Introduced time-based concurrent compaction #2616
Closed
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Signed-off-by: Marco Pracucci <[email protected]>
e143871 to
58d378b
Compare
Signed-off-by: Marco Pracucci <[email protected]>
Contributor
Author
|
Closing while waiting for upstream changes. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
1 participant
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What this PR does:
Few days ago we introduced blocks sharding in the compactor (#2599) and it gave us significant benefits compacting a large tenant blocks (30M active series before replication). However, the blocks sharding approach brings also a major downside: the samples deduplication is significantly less effective (ie. we mesured that with a RF=3 and shards=3 we deduplicate about 45% of samples, and the situation gets worse for more shards).
After some experimentation, in this PR I'm proposing a different strategy. The idea is to accept the fact that to compact 2h blocks it will take more than 2h, but we should be able to concurrently run multiple compactions for non-overlapping ranges (if available).
How it works: I've replaced the TSDB compactor planner with a custom one and I've done some changes in Thanos to be able to inject a custom "blocks grouping" logic. Basically, the
Grouperis responsible to create groups of blocks that should be compacted together and thus the TSDBPlan()is just a pass-through because the planning already occurred in the grouping.This is a first step. The way the grouper works makes it relatively easy to shard planned groups across multiple nodes using the same ring we use to shard by tenant. This will be done in a future PR.
This PR is a draft because:
Grouperrefactoring in Thanos firstNotes to reviewers:
-compactor.consistency-delaydefault to0sbecause it should be fine for consistent object stores. This change is not strictly related to this PR changes, but it's somewhat desiderable to reduce the chances of having to re-compact the same range twice.We're already testing this change with the large customer and so far it looks working fine. Ie. given
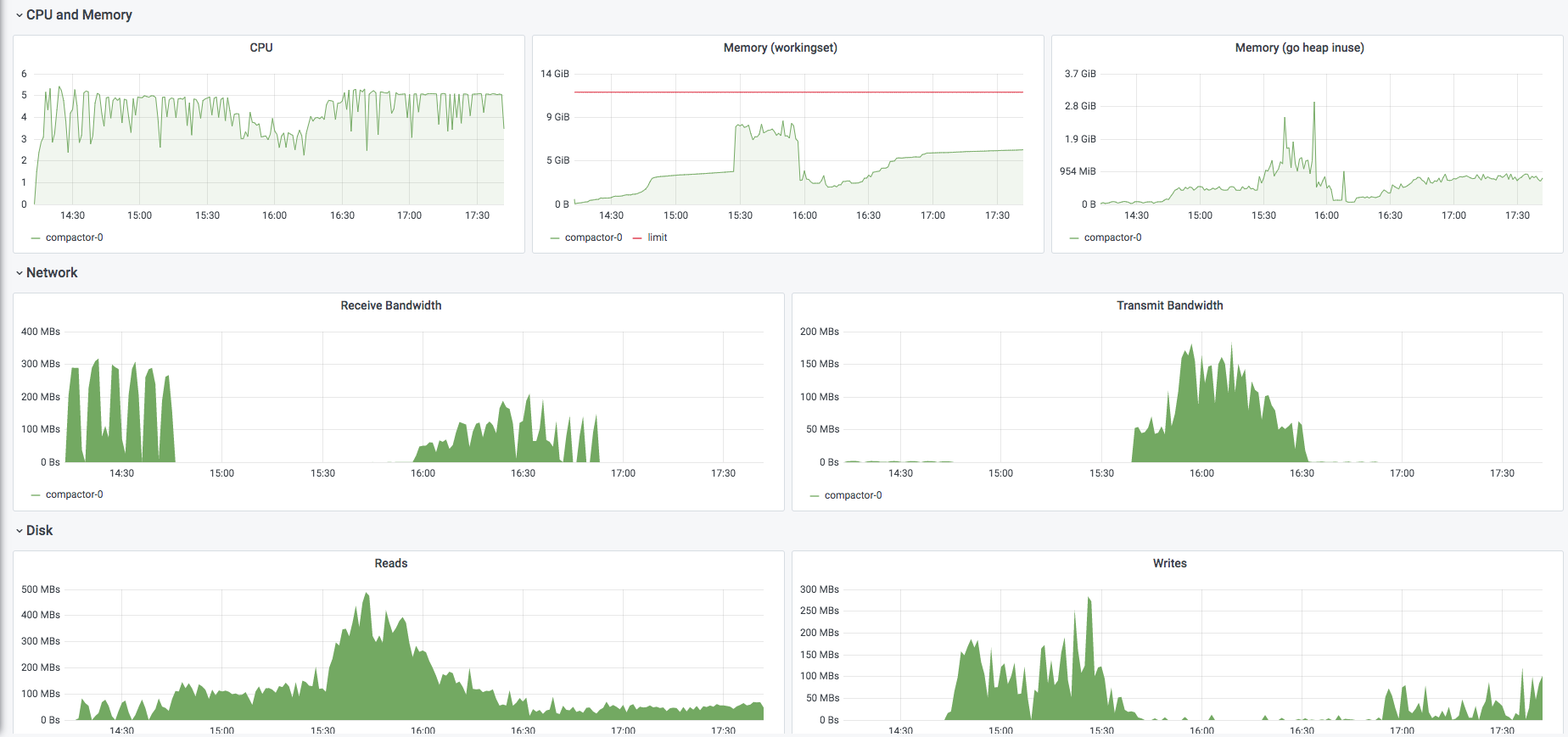
-compactor.compaction-concurrency=5we're able to max out 5 CPU cores most of the time (each compaction is single threaded so it uses at most 1 core):Which issue(s) this PR fixes:
N/A
Checklist
CHANGELOG.mdupdated - the order of entries should be[CHANGE],[FEATURE],[ENHANCEMENT],[BUGFIX]