Use Sse2 instrinsics to make NeedsEscaping check faster for large JSON strings #41845
Conversation
|
cc @ericstj |
| { | ||
| goto Return; | ||
| short* startingAddress = (short*)ptr; | ||
| while (value.Length - 8 >= idx) |
There was a problem hiding this comment.
is value.Length - 8 cached or recomputed each loop iteration?
There was a problem hiding this comment.
It's effectively cached. The generated assembly doesn't change if I save it in a local.
00007FFD786C17CA mov rbp,rdi
00007FFD786C17CD lea r14d,[rsi-8]
00007FFD786C17D1 test r14d,r14d
00007FFD786C17D4 jl 00007FFD786C180A
| } | ||
|
|
||
| public static unsafe int NeedsEscaping(ReadOnlySpan<char> value, JavaScriptEncoder encoder) | ||
| { |
There was a problem hiding this comment.
Reordering this to be effectively:
if ((value.Length < 16) || !Sse2.IsSupported)
{
SoftwareFallback();
}
else
{
Sse2Impl();
SoftwareFallback(); // To Handle Trailing Bits
}
Is likely going to be more efficient (likely inlining the logic, rather than having method calls).
There was a problem hiding this comment.
Loops are predicted to be "taken" by default; so you will currently get a branch mispredict for the length < 16 case and that regresses perf for that scenario more.
The JIT also, by default, emits if (cond) { code1 } else { code2 } blocks such that code1 is the fallthrough case (predicted as taken by default on x86).
This means that you generally don't want to do if ((value.Length > 16) && Sse2.IsSupported) { Sse2.Impl } SoftwareFallback();; as that will also regress the small case more.
Ordering it as suggested above should help keep the small case fast and the branch mispredicts will be amortized for the longer cases.
There was a problem hiding this comment.
It doesn't seem to improve perf, and ends up hurting perf in the case when I call it with a variety of lengths within the benchmark.
There was a problem hiding this comment.
and ends up hurting perf in the case when I call it with a variety of lengths within the benchmark.
That is likely a case of benchmarks training the branch predictor to expect 'x' and may not be representative of actual code.
There was a problem hiding this comment.
That is likely a case of benchmarks training the branch predictor to expect 'x' and may not be representative of actual code.
That's why I chose random string lengths to avoid that (where statistically half the strings were > 8 and half were less than 8).
public unsafe class Test_EscapingComparison_Reorder
{
private string[] _sources;
private JavaScriptEncoder _encoder;
[GlobalSetup]
public void Setup()
{
_sources = new string[1_000];
var random = new Random(42);
for (int j = 0; j < 1_000; j++)
{
int DataLength = random.Next(1, 16);
var array = new char[DataLength];
for (int i = 0; i < DataLength; i++)
{
array[i] = (char)random.Next(97, 123);
}
_sources[j] = new string(array);
}
_encoder = null;
}
[BenchmarkCategory(Categories.CoreFX, Categories.JSON)]
[Benchmark(Baseline = true)]
public int NeedsEscapingNewFixed()
{
int result = 0;
for (int i = 0; i < _sources.Length; i++)
{
result ^= NeedsEscaping_New_Fixed(_sources[i], _encoder);
}
return result;
}
[BenchmarkCategory(Categories.CoreFX, Categories.JSON)]
[Benchmark]
public int NeedsEscapingNewFixedReorder()
{
int result = 0;
for (int i = 0; i < _sources.Length; i++)
{
result ^= NeedsEscaping_New_Fixed_Reorder(_sources[i], _encoder);
}
return result;
}
// ... implementations
}I also tried with using the writer/serializer and didn't see a significant improvement.
| } | ||
| #endif | ||
|
|
||
| for (; idx < value.Length; idx++) |
There was a problem hiding this comment.
You could handle trailing elements and even the length < 8 case using hwintrinsics as well.
Namely if you do ptr -= (16 - remaining) and then mask out the first (16 - remaining) elements, you can safely do a single iteration of the above vectorized code; and avoid the trailing logic here
There was a problem hiding this comment.
I tried that approach but that tend to slow things down quite a bit for length < 8.
https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee#file-test_stringescaping_comparison-cs-L335-L345
For example, processing 1 character string went from 3 ns to 10 ns.
I tried just assuming 1 char input, with no if-checks/while loops as an experiment to measure just the cost of the work being done per iteration (only the hwintrinsics call), and it still took ~7 ns.
There was a problem hiding this comment.
mask out the first (16 - remaining) elements
I think it's not needed to mask them out, so you could save that effort. Just keep them in. The check is idempotent, and it's already proven that these don't need to be escaped, so another check will result in the same.
Just post-process the correct index.
There was a problem hiding this comment.
I think the masking out would be necessary if the same loop was used for length < 8 (and not just leftovers after length % 8). You wouldn't want the data that happens to be there in memory before the data (outside the string passed-in) to affect the results of escaping.
There was a problem hiding this comment.
Maybe we talk about differnt things now.
@tannergooding and I mean that the remainder of the vectorized code-path can also be processed in a vectorized way. Just feed a vector beginning from the end through the vectorized code-path above. There is no masking out needed.
Trivial example:
Let's assume length = 10 chars.
First vector has elements 0..8, they are checked, nothing needs to be escaped. 2 elements remain.
Final vector has elements 2..10, where six elements (2..8) are already checked, but we don't care, as this is cheaper than masking out, and the check is idempotent, meaning for elements 2..8 we get the same result (= nothing needs to be escaped, otherwise we wouldn't get here) as in the theck for 0..8. So only the portion 9..10 (= the remainder) can give a different result.
This should be faster than processing the remainder with masking out or with the sequential loop (although maybe not for this example with 2 remaining elements, but for larger remainders or on the byte-version, where 16 elements are checked at one, so larger remainders can occur).
Clear what I mean?
There was a problem hiding this comment.
Yes, I understand what you mean. We could certainly do that for length >= 8 and that's partially what I tried here.
https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee#file-test_stringescaping_comparison-cs-L312-L385
It's a good idea to avoid the masking step for the processing the trailing bits/remainder and that can make checking the remainder faster, but there are diminishing returns here and I am less concerned about the remainder for length >= 8 case. The NeedsEscaping_BackFill approach is too slow for input length < 8 which is why I didn't go down that route and your suggestions don't apply for that case to make that faster. I didn't want the logic to be subtly different for length < 8 and processing the trailing length % 8 characters, in an effort to avoid code duplication and increasing the code complexity too much (especially since we have if/def and !Sse.IsSupported blocks already that have to process sequentially).
