Beyond consolidated metadata for V3: inspiration from Apache Iceberg #154
Description
I just reviewed the V3 spec. As with V2, the core spec does not address how to deal with unlistable stores. In V2, we developed the semi-ad-hoc "consolidated metadata" approach. I know there is already an issue about this vor V3 (#136), but I am opening a new one with the hope of broadening the discussion of what consolidated metadata can be.
Background: What is Apache Iceberg
I have recently been reading about Apache Iceberg. Iceberg is aimed at tabular data, so it is not a direct alternative or competitor to Zarr. Iceberg is not a file format itself (it can use Parquet, Avro, or ORC for individual data files). Instead, it is a scheme for organizing many data files individual into a larger (potentially massive) single "virtual" table. In addition to the table files, it tracks copious metadata about the files. In this sense, it is similar to Zarr: Zarr organizes many individual chunk files into a single large array.
For folks who want quickly come up to speed on Iceberg, I recommend reading the following documents in order:
- What is Iceberg? Features and Benefits (via Dremio)
- Iceberg Spec
Architecturally, these are the main points
This table format tracks individual data files in a table instead of directories. This allows writers to create data files in-place and only adds files to the table in an explicit commit.
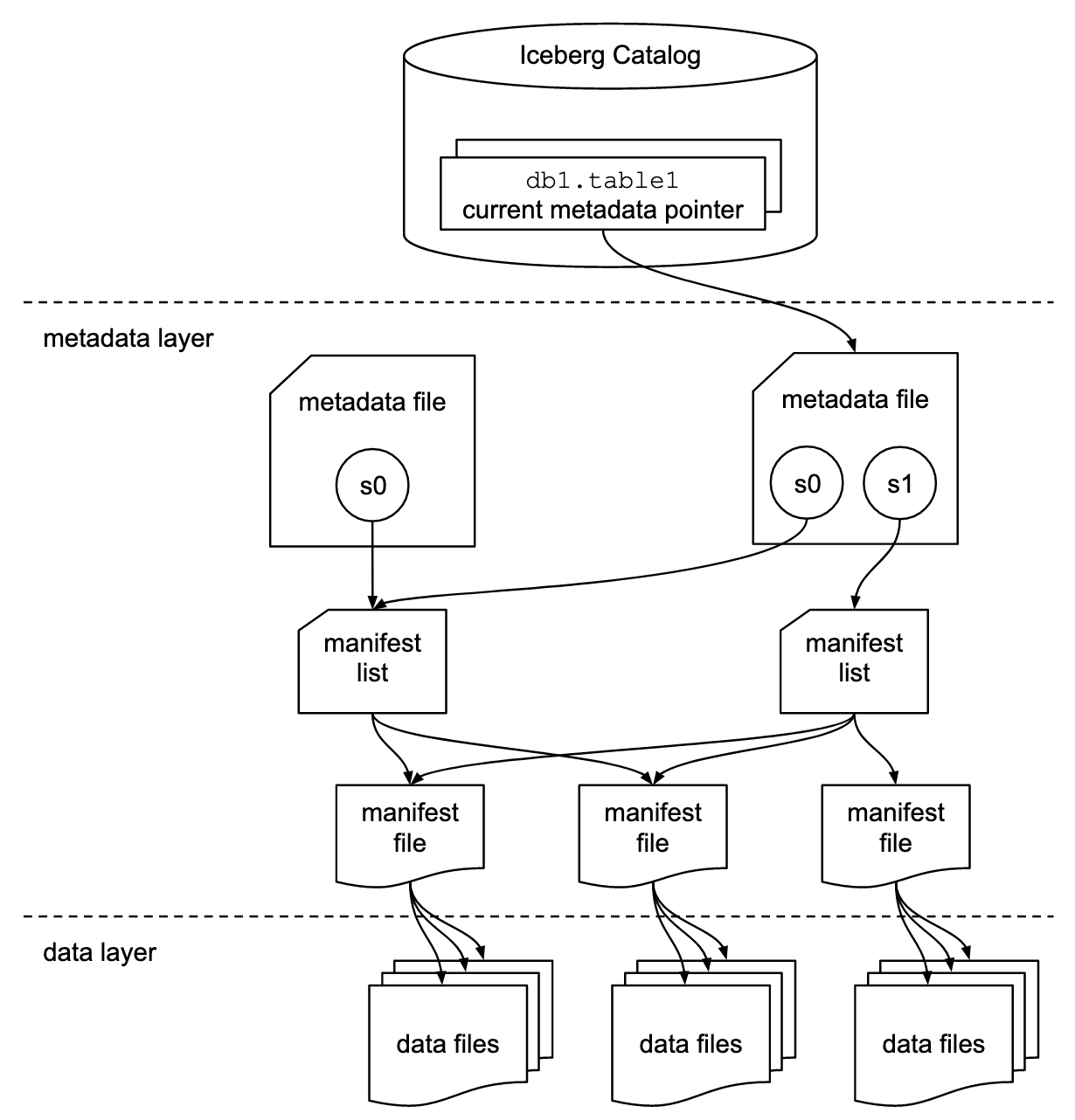
Table state is maintained in metadata files. All changes to table state create a new metadata file and replace the old metadata with an atomic swap. The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents. A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table.
