Reuse local node in async shard fetch responses #77991
Conversation
We read various objects from the wire that already exist in the cluster state. The most notable is `DiscoveryNode` which can consume ~2kB in heap for each fresh object, but rarely changes, so it's pretty wasteful to use fresh objects here. There could be thousands (millions?) of `DiscoveryNode` objects in flight from various `TransportNodesAction` responses. This branch adds a `DiscoveryNode` parameter to the response deserialisation method and makes sure that the worst offenders re-use the local object rather than creating a fresh one: - `TransportNodesListShardStoreMetadata` - `TransportNodesListGatewayStartedShards` Relates elastic#77266
205073d to
c35942b
Compare
|
Pinging @elastic/es-distributed (Team:Distributed) |
|
Thanks Henning :) |
💔 Backport failed
You can use sqren/backport to manually backport by running |
We read various objects from the wire that already exist in the cluster state. The most notable is `DiscoveryNode` which can consume ~2kB in heap for each fresh object, but rarely changes, so it's pretty wasteful to use fresh objects here. There could be thousands (millions?) of `DiscoveryNode` objects in flight from various `TransportNodesAction` responses. This branch adds a `DiscoveryNode` parameter to the response deserialisation method and makes sure that the worst offenders re-use the local object rather than creating a fresh one: - `TransportNodesListShardStoreMetadata` - `TransportNodesListGatewayStartedShards` Relates #77266
|
@DaveCTurner In our production env, we double checked the optimization about fetcing respose memory consumption. After this PR optimization, it only has 128 bytes that contains However, the master's heap is still crash, due to huge inflight fetch shard requests. In our case, we have 75 data nodes, and 3 dedicated master nodes, each master node has 4 GB heap, 1.5w shards. After full restarting cluster, master node memory will used up in several seconds. We dump the memory and found netty inflight sending request used lots of heap: Each From So besides cutting fetch shard response, we also need to handle massive shard sending requests. |
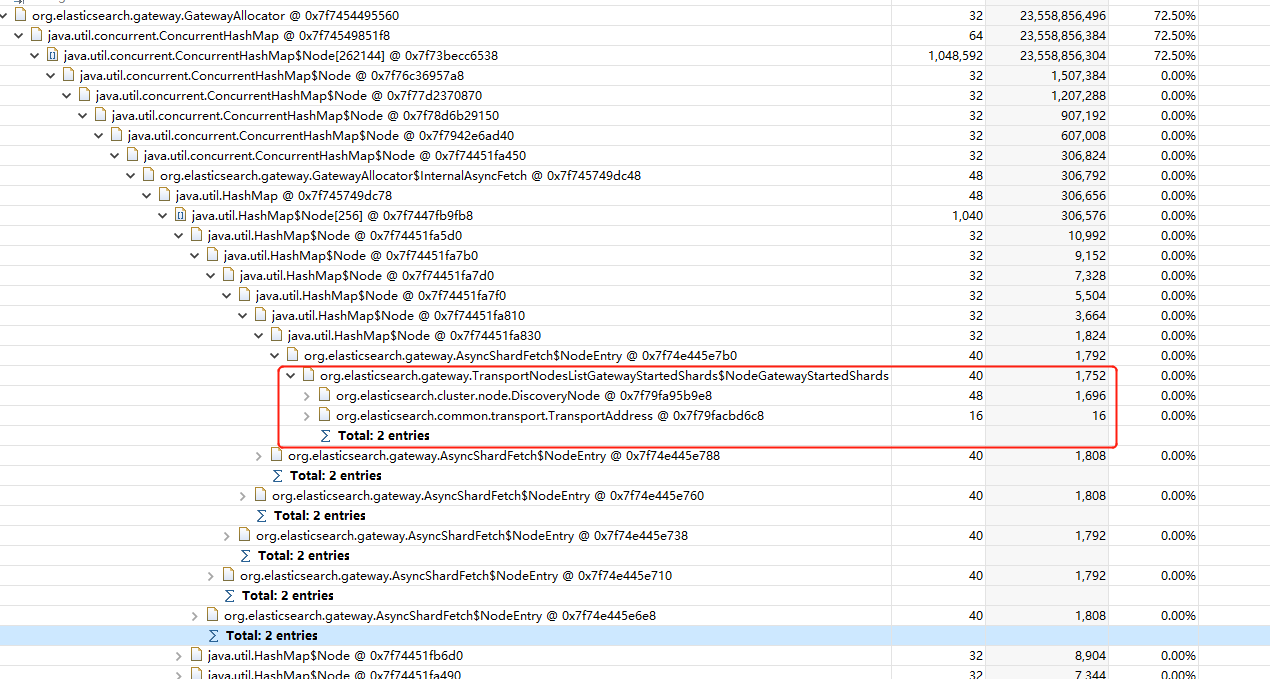
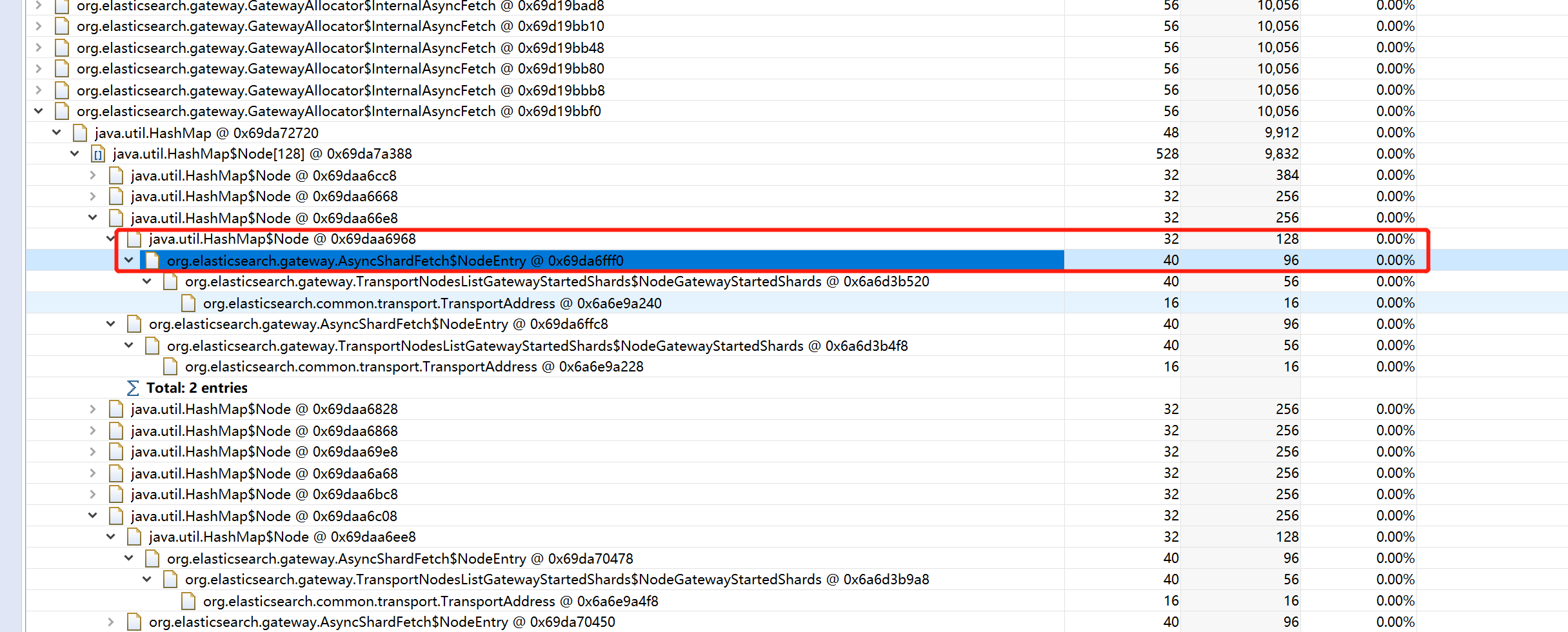
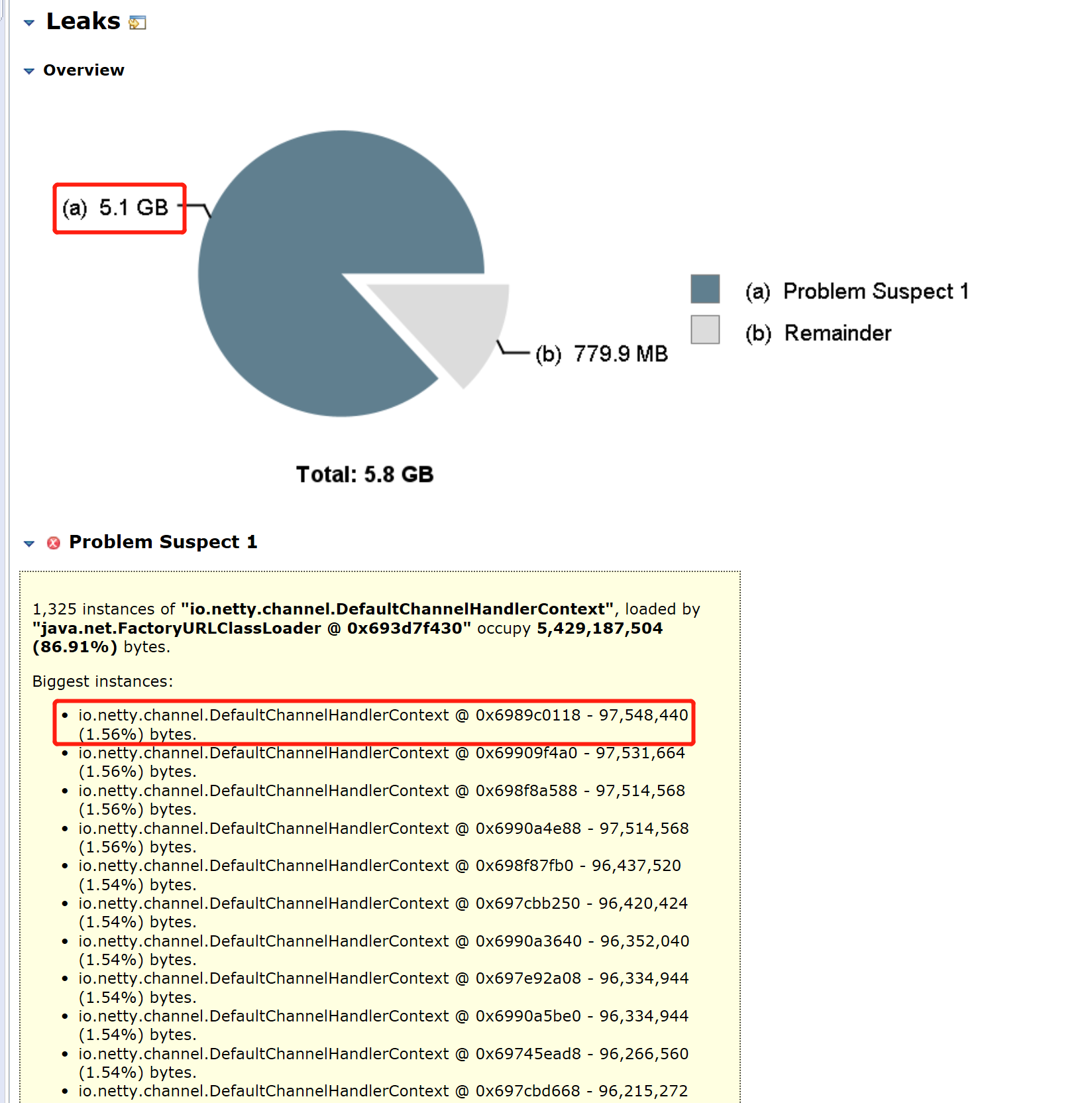

|
That sounds like a separate problem @howardhuanghua, although it's related. Would you open a new issue about it?
I think that's a typo, but this is important - how many shards are there in this cluster? |
|
@DaveCTurner Sorry about the typo. 15000 shards total in cluster. I will open another issue. |
|
Opened a new issue #80694. |
TIL that you used "w" to abbreviate "wan", i.e. 万, meaning 10,000. I didn't know that was a thing, but I do now 😄 |
|
😄 Yes, you are right. It's a Chinese style. |
Reuse local node in async shard fetch responses
We read various objects from the wire that already exist in the cluster
state. The most notable is
DiscoveryNodewhich can consume ~2kB inheap for each fresh object, but rarely changes, so it's pretty wasteful
to use fresh objects here. There could be thousands (millions?) of
DiscoveryNodeobjects in flight from variousTransportNodesActionresponses.
This branch adds a
DiscoveryNodeparameter to the responsedeserialisation method and makes sure that the worst offenders re-use
the local object rather than creating a fresh one:
TransportNodesListShardStoreMetadataTransportNodesListGatewayStartedShardsRelates #77266