If you have suggestions where I can process both length < 8 and length % 8 remaining characters in the same way, then I can explore that :)
Still, I will play around with the suggestion for processing the remainder. I don't know if adding the "remainder" logic in the main 8-character loop would be worth it though.
There was a problem hiding this comment.
So, I tried this, and it is slower when inputLength % 8 <= 4 (that's the break-even point where the intrinsics is faster than iterating sequentially - so if the string is between 8 and 12 characters, sequential is better, but for 12 to 16, intrinsics is better). I don't think it's worth it.
public static unsafe int NeedsEscaping_BackFill_New(ReadOnlySpan<char> value, JavaScriptEncoder encoder)
{
fixed (char* ptr = value)
{
int idx = 0;
if (encoder != null && !value.IsEmpty)
{
idx = encoder.FindFirstCharacterToEncode(ptr, value.Length);
goto Return;
}
if (value.Length < 8)
{
for (; idx < value.Length; idx++)
{
if (NeedsEscaping(*(ptr + idx)))
{
goto Return;
}
}
}
else
{
short* startingAddress = (short*)ptr;
while (value.Length - 8 >= idx)
{
if (NextEightCharactersNeedEscaping(startingAddress, ref idx))
{
goto Return;
}
idx += 8;
startingAddress += 8;
}
int remainder = value.Length - idx;
if (remainder > 0)
{
if (NextEightCharactersNeedEscaping(startingAddress, ref idx, 8 - remainder))
{
goto Return;
}
}
}
idx = -1; // all characters allowed
Return:
return idx;
}
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private static bool NextEightCharactersNeedEscaping(short* startingAddress, ref int idx, int backFillCount = 0)
{
bool result = true;
Vector128<short> sourceValue = Sse2.LoadVector128(startingAddress - backFillCount);
Vector128<short> mask = CreateEscapingMask(sourceValue);
int index = Sse2.MoveMask(mask.AsByte());
if (index != 0)
{
idx += (BitOperations.TrailingZeroCount(index) >> 1) - backFillCount;
goto Return;
}
result = false;
Return:
return result;
}BenchmarkDotNet=v0.11.5.1159-nightly, OS=Windows 10.0.18362
Intel Core i7-6700 CPU 3.40GHz (Skylake), 1 CPU, 8 logical and 4 physical cores
.NET Core SDK=5.0.100-alpha1-014834
[Host] : .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), X64 RyuJIT
Job-QDEVCA : .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), X64 RyuJIT
PowerPlanMode=00000000-0000-0000-0000-000000000000 IterationTime=250.0000 ms MaxIterationCount=20
MinIterationCount=15 WarmupCount=1
| Method | DataLength | NegativeIndex | Mean | Error | StdDev | Median | Min | Max | Ratio | RatioSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NeedsEscapingCurrent | 1 | -1 | 2.691 ns | 0.1272 ns | 0.1465 ns | 2.654 ns | 2.529 ns | 3.023 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 1 | -1 | 5.254 ns | 0.2557 ns | 0.2944 ns | 5.163 ns | 4.902 ns | 5.865 ns | 1.96 | 0.10 | - | - | - | - |
| NeedsEscapingBackFill_New | 1 | -1 | 5.507 ns | 0.1617 ns | 0.1863 ns | 5.468 ns | 5.267 ns | 5.895 ns | 2.05 | 0.15 | - | - | - | - |
| NeedsEscapingCurrent | 2 | -1 | 3.828 ns | 0.1258 ns | 0.1448 ns | 3.832 ns | 3.586 ns | 4.043 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 2 | -1 | 5.901 ns | 0.1807 ns | 0.2008 ns | 5.882 ns | 5.466 ns | 6.273 ns | 1.54 | 0.06 | - | - | - | - |
| NeedsEscapingBackFill_New | 2 | -1 | 6.445 ns | 0.2043 ns | 0.2353 ns | 6.395 ns | 6.093 ns | 6.841 ns | 1.69 | 0.09 | - | - | - | - |
| NeedsEscapingCurrent | 4 | -1 | 6.112 ns | 0.2043 ns | 0.2353 ns | 6.064 ns | 5.835 ns | 6.622 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 4 | -1 | 7.649 ns | 0.1833 ns | 0.1961 ns | 7.623 ns | 7.404 ns | 8.099 ns | 1.25 | 0.06 | - | - | - | - |
| NeedsEscapingBackFill_New | 4 | -1 | 8.718 ns | 0.2017 ns | 0.1981 ns | 8.726 ns | 8.202 ns | 8.987 ns | 1.43 | 0.06 | - | - | - | - |
| NeedsEscapingCurrent | 7 | -1 | 9.393 ns | 0.2183 ns | 0.2042 ns | 9.380 ns | 8.935 ns | 9.749 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 7 | -1 | 11.000 ns | 0.5758 ns | 0.6631 ns | 10.718 ns | 10.247 ns | 12.539 ns | 1.14 | 0.04 | - | - | - | - |
| NeedsEscapingBackFill_New | 7 | -1 | 11.972 ns | 0.2565 ns | 0.2400 ns | 12.032 ns | 11.479 ns | 12.338 ns | 1.28 | 0.04 | - | - | - | - |
| NeedsEscapingCurrent | 8 | -1 | 10.450 ns | 0.2168 ns | 0.2028 ns | 10.426 ns | 10.166 ns | 10.863 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 8 | -1 | 10.929 ns | 0.5047 ns | 0.5813 ns | 11.009 ns | 9.567 ns | 12.101 ns | 1.05 | 0.04 | - | - | - | - |
| NeedsEscapingBackFill_New | 8 | -1 | 11.565 ns | 0.5790 ns | 0.6435 ns | 11.454 ns | 10.592 ns | 13.197 ns | 1.08 | 0.04 | - | - | - | - |
| NeedsEscapingCurrent | 9 | -1 | 11.475 ns | 0.3124 ns | 0.3473 ns | 11.408 ns | 10.934 ns | 12.328 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 9 | -1 | 9.772 ns | 0.3826 ns | 0.4252 ns | 9.733 ns | 9.058 ns | 10.909 ns | 0.85 | 0.04 | - | - | - | - |
| NeedsEscapingBackFill_New | 9 | -1 | 16.270 ns | 1.2363 ns | 1.4237 ns | 15.821 ns | 14.476 ns | 18.352 ns | 1.42 | 0.12 | - | - | - | - |
