metadata processing optimization, rebalance and allocation separation. #42738
Conversation
|
Pinging @elastic/es-distributed |
 ywelsch
left a comment
ywelsch
left a comment
There was a problem hiding this comment.
This is an interesting optimization that we wanted to look into as well at some point. One difference I had in mind when it comes to the implementation in this PR was to not reroute based on a schedule, but do the delayed full reroute by submitting a lower priority cluster state update task, so that other tasks with higher priority can make progress. I also don't think it makes sense to separate out moveShards as a separate step from allocateUnassigned and rebalance, as moveShards can be triggered by more events than just setting changes. For example, disk watermarks going above a certain threshold will trigger a move of shards.
Have you run our existing test suite on this changes?
|
The task that led to our cluster piled up hundreds of thousands. submitting a lower priority cluster state update task is right, So I made priority normal. so that other tasks with higher priority can make progress. |
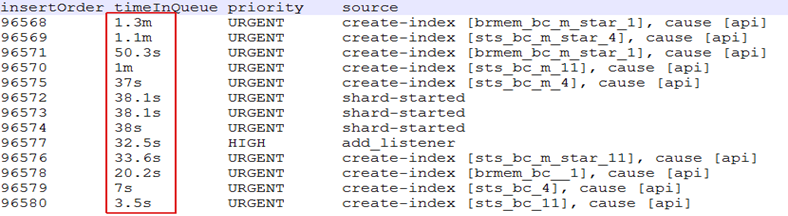
|
When frequently performing metadata change operations, thread long-time cards are found in balance ByWeights (), shardsWithState (), awaitAllNodes () and other methods by printing stack. |
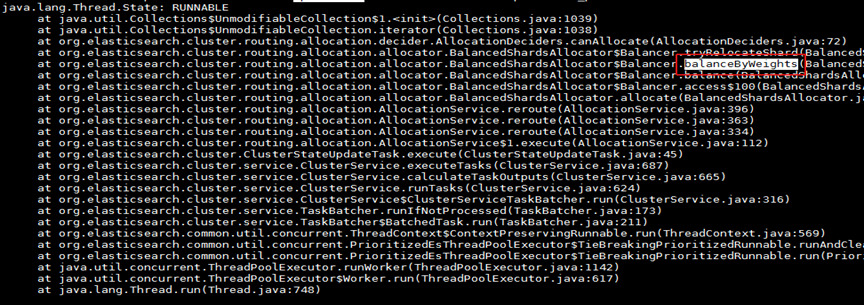
|
@hanbj I've made some suggestions on how to evolve this PR and also left a specific question about the tests, on which you have not commented. As noted above, we are interested in improving the system along the lines you've suggested, but with some adjustments. Are you interested in exploring that solution and taking this PR forward? If not, I would prefer to close this PR and open an issue instead to track this as an open item.
300,000 shards in a single cluster is perhaps a bit too much. Splitting this cluster up into multiple separate clusters will help with the general cluster health, improve fault-tolerance of the system and make operational tasks such as cluster restarts etc. much faster. With that high number of shards, you will also encounter other issues, not only related to shard balancing. Think for example about shard-level stats/metric collection etc. |
Today we reroute the cluster as part of the process of starting a shard, which runs at `URGENT` priority. In large clusters, rerouting may take some time to complete, and this means that a mere trickle of shard-started events can cause starvation for other, lower-priority, tasks that are pending on the master. However, it isn't really necessary to perform a reroute when starting a shard, as long as one occurs eventually. This commit removes the inline reroute from the process of starting a shard and replaces it with a deferred one that runs at `NORMAL` priority, avoiding starvation of higher-priority tasks. This may improve some of the situations related to elastic#42738 and elastic#42105.
* Defer reroute when starting shards Today we reroute the cluster as part of the process of starting a shard, which runs at `URGENT` priority. In large clusters, rerouting may take some time to complete, and this means that a mere trickle of shard-started events can cause starvation for other, lower-priority, tasks that are pending on the master. However, it isn't really necessary to perform a reroute when starting a shard, as long as one occurs eventually. This commit removes the inline reroute from the process of starting a shard and replaces it with a deferred one that runs at `NORMAL` priority, avoiding starvation of higher-priority tasks. This may improve some of the situations related to #42738 and #42105. * Specific test case for followup priority setting We cannot set the priority in all InternalTestClusters because the deprecation warning makes some tests unhappy. This commit adds a specific test instead. * Checkstyle * Cluster state always changed here * Assert consistency of routing nodes * Restrict setting only to reasonable priorities
* Defer reroute when starting shards Today we reroute the cluster as part of the process of starting a shard, which runs at `URGENT` priority. In large clusters, rerouting may take some time to complete, and this means that a mere trickle of shard-started events can cause starvation for other, lower-priority, tasks that are pending on the master. However, it isn't really necessary to perform a reroute when starting a shard, as long as one occurs eventually. This commit removes the inline reroute from the process of starting a shard and replaces it with a deferred one that runs at `NORMAL` priority, avoiding starvation of higher-priority tasks. This may improve some of the situations related to elastic#42738 and elastic#42105. * Specific test case for followup priority setting We cannot set the priority in all InternalTestClusters because the deprecation warning makes some tests unhappy. This commit adds a specific test instead. * Checkstyle * Cluster state always changed here * Assert consistency of routing nodes * Restrict setting only to reasonable priorities
|
@ywelsch It is my pleasure and honor to discuss with you the solution to this problem. |
|
Closing this due to inactivity |
|
@ywelsch Thank you, I found that this is still a problem, we are planning to implement it from another namespace way, ES cluster can be infinitely expanded, so this is the reason why I have not updated this pr for so long. I am very sorry. |
Our cluster has encountered a bottleneck in metadata operations. so we optimized it.
In our production environment has been running for about half a year, compared with the previous, there are dozens of times the performance improvement.