_.param.name).map(_.param.name) ++ Seq(metricName) | ||
| val schema = new StructType(fields.map(name => StructField(name, StringType)).toArray) | ||
| val rows = sc.parallelize(params.zip(metrics)).map { case (param, metric) => | ||
| val values = param.toSeq.sortBy(_.param.name).map(_.value.toString) ++ Seq(metric.toString) |
There was a problem hiding this comment.
Here seems exists a problem:
Suppose params(0) (which is a ParamMap) contains ParamA and ParamB,
and params(1) (which is a ParamMap) contains ParamA and ParamC,
The code here will run into problems. Because you compose the row values sorted by param name but do not check whether every row exactly match the first row.
I think better way is, go though the whole ParamMap list and collect all params used, and sort them by name, as the dataframe schema.
There was a problem hiding this comment.
And here use param_value.toString, some array type param will convert to unreadable string.
For example, DoubleArrayParam, doubleArray.toString will became "[DXXXXX"
use Param.jsonEncode is better.
There was a problem hiding this comment.
Thanks, we should support the case for custom paramMap.
|
Test build #81622 has finished for PR 16158 at commit
|
|
Update: To support pipeline estimator, change the tuning summary column name to include full param reference: |
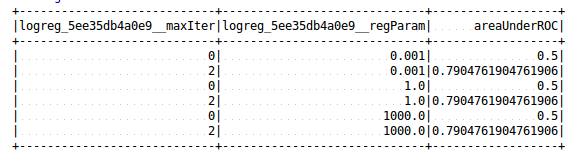
|
Please advice if this is a good feature to add. If not I'll close it. Thanks. |
|
Test build #93758 has finished for PR 16158 at commit
|
|
gentle ping @MLnick, Thanks for the review. Appreciate if you have some time for further comments. |
|
@hhbyyh This PR is stale. If there's nobody interested in this and no further updates, would you mind to close it ? Thanks! |
What changes were proposed in this pull request?
jira: https://issues.apache.org/jira/browse/SPARK-18724
Currently TrainValidationSplitModel only provides tuning metrics in the format of Array[Double], which makes it harder for matching the metrics back to the paramMap generating them and affects the user experience for the tuning framework.
Add a Tuning Summary to provide better presentation for the tuning metrics, for now the idea is to use a DataFrame listing all the params and corresponding metrics.
The Tuning Summary Class can be further extended for CrossValidator.
We can also add training time statistics and metrics rank to the data frame if that sounds good.
Update:
To support pipeline estimator, change the tuning summary column name to include full param reference:
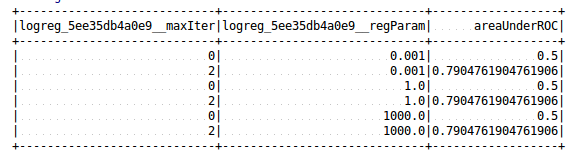
How was this patch tested?
existing and new unit tests