| NeedsEscapingCurrent | 10 | -1 | 12.802 ns | 0.3269 ns | 0.3357 ns | 12.853 ns | 12.274 ns | 13.741 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 10 | -1 | 11.443 ns | 0.7532 ns | 0.8673 ns | 11.784 ns | 10.070 ns | 12.654 ns | 0.91 | 0.06 | - | - | - | - |
| NeedsEscapingBackFill_New | 10 | -1 | 14.779 ns | 0.4825 ns | 0.5557 ns | 14.732 ns | 13.998 ns | 15.937 ns | 1.15 | 0.05 | - | - | - | - |
| NeedsEscapingCurrent | 11 | -1 | 14.341 ns | 0.6091 ns | 0.6771 ns | 14.153 ns | 13.406 ns | 15.962 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 11 | -1 | 13.819 ns | 0.9048 ns | 1.0057 ns | 13.922 ns | 12.053 ns | 15.625 ns | 0.97 | 0.08 | - | - | - | - |
| NeedsEscapingBackFill_New | 11 | -1 | 15.823 ns | 0.7545 ns | 0.8689 ns | 15.679 ns | 14.482 ns | 17.757 ns | 1.10 | 0.08 | - | - | - | - |
| NeedsEscapingCurrent | 12 | -1 | 16.141 ns | 0.7545 ns | 0.8386 ns | 16.068 ns | 14.863 ns | 18.070 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 12 | -1 | 13.761 ns | 0.8433 ns | 0.9711 ns | 13.533 ns | 12.539 ns | 16.092 ns | 0.85 | 0.07 | - | - | - | - |
| NeedsEscapingBackFill_New | 12 | -1 | 15.607 ns | 0.6422 ns | 0.7396 ns | 15.459 ns | 14.540 ns | 17.284 ns | 0.97 | 0.06 | - | - | - | - |
| NeedsEscapingCurrent | 13 | -1 | 16.830 ns | 0.5668 ns | 0.6527 ns | 16.802 ns | 15.870 ns | 17.968 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 13 | -1 | 15.482 ns | 1.0933 ns | 1.1698 ns | 15.647 ns | 13.727 ns | 18.171 ns | 0.92 | 0.09 | - | - | - | - |
| NeedsEscapingBackFill_New | 13 | -1 | 15.220 ns | 0.5194 ns | 0.5982 ns | 15.183 ns | 14.068 ns | 16.489 ns | 0.90 | 0.03 | - | - | - | - |
| NeedsEscapingCurrent | 14 | -1 | 17.295 ns | 0.3962 ns | 0.4068 ns | 17.286 ns | 16.530 ns | 18.282 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 14 | -1 | 16.075 ns | 1.0214 ns | 1.1762 ns | 16.086 ns | 14.443 ns | 18.692 ns | 0.94 | 0.06 | - | - | - | - |
| NeedsEscapingBackFill_New | 14 | -1 | 15.367 ns | 0.8081 ns | 0.8982 ns | 15.374 ns | 13.909 ns | 17.068 ns | 0.89 | 0.05 | - | - | - | - |
| NeedsEscapingCurrent | 15 | -1 | 19.173 ns | 0.8490 ns | 0.9084 ns | 18.867 ns | 17.936 ns | 20.772 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 15 | -1 | 15.834 ns | 0.3529 ns | 0.3922 ns | 15.813 ns | 15.059 ns | 16.522 ns | 0.83 | 0.03 | - | - | - | - |
| NeedsEscapingBackFill_New | 15 | -1 | 14.575 ns | 0.5166 ns | 0.5949 ns | 14.416 ns | 13.751 ns | 16.156 ns | 0.76 | 0.04 | - | - | - | - |
| NeedsEscapingCurrent | 16 | -1 | 19.666 ns | 0.6339 ns | 0.7300 ns | 19.641 ns | 18.566 ns | 21.430 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 16 | -1 | 10.682 ns | 0.3242 ns | 0.3604 ns | 10.527 ns | 10.234 ns | 11.514 ns | 0.54 | 0.02 | - | - | - | - |
| NeedsEscapingBackFill_New | 16 | -1 | 11.398 ns | 0.3076 ns | 0.3419 ns | 11.435 ns | 10.806 ns | 12.170 ns | 0.58 | 0.02 | - | - | - | - |
| NeedsEscapingCurrent | 17 | -1 | 20.502 ns | 0.5045 ns | 0.5809 ns | 20.342 ns | 19.643 ns | 21.622 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 17 | -1 | 13.003 ns | 0.8819 ns | 1.0156 ns | 13.332 ns | 11.365 ns | 14.558 ns | 0.63 | 0.06 | - | - | - | - |
| NeedsEscapingBackFill_New | 17 | -1 | 18.021 ns | 1.1066 ns | 1.0868 ns | 18.265 ns | 16.467 ns | 19.709 ns | 0.88 | 0.07 | - | - | - | - |
| NeedsEscapingCurrent | 23 | -1 | 30.704 ns | 2.1582 ns | 2.4854 ns | 30.470 ns | 26.943 ns | 35.727 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 23 | -1 | 18.486 ns | 1.1722 ns | 1.3029 ns | 18.591 ns | 16.955 ns | 21.408 ns | 0.60 | 0.06 | - | - | - | - |
| NeedsEscapingBackFill_New | 23 | -1 | 16.181 ns | 0.3261 ns | 0.2546 ns | 16.278 ns | 15.710 ns | 16.424 ns | 0.52 | 0.04 | - | - | - | - |
| NeedsEscapingCurrent | 24 | -1 | 28.256 ns | 0.7450 ns | 0.8580 ns | 28.253 ns | 27.107 ns | 29.760 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 24 | -1 | 13.871 ns | 0.4326 ns | 0.4981 ns | 13.958 ns | 12.749 ns | 14.661 ns | 0.49 | 0.01 | - | - | - | - |
| NeedsEscapingBackFill_New | 24 | -1 | 14.986 ns | 0.6737 ns | 0.7488 ns | 14.837 ns | 13.582 ns | 16.694 ns | 0.53 | 0.03 | - | - | - | - |
| NeedsEscapingCurrent | 25 | -1 | 29.552 ns | 1.0059 ns | 1.1584 ns | 29.398 ns | 28.229 ns | 32.342 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 25 | -1 | 18.139 ns | 2.1858 ns | 2.5171 ns | 19.485 ns | 13.794 ns | 20.314 ns | 0.61 | 0.08 | - | - | - | - |
| NeedsEscapingBackFill_New | 25 | -1 | 20.058 ns | 0.4126 ns | 0.4415 ns | 20.079 ns | 19.283 ns | 20.993 ns | 0.68 | 0.03 | - | - | - | - |
| NeedsEscapingCurrent | 100 | -1 | 118.124 ns | 2.8988 ns | 3.2220 ns | 117.936 ns | 113.771 ns | 124.588 ns | 1.00 | 0.00 | - | - | - | - |
| NeedsEscapingNewFixed | 100 | -1 | 35.771 ns | 0.9760 ns | 1.1240 ns | 35.687 ns | 34.410 ns | 38.375 ns | 0.30 | 0.01 | - | - | - | - |
| NeedsEscapingBackFill_New | 100 | -1 | 41.861 ns | 1.0144 ns | 1.1275 ns | 41.690 ns | 40.308 ns | 44.438 ns | 0.35 | 0.01 | - | - | - | - |
There was a problem hiding this comment.
