This repository contains a practical example about how to build a GPT-4 Q&A app capable of answering questions related to your private documents in just a couple of hours.
The app uses the following technologies:
The repository contains the following applications.
- A
Jupyter Notebookreads your private documents (for this example I'm using the dotnet microservices book) and stores the content in Pinecone. - A
Streamlitapp allow us to query the data stored in Pinecone using a GPT-4 LLM model.
- Azure OpenAI
- Pinecone
You MUST have the following services running before trying to execute the app.
- An
Azure OpenAIinstance with the following models deployed:text-embedding-ada-002.gpt-4orgpt-4-32k.
The models can be called whatever you like.
- A
Pineconedatabase with an index with1536dimensions andcosinemetric.
The index can be called whatever you like.
Before trying to run the app, read the Prerequisites section.
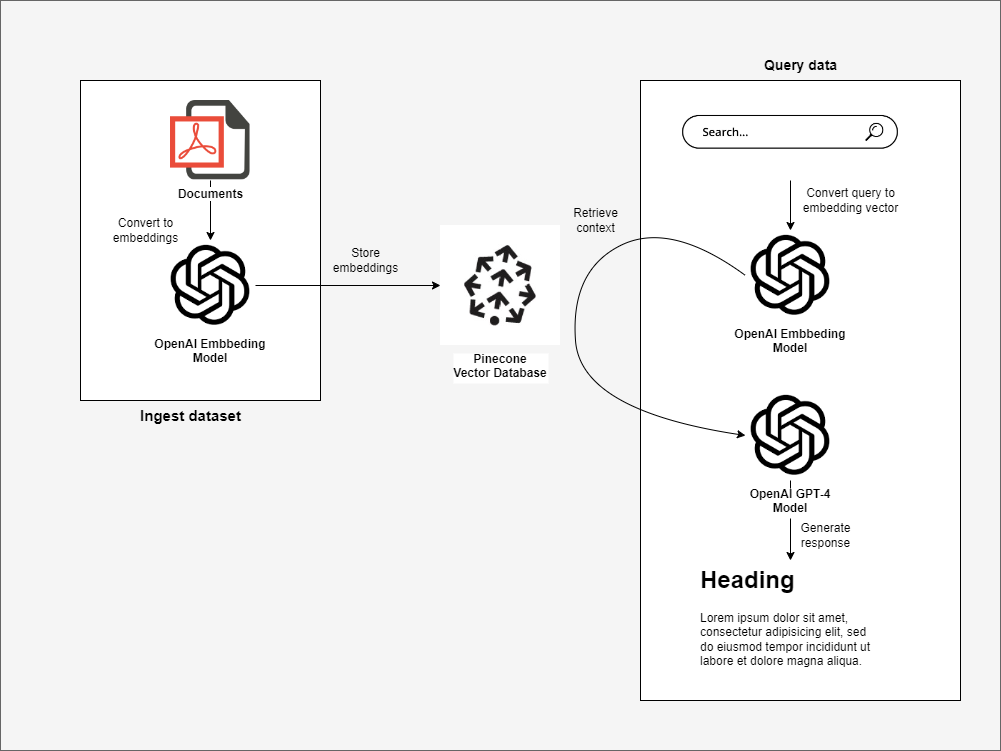
The repository contains a Jupyter Notebook that reads a PDF file from the docs folder, splits the content into multiple chunks and stores them into PineCone.
You must set the following enviroment variables, before executing the Jupyter Notebook:
PINECONE_API_KEY: Pinecone ApiKey.PINECONE_ENVIRONMENT: Pinecone index environment.PINECONE_INDEX_NAME: Pinecone index name.AZURE_OPENAI_APIKEY: Azure OpenAI ApiKey.AZURE_OPENAI_BASE_URI: Azure OpenAI URI.AZURE_OPENAI_EMBEDDINGS_MODEL_NAME: Thetext-embedding-ada-002model deployment name.AZURE_OPENAI_GPT4_MODEL_NAME: Thegpt-4model deployment name.