Data files in snapshots are tracked by one or more manifest files that contain a row for each data file in the table, the file’s partition data, and its metrics. The data in a snapshot is the union of all files in its manifests. Manifest files are reused across snapshots to avoid rewriting metadata that is slow-changing. Manifests can track data files with any subset of a table and are not associated with partitions.
The manifests that make up a snapshot are stored in a manifest list file. Each manifest list stores metadata about manifests, including partition stats and data file counts. These stats are used to avoid reading manifests that are not required for an operation.
This diagram says 1000 words.
Another interesting part of the spec, regarding the underling storage system capabilities:
Iceberg only requires that file systems support the following operations:
- In-place write – Files are not moved or altered once they are written.
- Seekable reads – Data file formats require seek support.
- Deletes – Tables delete files that are no longer used.
These requirements are compatible with object stores, like S3.
Tables do not require random-access writes. Once written, data and metadata files are immutable until they are deleted.
Within the data lake / warehouse / lakehouse world, you can think of Iceberg as an open-source alternative to Databricks Delta Lake. It can be used by many different data warehouse query engines like Snowflake, Dremio, Spark, etc.
Inspiration for Zarr
It doesn't make sense to use Iceberg directly for Zarr--it's too tied to the tabular data model. There are lots of interesting ideas and concepts in the Iceberg spec that I think are worth trying to copy in Zarr. Here is a list of some that come to mind
Manifests
Manifests are essentially files which list other files in the dataset. This is conceptually similar to our V2 consolidated metadata in that it removes the need to explicitly list a store. We could store whatever is useful to us in our manifests. For example, we could explicitly list all chunks and their sizes. This would make many operations go much faster, particular on stores that are slow to list or get files information.
Snapshots, Commits, and Time Travel
Iceberg tables are updated by simply adding new files and then updating the manifest list to point to the new files. The new state is registered via an atomic commit operation (familiar to git users). A snapshot points to a particular set of files. We could imagine doing this with zarr chunks, e.g. using the new V3 layout
data/root/foo/baz/c1/0_v0
data/root/foo/baz/c1/0_v1
where _v0 and _v1 are different versions of the same chunk. We could check out different versions of the array corresponding to different commits, preserving the whole history without having to duplicate unnecessary data. @jakirkham and I discussed this idea at scipy. (TileDB has a similar feature.)
Applying the same concept to metadata documents would allow us to evolve array or group schemas and metadata while preserving previous states.
Partition Statistics
If we stored statistics for each chunk, we could optimize many queries. For example, storing the min, max, and sum of each chunk, with reductions applied along each combination of dimensions, would sometimes allow us to avoid explicitly reading a chunk.
Different underlying file formats
Zarr V2 chunks are extremely simple: a single compressed binary blob. As we move towards the sharding storage transformer (#134, #152), they are getting more complicated--a single shard can contain multiple chunks. Via kerchunk, we have learned that most other common array formats (e.g. NetCDF, HDF5) can actually be mapped directly to the zarr data model. (🙌 @martindurant) We are already using kerchunk to create virtual zarr datasets that map each chunk to different memory locations in multiple different HDF5 files. However, that is all outside of any Zarr specification.
Iceberg uses this exact same pattern! You can use many different optimized tabular formats (Parquet, Avro, ORC) for the data files and still expose everything as part of a single big virtual dataset. Adopting Iceberg-style manifests would enable us to formalize this as a supported feature of Zarr.
Implementation Ideas
Having finally understood how storage transformers are supposed to work (thanks to #149 (comment)), I have convinced myself that the iceberg-like features we would want can all be implemented via a storage transformer. In pseudocode, the API might look like this
base_store = S3Store("s3://some-bucket")
zarrberg_store = ZarrIcebergStorageTransformer(base_store)
# check out a the latest version
zarrberg_store.checkout()
group = zarr.open_group(zarrberg_store)
# update some data
group['foo'][0, 0] = 1
new_version = zarrberg_store.commit()
# check out some older version
zarrberg_store.checkout("abc123")
older_group = zarr.open_group(zarrberg_store)The storage transformer class would do the work of translating specific storage keys requests into the correct paths in the underlying store (e.g. data/root/foo/0.0 ➡️ data/root/foo/0.0_v2).
Summary
I'm quite excited about the possibilities that this direction would open up. Benefits for Zarr would be
- Even better performance on slow-to-list stores
- Time-travel and versioning
- Ability to wrap other array file types explicitly, formalizing what we are already doing with Kerchunk
- A solution for concurrent writes to the same chunk (one of the commits would fail and have to be retried with updated data)
- Alignment with a widely adopted and successful approach in enterprise big data architecture
At the same time, I am aware of the large amount of work involved. I think a useful path forward is to look for the 90/10 solution--what could we imitate from Iceberg that would give us 90% of the benefits for 10% of the effort.