I don't think it's worth it.
After reading your results I think it isn't worth it, and stick with the simpler code.
Thanks for sharing the results.
But for the byte-case this could be more interesting, as there are % 16 elements to check.
To exxegerate it: "4 (that's the break-even point ...)" special-case the remainder and take the vectorized or sequential path 😉
There was a problem hiding this comment.
To exxegerate it: "4 (that's the break-even point ...)" special-case the remainder and take the vectorized or sequential path 😉
I considered that, but if the first character to escape is in the first 4, that too is slower when doing intrinsics (rather than sequential), since the sequential one bails early. So, I would have to special case the special case :)
| { | ||
| // Found at least one character that needs to be escaped, figure out the index of | ||
| // the first one found that needed to be escaped within the 8 characters. | ||
| idx += BitOperations.TrailingZeroCount(index) >> 1; |
There was a problem hiding this comment.
I think I remember you saying that we find the first element that needs to be escaped and pass that through to something else to do the encoding correct?
Does that then go and do its own string validation to find characters that need to be escaped?
There was a problem hiding this comment.
I think I remember you saying that we find the first element that needs to be escaped and pass that through to something else to do the encoding correct?
Yes.
Does that then go and do its own string validation to find characters that need to be escaped?
Not for the first N characters. It copies the characters as is up to the first index found and then calls S.T.E.W to do the rest of the work in a slow "character-by-character" processing (which I want to improve, separately, but that requires a larger change):
|
Any other feedback? |
(I'm thinking loud, and it is somewhat unrelated to this PR.) A inherently problem with this approach (find first element that needs to be escaped) is for instance if only the first element needs to be escaped, while the rest not, the code will iterate through the whole input in the sequential escaping loop, instead of just to escape the first and copy the rest. Maybe we should scan the input also from the end, to see if there is (another) portion that can be copied, thus minimizing the work done by the "escaper". Or to generalize the idea: split the input in chunks, so that the possibility for copying instead of looping over gets bigger. |
| goto Return; | ||
| } | ||
| idx += 8; | ||
| startingAddress += 8; |
There was a problem hiding this comment.
More a general question (as there will be no measurable difference in this method):
Is this loop construct (incrementing both idx and startingAddress) "better" than something that just increments one of both like
short* startingAddress = (short*)ptr;
short* endAddress = startingAddress + value.Length - 8;
while (startingAddress < endAddress)
{
Vector128<short> sourceValue = Sse2.LoadVector128(startingAddress);
// ...
startingAddress += 8
}
idx = (int)(endAddress - startingAddress); // wherever neededor just incrementing the index and derefencing with the index
short* startingAddress = (short*)ptr;
while (value.Length - 8 >= idx)
{
Vector128<short> sourceValue = Sse2.LoadVector128(startingAddress + idx);
// ...
idx += 8;
}Here in corefx all patterns are used, so I'm interested which one is prefered -- besides the fact that the difference for real-world-usage-loops will be within noise, the cpu has multiple execution ports, etc.
There was a problem hiding this comment.
Like you said, I don't think it matters all that much. I just wrote it that way because it was easier for me to reason about the bounds and I didn't have to update idx wherever it was being used, so the difference probably comes down to preference. But the alternatives you suggested would work fine as well, and on a different day I may have written it that way.
| public static int NeedsEscaping(ReadOnlySpan<byte> value, JavaScriptEncoder encoder) | ||
| #if BUILDING_INBOX_LIBRARY | ||
| private static readonly Vector128<short> s_mask_UInt16_0x20 = Vector128.Create((short)0x20); // Space ' ' | ||
|
|
There was a problem hiding this comment.
Nit: remove that empty line, same below for "Tilde". Then the vectors for char (respectively short) and sbyte are in blocks.
Or are these empty lines intentional?
There was a problem hiding this comment.
I put them there intentionally as they mark the "less than" and "greater than" characters that act as the bounds (they themselves don't need to be encoded). The others are characters that need to be encoded if found. However, I don't feel too strongly about it and can remove the extra lines.
| { | ||
| goto Return; | ||
| short* startingAddress = (short*)ptr; | ||
| while (value.Length - 8 >= idx) |
There was a problem hiding this comment.
For value.Length >= 16 did you consider packing into a byte-vector (with saturation), so 16 elements at once can be scanned?
Sse2 implies little-endian, so there should be no problems for that (endianess-wise).
The code for the byte-path can be reused (needs to be extracted to a method, so the loops remain independent).
Outline:
elements >= 16
pack two char-vectors to on byte-vector, check as bytes, transform back idx
elements >= 8 and the remainder from above
pack the one char-vector with a dummy char-vector to one byte-vector, same as above.
For the dummy char-vector use one that is known to not need escaping, e.g. Vector128.Create((short)'A').
elements < 8 and the remainder from above
sequential scan
There was a problem hiding this comment.
Tried this in https://github.com/gfoidl/corefx/commit/3b1922c2cab1bd60a89a72e2e15b0f11d4645a64
For small input the overhead is too high, for larger inputs it's faster.