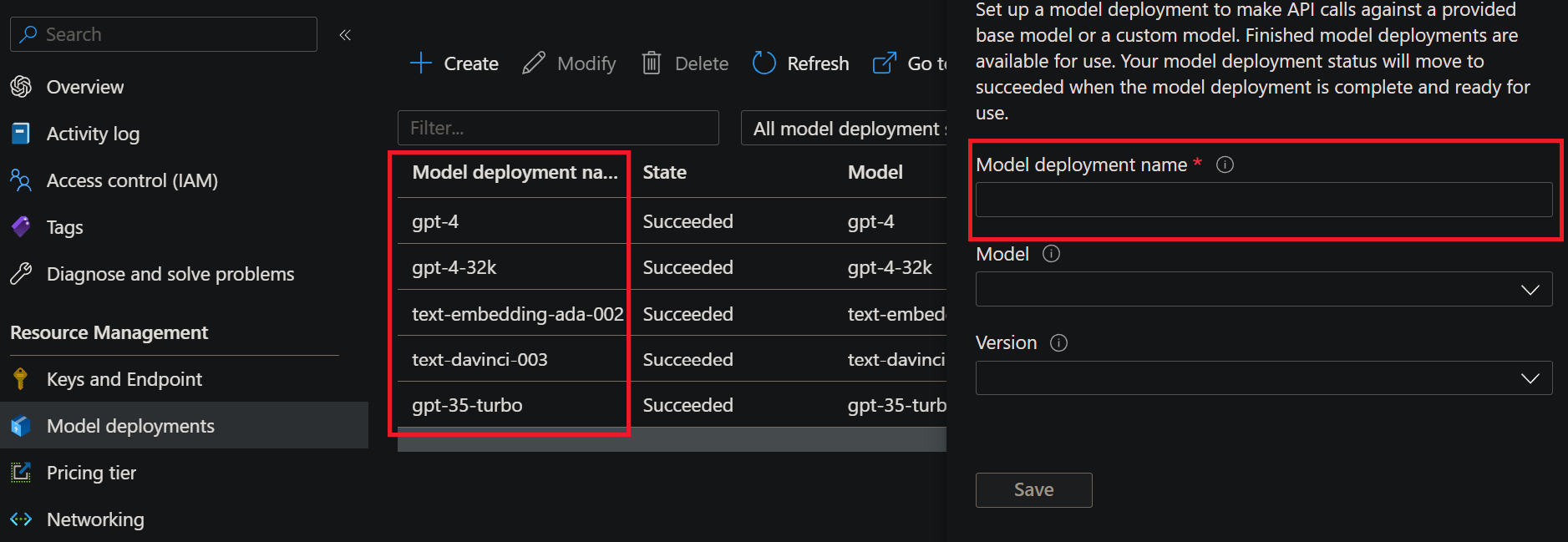
What's the model deployment name?
- When you deploy a model on an
Azure OpenAIinstance you must give it a name.
For this example to run properly you need to deploy at least atext-embedding-ada-002model and agpt-4model.
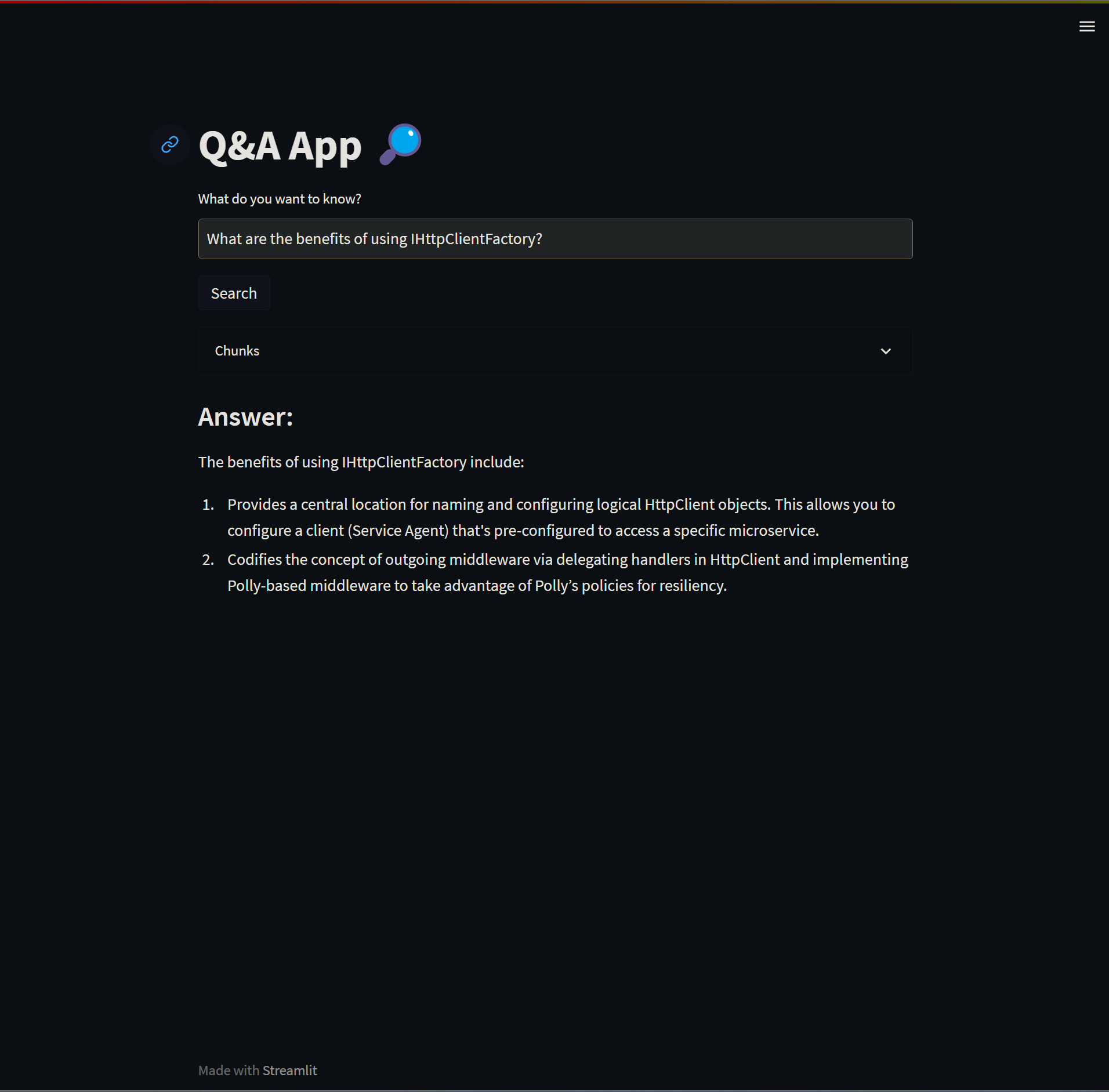
The app.py is a Streamlit app that does the following steps:
- Converts your query into a vector.
- Retrieves the information that is semantically related to our query from Pinecone.
- Feeds the retrieved information into a LLM model which builds a response.
Run the app locally :
Restore dependencies:
pip install -r requirements.txtWhen you install Streamlit, a command-line (CLI) tool gets installed as well. The purpose of this tool is to run Streamlit apps.
streamlit run app.pyYou MUST set the following environment variables on your local machine before executing the app:
