Description
buildSchema can be quite slow given a large schema. Using GitHub's public SDL on my local machine, It can take around 200ms to build a schema from an SDL string.
This time is improved by a lot if we assume we're dealing with a valid schema. This brings down the same SDL to about 120ms.
const schema = buildSchema(sdl, { assumeValid: true });
Even when skipping validation, I noticed a significant portion of the time is spent in collectReferencedTypes.
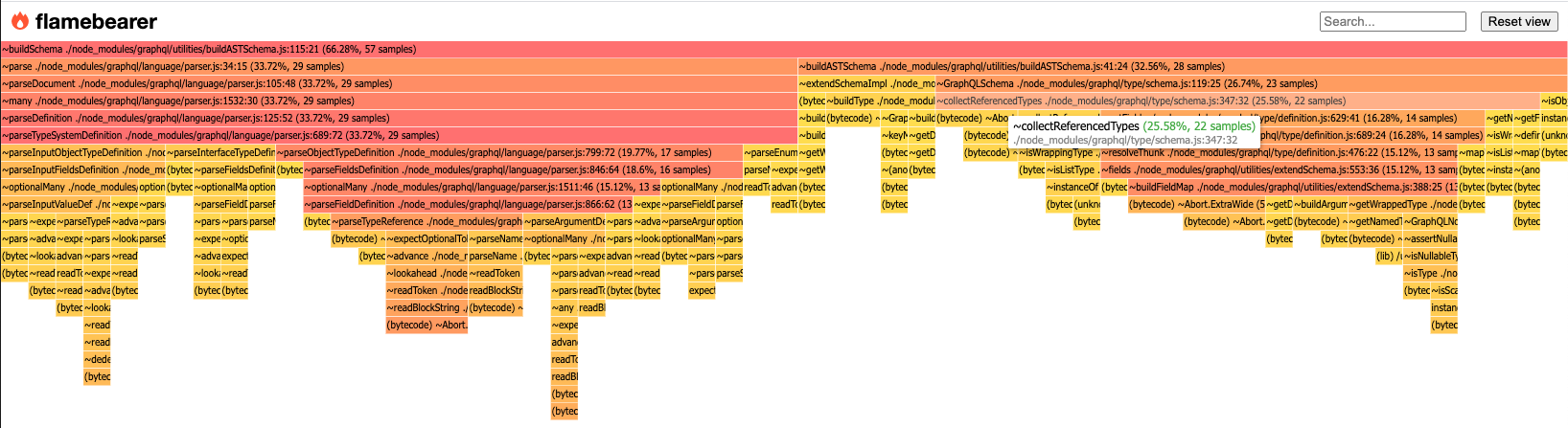
In the case of buildSchema, it seems like the types that are collected at part time could be considered as the full set of types for the schema. From my understanding, it looks like this collectReferencedTypes is mainly used to support the use case of programmatically creating a schema by providing only the root types:
const schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: {
hero: { type: characterInterface, ... },
}
}),
types: [humanType, droidType],
})When it comes to buildSchema however, I believe this is work that could easily be skipped. Correct me if I am wrong here! Additionally, it's hard to extend buildSchema or GraphQLSchema in user land if someone did want to skip this processing. The fact this is done in the constructor makes this particularly difficult.
Would you be open to a configuration option, or another entry point (refactoring the collect part away from Schema's constructor possibly) so that this work can be skipped?
My use case involves parsing and using buildSchema dynamically at request time, which is why these optimizations are needed. Let me know if I've missed anything here 🙇