benchmark results
| Method | TestStringData | Mean | Error | StdDev | Ratio | RatioSD |
|----------------------- |--------------- |---------:|----------:|----------:|------:|--------:|
| NeedsEscapingCurrentPR | 1, -1 | 10.26 ns | 0.0481 ns | 0.0427 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 1, -1 | 10.97 ns | 0.0455 ns | 0.0403 ns | 1.07 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 1, 0 | 10.30 ns | 0.0667 ns | 0.0592 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 1, 0 | 10.79 ns | 0.2245 ns | 0.2100 ns | 1.04 | 0.02 |
| | | | | | | |
| NeedsEscapingCurrentPR | 100, -1 | 77.95 ns | 0.5453 ns | 0.5101 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 100, -1 | 28.28 ns | 0.1341 ns | 0.1120 ns | 0.36 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 15, -1 | 21.73 ns | 0.2506 ns | 0.2344 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 15, -1 | 20.35 ns | 0.1453 ns | 0.1288 ns | 0.94 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 16, -1 | 17.94 ns | 0.1079 ns | 0.0957 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 16, -1 | 11.70 ns | 0.0390 ns | 0.0365 ns | 0.65 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 17, -1 | 19.26 ns | 0.1605 ns | 0.1502 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 17, -1 | 13.18 ns | 0.0340 ns | 0.0284 ns | 0.68 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 2, -1 | 11.43 ns | 0.0287 ns | 0.0269 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 2, -1 | 12.18 ns | 0.1658 ns | 0.1551 ns | 1.07 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 32, -1 | 26.47 ns | 0.1092 ns | 0.0968 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 32, -1 | 14.06 ns | 0.0918 ns | 0.0814 ns | 0.53 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 4, -1 | 13.70 ns | 0.0802 ns | 0.0711 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 4, -1 | 14.33 ns | 0.0611 ns | 0.0542 ns | 1.05 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, -1 | 17.12 ns | 0.1120 ns | 0.1048 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, -1 | 17.77 ns | 0.1273 ns | 0.1191 ns | 1.04 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, 0 | 10.26 ns | 0.0563 ns | 0.0499 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, 0 | 10.62 ns | 0.0696 ns | 0.0617 ns | 1.04 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, 1 | 11.39 ns | 0.0642 ns | 0.0569 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, 1 | 11.80 ns | 0.0403 ns | 0.0377 ns | 1.04 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, 2 | 12.57 ns | 0.0758 ns | 0.0709 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, 2 | 12.85 ns | 0.0707 ns | 0.0627 ns | 1.02 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, 3 | 13.68 ns | 0.0965 ns | 0.0902 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, 3 | 14.07 ns | 0.1104 ns | 0.1033 ns | 1.03 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, 4 | 14.80 ns | 0.0444 ns | 0.0394 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, 4 | 15.39 ns | 0.2170 ns | 0.2030 ns | 1.04 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, 5 | 15.88 ns | 0.0575 ns | 0.0509 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, 5 | 16.32 ns | 0.0760 ns | 0.0674 ns | 1.03 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 7, 6 | 17.07 ns | 0.1173 ns | 0.1097 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 7, 6 | 17.41 ns | 0.0618 ns | 0.0516 ns | 1.02 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, -1 | 13.65 ns | 0.0636 ns | 0.0531 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, -1 | 12.16 ns | 0.0460 ns | 0.0430 ns | 0.89 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 0 | 13.70 ns | 0.1083 ns | 0.1013 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 0 | 12.02 ns | 0.0529 ns | 0.0495 ns | 0.88 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 1 | 13.61 ns | 0.0503 ns | 0.0420 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 1 | 11.99 ns | 0.0531 ns | 0.0497 ns | 0.88 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 2 | 13.66 ns | 0.0927 ns | 0.0867 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 2 | 12.07 ns | 0.0559 ns | 0.0467 ns | 0.88 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 3 | 13.64 ns | 0.0661 ns | 0.0586 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 3 | 12.05 ns | 0.0525 ns | 0.0466 ns | 0.88 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 4 | 13.86 ns | 0.2429 ns | 0.2272 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 4 | 12.43 ns | 0.1654 ns | 0.1547 ns | 0.90 | 0.02 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 5 | 13.93 ns | 0.0942 ns | 0.0881 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 5 | 12.00 ns | 0.0999 ns | 0.0934 ns | 0.86 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 6 | 13.67 ns | 0.0711 ns | 0.0665 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 6 | 12.06 ns | 0.0583 ns | 0.0517 ns | 0.88 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 8, 7 | 13.68 ns | 0.0547 ns | 0.0427 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 8, 7 | 12.03 ns | 0.0366 ns | 0.0342 ns | 0.88 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 9, -1 | 14.87 ns | 0.1161 ns | 0.1029 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 9, -1 | 13.54 ns | 0.0464 ns | 0.0411 ns | 0.91 | 0.01 |
Will try to minimize the overhead...
There was a problem hiding this comment.
https://github.com/gfoidl/corefx/commit/b68062ee424118455cf95854c709a945f4fb187c -- it won't get any better
| Method | TestStringData | Mean | Error | StdDev | Ratio |
|----------------------- |--------------- |---------:|----------:|----------:|------:|
| NeedsEscapingCurrentPR | 1, -1 | 10.13 ns | 0.0801 ns | 0.0750 ns | 1.00 |
| NeedsEscapingBitMask | 1, -1 | 10.62 ns | 0.0289 ns | 0.0226 ns | 1.05 |
| | | | | | |
| NeedsEscapingCurrentPR | 1, 0 | 10.24 ns | 0.0296 ns | 0.0263 ns | 1.00 |
| NeedsEscapingBitMask | 1, 0 | 10.15 ns | 0.0511 ns | 0.0453 ns | 0.99 |
| | | | | | |
| NeedsEscapingCurrentPR | 2, -1 | 11.44 ns | 0.0473 ns | 0.0419 ns | 1.00 |
| NeedsEscapingBitMask | 2, -1 | 11.66 ns | 0.0330 ns | 0.0275 ns | 1.02 |
For me that would be acceptable.
PS: sorry for hijacking your PR 😉 (for today I'm finished...)
There was a problem hiding this comment.
The results here look promising. Please feel free to submit a follow up PR with the changes you want to explore and we can discuss the additional improvements there, along with the Ssse3 based implementation below :)
Running the set of benchmarks that I shared in the gist would be great, particularly the serializer ones (please share your findings).
Here's the json file mentioned in this benchmark (its a large JSON file, ~155 MB): https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee#file-test_serializingnuget-cs-L9
~ 5MB zip file containing a ~155 MB json file:
dotnet-core.zip
There was a problem hiding this comment.
I'll prepare a PR for this. Thanks for the json-file.
There was a problem hiding this comment.
@ahsonkhan for the serializer-benchmarks I have to follow https://github.com/dotnet/performance/blob/master/docs/benchmarking-workflow-corefx.md?
(FYI: code for PR is ready, benchmarks are outstanding -- the next days I may be out of office, so it can take some days until everything is ready to go)
| for (idx = 0; idx < value.Length; idx++) | ||
| Vector128<sbyte> mask = Sse2.CompareLessThan(sourceValue, s_mask_SByte_0x20); // Control characters, and anything above 0x7E since sbyte.MaxValue is 0x7E | ||
|
|
||
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x22)); // Quotation Mark " |
There was a problem hiding this comment.
There are quite a lot comparisons and ors (hence also a quite long raw-chain).
I have an approach that uses bit-masks, need to verify performance (later today).
It needs Ssse3 though. But the same approach could be used for the squential part.