PINECONE_API_KEY: Pinecone ApiKey.PINECONE_ENVIRONMENT: Pinecone index environment.PINECONE_INDEX_NAME: Pinecone index name.AZURE_OPENAI_APIKEY: Azure OpenAI ApiKey.AZURE_OPENAI_BASE_URI: Azure OpenAI URI.AZURE_OPENAI_EMBEDDINGS_MODEL_NAME: Thetext-embedding-ada-002model deployment name.AZURE_OPENAI_GPT4_MODEL_NAME: Thegpt-4model deployment name.
Run the app in a container:
This repository has a Dockerfile in case you prefer to execute the app on a container.
Build the image:
docker build -t qa-app .Run it:
docker run -p 5050:5050 \
-e AZURE_OPENAI_APIKEY="<azure-openai-api-key>" \
-e AZURE_OPENAI_BASE_URI="<azure-openai-api-uri>" \
-e AZURE_OPENAI_EMBEDDINGS_MODEL_NAME="<azure-openai-embeddings-deployment-model-name>" \
-e AZURE_OPENAI_GPT4_MODEL_NAME="<azure-openai-gpt4-deployment-model-name>" \
-e PINECONE_INDEX="<pinecone-index-name>" \
-e PINECONE_ENVIRONMENT="<pinecone-environment-name>" \
-e PINECONE_API_KEY="<pinecone-api-key>" \
qa-app