Maybe this makes more sense together with https://github.com/dotnet/corefx/pull/41845/files#r336728111
I'll give an update here.
There was a problem hiding this comment.
I implemented the idea for the byte-path (as it's easier, and to get some numbers quickly).
Code (base on current state of this PR): https://github.com/gfoidl/corefx/commit/5b5f8c6a8ecb95dca9559c40e3f1cdc483ed45e2
Description
The basic idea is to to construct a bitmask, where 1 denotes the need for escaping, while 0 means no escaping needed. To select the correct bitmask, the input byte is split into the low- and high-nibble. Based on the low-nibble the bitmask is selected, and with the high-nibble the index in the bitmask is chosen.
One can illustrate this bitmask with the following image:
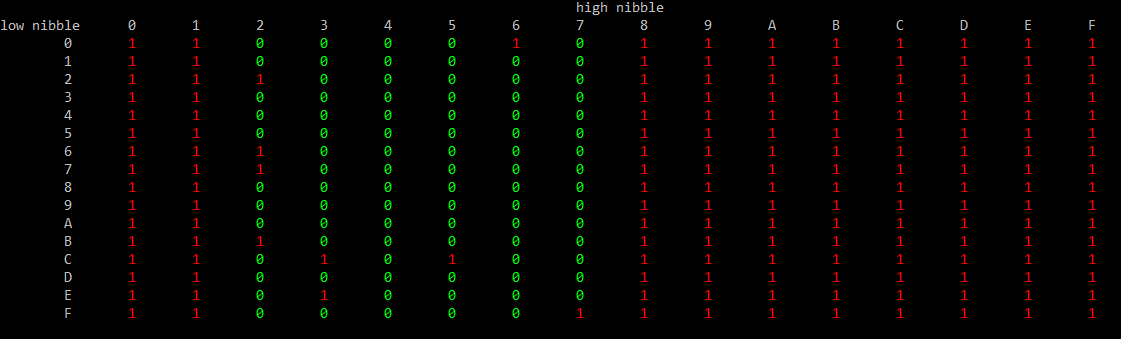
code to genate the matrix shown
using System;
using System.Collections.Generic;
namespace ConsoleApp3
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("\t\t\t\t\t\t\t\t\thigh nibble");
Console.Write("low nibble\t");
for (int j = 0; j <= 0xF; ++j)
{
Console.Write($"{j:X}\t");
}
Console.WriteLine();
for (int i = 0; i <= 0xF; ++i)
{
Console.Write($"\t{i:X}\t");
for (int j = 0; j <= 0xF; ++j)
{
int codePoint = j << 4 | i;
bool needsEscaping = NeedsEscaping(codePoint);
Console.ForegroundColor = needsEscaping
? ConsoleColor.Red
: ConsoleColor.Green;
Console.Write($"{(needsEscaping ? "1" : "0")}\t");
Console.ResetColor();
}
Console.WriteLine();
}
}
private static readonly HashSet<int> s_exclude = new HashSet<int>(new int[]
{
'"', '&', '\'', '+', '<', '>', '\\', '`'
});
private static bool NeedsEscaping(int value)
{
return value < ' '
|| value > '~'
|| s_exclude.Contains(value);
}
}
}Based on this "matrix" the bitmask is created -> https://github.com/gfoidl/corefx/blob/5b5f8c6a8ecb95dca9559c40e3f1cdc483ed45e2/src/System.Text.Json/src/System/Text/Json/Writer/JsonWriterHelper.Escaping.cs#L156-L173
A sequential version of the code looks like:
private static bool NeedsEscaping(byte value)
{
int highNibble = value >> 4;
int lowNibble = value & 0xF;
byte actualMask = Bitmask[lowNibble];
bool needsEscaping = ((1 << highNibble) & actualMask) != 0 || highNibble > 0x7;
return needsEscaping;
}Code-gen (differences)
The main-check-loop gets a lot smaller (I know, size is not the only measure):
G_M29314_IG07: ;; bbWeight=4
C4C17A6F2424 vmovdqu xmm4, xmmword ptr [r12]
C5D172D404 vpsrld xmm5, xmm4, 4
C5D1DBE8 vpand xmm5, xmm5, xmm0
C5D9DBE0 vpand xmm4, xmm4, xmm0
C4E27100E4 vpshufb xmm4, xmm1, xmm4
C4E26900ED vpshufb xmm5, xmm2, xmm5
C5D1DBE4 vpand xmm4, xmm5, xmm4
C5D964E3 vpcmpgtb xmm4, xmm4, xmm3
C5F9D7C4 vpmovmskb eax, xmm4
85C0 test eax, eax
7542 jne SHORT G_M29314_IG12
G_M29314_IG08: ;; bbWeight=4
4183C710 add r15d, 16
4983C410 add r12, 16
453BEF cmp r13d, r15d
7DC6 jge SHORT G_M29314_IG07as opposed to the masking-approach in this PR
G_M29314_IG07: ;; bbWeight=4
F3450F6F0C24 movdqu xmm9, xmmword ptr [r12]
440F28D0 movaps xmm10, xmm0
66450F64D1 pcmpgtb xmm10, xmm9
450F28D9 movaps xmm11, xmm9
66440F74D9 pcmpeqb xmm11, xmm1
66450FEBD3 por xmm10, xmm11
450F28D9 movaps xmm11, xmm9
66440F74DA pcmpeqb xmm11, xmm2
66450FEBD3 por xmm10, xmm11
450F28D9 movaps xmm11, xmm9
66440F74DB pcmpeqb xmm11, xmm3
66450FEBD3 por xmm10, xmm11
450F28D9 movaps xmm11, xmm9
66440F74DC pcmpeqb xmm11, xmm4
66450FEBD3 por xmm10, xmm11
450F28D9 movaps xmm11, xmm9
66440F74DD pcmpeqb xmm11, xmm5
66450FEBD3 por xmm10, xmm11
450F28D9 movaps xmm11, xmm9
66440F74DE pcmpeqb xmm11, xmm6
66450FEBD3 por xmm10, xmm11
450F28D9 movaps xmm11, xmm9
66440F74DF pcmpeqb xmm11, xmm7
66450FEBD3 por xmm10, xmm11
66450F74C8 pcmpeqb xmm9, xmm8
66450FEBD1 por xmm10, xmm9
66410FD7C2 pmovmskb eax, xmm10
85C0 test eax, eax
7540 jne SHORT G_M29314_IG12
G_M29314_IG08: ;; bbWeight=4
4183C710 add r15d, 16
4983C410 add r12, 16
453BEF cmp r13d, r15d
0F8D6BFFFFFF jge G_M29314_IG07Benchmark-Results
Benchmark-code based on https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee#file-test_escapingbenchmark-cs
In the results I stripped of the ones for the sequential path, as they are equal (it's the same code-path used).
| Method | TestStringData | Mean | Error | StdDev | Ratio | RatioSD |
|----------------------- |--------------- |----------:|----------:|----------:|------:|--------:|
| NeedsEscapingCurrentPR | 100, -1 | 36.110 ns | 0.3919 ns | 0.3474 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 100, -1 | 26.421 ns | 0.4391 ns | 0.4107 ns | 0.73 | 0.02 |
| | | | | | | |
| NeedsEscapingCurrentPR | 15, -1 | 21.821 ns | 0.1093 ns | 0.1022 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 15, -1 | 21.769 ns | 0.0974 ns | 0.0863 ns | 1.00 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 16, -1 | 13.148 ns | 0.0447 ns | 0.0396 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 16, -1 | 11.580 ns | 0.0190 ns | 0.0168 ns | 0.88 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 17, -1 | 13.861 ns | 0.0410 ns | 0.0342 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 17, -1 | 12.344 ns | 0.0284 ns | 0.0237 ns | 0.89 | 0.00 |
| | | | | | | |
| NeedsEscapingCurrentPR | 32, -1 | 17.290 ns | 0.0554 ns | 0.0491 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 32, -1 | 13.878 ns | 0.0854 ns | 0.0799 ns | 0.80 | 0.01 |
| | | | | | | |
| NeedsEscapingCurrentPR | 9, -1 | 16.961 ns | 0.0853 ns | 0.0798 ns | 1.00 | 0.00 |
| NeedsEscapingBitMask | 9, -1 | 16.855 ns | 0.0837 ns | 0.0742 ns | 0.99 | 0.01 |
@ahsonkhan how did you run the benchmarks with escaping needed? (I'm stuck in the benchmark-code and don't want to explode the things 😉)
Discussion
The results meet my expectations so far, as the loop is tighter and the raw is mostly broken up.
It adds a bit of complexity, as there is a path for SSE2 and one for SSSE3.
Is this something to pursue?
If this should be productized, more comments are needed, of course.
There was a problem hiding this comment.
how did you run the benchmarks with escaping needed?
I ran this benchmark.
https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee#file-test_escapingbenchmark-cs-L1
For input lengths 1, 7, and 8, it adds a character that needs to be escaped at index i (from 0 to length).
https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee#file-test_escapingbenchmark-cs-L31-L32
| { | ||
| // Found at least one byte that needs to be escaped, figure out the index of | ||
| // the first one found that needed to be escaped within the 16 bytes. | ||
| idx += BitOperations.TrailingZeroCount(index | 0xFFFF0000); |
There was a problem hiding this comment.
Is there a specific reason for the long-overload and not the uint one?
The long-overload uses the intrinsic only for x64?
| idx += BitOperations.TrailingZeroCount(index | 0xFFFF0000); | |
| idx += BitOperations.TrailingZeroCount(index); |
There was a problem hiding this comment.
Good point. It was necessary when I didn't have the index != 0 check (otherwise, trailing zero count would be 32 instead of 16, when index == 0 and that's why the bit-wise or was needed). Removed it.
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x3E)); // Greater Than Sign > | ||
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x5C)); // Reverse Solidus \ | ||
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x60)); // Grave Access ` | ||
|
|
There was a problem hiding this comment.
The ~ (greater than) is missing here?
Cf. char-code
There was a problem hiding this comment.
Nope, I need the ~ (tilde) for the char code, but don't need it for utf-8 bytes.
That's because I am reading the data as Vector<sbyte> (signed byte) and anything above 0x7E would be negative and hence covered by the less than 0x20 check.
See comment here:
// Control characters, and anything above 0x7E since sbyte.MaxValue is 0x7E
|
Unrelated CI failure: https://github.com/dotnet/corefx/issues/28805 |
| #if BUILDING_INBOX_LIBRARY | ||
| private static readonly Vector128<short> s_mask_UInt16_0x20 = Vector128.Create((short)0x20); // Space ' ' | ||
|
|
||
| private static readonly Vector128<short> s_mask_UInt16_0x22 = Vector128.Create((short)0x22); // Quotation Mark '"' |
There was a problem hiding this comment.
Should these be ushort instead of short? Since we do < or > and a non-ascii character may be negative. Do we have tests for this (surrogate char which is >= 0x8000)
Update: for a surrogate char I believe the next char is always < 0x8000 and > 0xFF (unless invalid text) so we're probably OK using short. However using ushort may be less ambiguous.
There was a problem hiding this comment.
We need to use short since that's what the intrinsics I am using support (such as Sse2.CompareEqual).
Negative is fine here, since that would get caught be the < 0x20 check and there is no char/ushort value that circles back around to the same sign when casted as short.
The range 32768 (short.MaxValue + 1) to 65535 (char.MaxValue) all fits into the negative range for a short (from -1 to -32768).
for a surrogate char I believe the next char is always < 0x8000 and > 0xFF
I don't know what you mean. Surrogate chars have to be in high-low pairs (for valid text) where the high-surrogate followed by a low-surrogate being 0xD800–0xDBFF and low being 0xDC00–0xDFFF.
Do we have tests for this (surrogate char which is >= 0x8000)
I'll add a test for a character >= 0x8000 (but those won't be surrogates, since surrogates require two characters to represent).
There was a problem hiding this comment.
We need to use short since that's what the intrinsics I am using support (such as Sse2.CompareEqual).
But there is an overload of CompareEqual for ushort as well.
Negative is fine here, since that would get caught be the < 0x20 check and there is no char/ushort value that circles back around to the same sign when casted as short.
That doesn't seem intuitive. There is also a comparison for >0x7E
I don't know what you mean. Surrogate chars have to be in high-low pairs (for valid text) where the high-surrogate followed by a low-surrogate being 0xD800–0xDBFF and low being 0xDC00–0xDFFF.
A low surrogate is always negative w.r.t. signed short.
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x3C)); // Less Than Sign < | ||
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x3E)); // Greater Than Sign > | ||
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x5C)); // Reverse Solidus \ | ||
| mask = Sse2.Or(mask, Sse2.CompareEqual(sourceValue, s_mask_SByte_0x60)); // Grave Access ` |
There was a problem hiding this comment.
So intrinsics are faster because the number of Sse2 operations \ special casing is low here... (v.s. the current bit mask). I wonder what the break-even point is?
There was a problem hiding this comment.
There are quite a lot comparisons and ors (hence also a quite long raw-chain).
I have an approach that uses bit-masks, need to verify performance (later today).
@gfoidl we actually have a hard-coded bitmask already that we use for ASCII. Yes using that instead of Sse2Or seems to be the best solution.
There was a problem hiding this comment.
The bitmask I refer to is https://github.com/gfoidl/corefx/blob/5b5f8c6a8ecb95dca9559c40e3f1cdc483ed45e2/src/System.Text.Json/src/System/Text/Json/Writer/JsonWriterHelper.Escaping.cs#L156-L173
we use for ASCII
Can you point me to that, please? So far I didn't find one that matches with my idea.
(Anyway, I'm preparing a PR as @ahsonkhan suggested, well see then there.).
There was a problem hiding this comment.
we actually have a hard-coded bitmask already that we use for ASCII
Can you point me to that, please?
I believe @steveharter is referring to what's currently in master. Looks like you both are referring to two different things here :)
Yes using that instead of
Sse2Orseems to be the best solution.
That's not true. We get substantial perf wins using Sse2 operations. Keep in mind, all these operations are not happening per character, but per 8 characters.
I wonder what the break-even point is?
I shared the perf comparison of "current" (which uses the hard-coded bit-mask for ASCII) vs "alternatives/this PR" in the PR description:
https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee
Using intrinsics is always faster (so you could think of a break-even point as 8 which is when we start using intrinsics). We do have a ~10-15% regression for strings <= 7 characters because of the extra length check (but in absolute terms that's in the 1 ns range).
There was a problem hiding this comment.
That's not true. We get substantial perf wins using Sse2 operations. Keep in mind, all these operations are not happening per character, but per 8 characters.
I was referring to @gfoidl NeedsEscapingSsse3 example which is appears faster than the SSe2 (and was not referring to the current implementation that doesn't use SSe2). Perhaps SSS3 isn't as common as SSe2 so we should use SSe2 instead (or use SSs3 if available).
There was a problem hiding this comment.
SSE3 was introduced in 2004 and SSSE3 was introduced in 2006. It is reasonable to expect that the vast majority of users running .NET Core would have this support and it is therefore beneficial to include a code-path for it.
There was a problem hiding this comment.
Makes sense @tannergooding
@steveharter - gotcha. And agreed. I will let @gfoidl drive that change and do the perf testing to evaluate its feasibility and we can discuss its merit over that PR. I want to remove this code from S.T.Json first though (especially for porting to 3.1), so the optimization and the escaping logic can solely live in S.T.E.Web.
There was a problem hiding this comment.
With #42023 I'm having a look how this bitmask-approach can be incorporated in S.T.E.Web, and not in S.T.Json. If not possible I'll target S.T.Json.
There was a problem hiding this comment.
I'm having a look how this bitmask-approach can be incorporated in S.T.E.Web, and not in S.T.Json
Sounds good. Look at the concrete types that implement JavaScriptEncoder since those are what will get used more often.
I'd say the following would be most common (with TextEncoder or a custom JavascriptEncoder being quite uncommon, not worth optimizing):
JavaScriptEncoder.Default- used by defaultJavaScriptEncoder.UnsafeRelaxedJsonEscaping- used by default within aspnetJavaScriptEncoder.Create(UnicodeRanges.All)- used by folks who want non-ascii text left unescaped
If not possible I'll target S.T.Json.
I would prefer not to have encoding specific logic duplicated in S.T.Json, so let's try to avoid that if possible (let me know if you get blocked because of this for some reason, because my assumption is whatever was feasible in S.T.Json is also feasible in S.T.E.W).
|
Unrelated test failure on netfx ( |
…N strings (dotnet#41845) * Use Sse2 instrinsics to make NeedsEscaping check faster for large strings. * Update the utf-8 bytes needsescaping and add tests. * Remove unnecessary bitwise OR and add more tests * Add more tests around surrogates, invalid strings, and characters > short.MaxValue.
|
Did someone explicitly signoff before merging? @tannergooding ? |
|
This change was largely reverted once the optimization was moved into S.T.E.W (other than keeping the tests) in #42023. The change that really matters is #41933. I got offline approval from @steveharter. That said, explicit approval would be nice :) |
src/System.Text.Json/src/System/Text/Json/Writer/JsonWriterHelper.Escaping.cs
Show resolved
Hide resolved
src/System.Text.Json/src/System/Text/Json/Writer/JsonWriterHelper.Escaping.cs
Show resolved
Hide resolved
src/System.Text.Json/src/System/Text/Json/Writer/JsonWriterHelper.Escaping.cs
Show resolved
Hide resolved
| if (Sse2.IsSupported) | ||
| { | ||
| sbyte* startingAddress = (sbyte*)ptr; | ||
| while (value.Length - 16 >= idx) |
There was a problem hiding this comment.
it would probably be more efficient to just calculate the ending address and compare against that as currentAddress is incremented...
There was a problem hiding this comment.
This was brought up earlier:
#41845 (comment)
I don't think it mattered, but I can try again to verify.
|
@tannergooding - outside of some of the cosmetic feedback you provided, is there anything else (potentially blocking) here? |
…N strings (dotnet/corefx#41845) * Use Sse2 instrinsics to make NeedsEscaping check faster for large strings. * Update the utf-8 bytes needsescaping and add tests. * Remove unnecessary bitwise OR and add more tests * Add more tests around surrogates, invalid strings, and characters > short.MaxValue. Commit migrated from dotnet/corefx@7cae92b
Here's the whole analysis and experimentation of different alternatives with benchmark results: https://gist.github.com/ahsonkhan/c566f5e7d65c1fde5a83a67be290c4ee
Ignore the uap target changes (they were borrowed from #41759) since it was happening anyway and I am not yet sure if its worth the effort to create different constants for uap (since intrinsics aren't built for that configuration).
Here's the conclusion and next steps.
Conclusions:
Here's a summary of the results when the user doesn't customize the encoder via the
JsonSerializerOptionsorJsonWriterOptions(i.e. uses the default encoder behavior).Next Steps:
1) Add similar support and tests for UTF-8 bytes, not just UTF-16 characters.2) Evaluate if the trade-off is worth it for property names which tend to be small (2-8 characters), compared to values.
3) Consider optimizing the commonly used built-inSee #41933JavascriptEncoderstatics using similar techniques.4) Apply non-Sse2 based optimizations where Sse2 isn't supported rather than processing one character at a time.
5) Rather than returning the first index to escape, return the whole mask and escape all characters that need to be escaped at once (within the block of 8) and return back to the "fast" non-escaping path, rather than writing one character at a time whenever a single character is found that needs escaping.
cc @steveharter, @tannergooding, @GrabYourPitchforks