Ocropy segmentation, squared #47
Conversation
(instead of doing ad-hoc binarization, which is either redundant and thus wastes time, or may be a suboptimal workflow choice)
(by using Shapely instead of CV2 to simplify polygons)
If level-of-operation=region, then recurse into text regions within table regions, finding text lines. If a table does not have any text regions yet, then add one pseudo-block to it which covers the whole table (and recurse into that, but in fullpage mode to also detect h/v-lines and white space columns).
- morph.all_neighbors:
- fix return value (keep pairs)
- add kwarg bg to skip
- use true shift instead of roll,
and fill with bg
- add kwarg dist for arbitrary distance
- psegutils.compute_boxmap:
break loop earlier (faster)
- make fg h/v-line detection more robust to
non-contiguous or slightly skewed/bent shapes,
as well as overlapping/touching glyphs:
- compute_separators_morph: better algorithm
based on a sequence of vertical/horizontal
open and close operations, combined with
binary reconstruction/seedfill
- remove_hlines: deprecate
- compute_hlines: new implementation analoguous
to compute_separators_morph
- return slightly dilated (enlarged) masks
to facilitate annotating polygon contours
(besides immediately suppressing foreground)
- improve bg column separator detection:
- vertically dilate gradient edges before
(not after) combining with thresholded whitespace
- run after (not before) removing v-lines
- call scale estimation with zoom parameter
(making this central measure itself become
DPI-relative)
- revise earlier doubling of estimated scale:
now only necessary for compute_line_seeds
(but not for separator and gradmap estimation);
- compute_line_seeds:
- use vscale=2
- respect colseps early on
- hmerge_line_seeds: more robust
based on morphology and consistency of center point
(y center inside other's bbox, but
x center not inside other's bbox),
not only global overlap counts
- rename compute_line_labels back to compute_segmentation
- also improve spreading line seeds to background:
- watch fg components: split seed conflicts,
but keep others on their majority side
- simplify (much faster)
- lines2regions: new implementation:
instead of bottom-up bbox matching/merging rules,
combine adjacent lines by morphologically closing
while splitting at fg h/v-line and bg colseps
- improve documentation
- use type-check decorators (as in ocrolib proper)
- uncomment all DSAVE statements,
but disable function via decorator
(as single place to re-enable all
file-based or interactive plots)
- introduce/pass new ocrd-tool parameters
- hlminwidth (minimum length of h-lines,
in multiples of scale)
- csminheight (minimum length of v-lines,
in multiples of scale)
- after page segmentation, also add
detected text lines below text regions
- do not give up when a contour retains too small a share of the background (only foreground is relevant for threshold)
- common.compute_segmentation:
- read binary image instead of grayscale-normalized
- pass in external separator mask to be combined
with detected separators
- move sanity checks to common.check_*
- segment:
- aggregate all previously existing regions,
including text regions/lines (except when
removing them anyway via `overwrite`),
and suppress them in the foreground
while doing line segmentation; moreover,
pass any separators among them extra
(to guide region segmentation)
- when `level-of-operation=page`, after
suppressing existing tables, iterate
through them and if they do not contain
text regions (cells) yet, segment them
into regions and lines likewise
- README: update
- common.compute_segmentation with fullpage (for segment on page level): prevent sepmask (from h/v-lines and colseps) from being filled when spreading line seeds into background by provisionally attaching a label for it and spreading it against the other line labels - common.compute_line_seeds: skip aggregating height statistics for warnings of large lines (too slow)
- when adding text regions to pages or tables, also add to (recursive) ReadingOrder in the order of region labels; - when indexed, start from existing elements; - when adding cells to a table, convert RegionRef(Indexed) to an equally located OrderedGroup(Indexed)
- instead of silently segmenting existing tables when running on page level, now simply ignore tables (like any other non-text regions), but offer a dedicated table level, which ignores text regions (like any other non-table regions), and only segments tables without existing cells - add overwrite_separators=True on page level (for finding separators via ocrolib instead of ignoring existing separator regions)
- uniform_filter based dilate/erode/open/close: replace exact zero with approx infinitesimal to avoid artifacts from rounding - all: correct pixel origin depending on even/odd filter size to avoid asymmetric results as best as possible (even kernel sizes of course will still cause asymmetry, but to a lesser extent)
- morph.reading_order: instead of providing only plain y.start top-down ordering, add this combined strategy doing both - y.center top-down but also - y.overlaps x.non-overlaps left-right and also offer the reverse (bottom-up, right-left) - sl: add missing functions: - compose: slice the slice! - xcenter_in / ycenter_in - top / bottom / left / right
- compute_images:
new function to detect and suppress large foreground
objects early on that are not h/v-lines
(and _not_ search for h/v-lines or assign text lines
within them);
this could be true graphics/photos/figures, but also
drop-capitals
- compute_hlines / compute_separators_morph:
reconstruct after opening by length not by keeping
any overlapping component, but only up to a certain
distance (to avoid overlapping glyphs but still get
most of the line's parts);
ignore parts that already belong to image components
identified by compute_images (so they don't compete
in n-best race)
- compute_colseps_conv:
- don't blur away small/protruding glyphs below fg/bg threshold
- don't use cleaned but raw boxmap (again) to avoid
marking small fg as bg
- compute_segmentation:
filter out line labels that only have noise fg (i.e.
components that have been filtered as too small/large)
- ensure odd kernel sizes everywhere
- DSAVE (visualization for debugging):
use uniformly bright and maximally differentiating
colormap, and set off 0 (background) to black;
allow passing a second array with foreground as white
- lines2regions: instead of bbox consistency heuristics, implement a hybrid recursive X-Y cut segmentation, which not only considers horizontal/vertical gaps in foreground (discounting noise pixels), but also avoids splitting line labels, and uses the detected/pass-in separators to alternatively cut at non-rectangular partitions instead of horizontal/vertical gaps - sort all line labels, gap-based slices and separator-based partitions via proper (top-down left-to-right, or reversed) reading order
- add an ImageRegion for each image found by compute_segmentation
- follow-up on 4bb1ddb (incremental annotation):
during line segmentation, merely suppress neighbouring/other
existing segments, but during region segmentation, pass
separators as sepmask but other regions as pseudo-line labels
to be identified within reading order;
afterwards, re-identify them (to avoid adding new elements,
but still reference them accordingly in the reading order group)
- follow-up on 7748ca4 (add reading order):
- reference each region in the ReadingOrder, increasing
@index when in an OrderedGroup(Indexed) (on Page
or in TableRegion)
- for TableRegions, replace existing RegionRef(Indexed)
by an equally indexed OrderedGroup(Indexed) to hold
all the cell regions
- do the right thing in ReadingOrder even when
`overwrite_regions=True`
- for all pre-existing and new-found separators and images, create a derived image where they are suppressed (white) - write that image (with `clipped` in @comments) to the second output file group (or `OCR-D-IMG-CLIP`)
|
This pull request introduces 10 alerts and fixes 2 when merging f242984 into 48a89e9 - view on LGTM.com new alerts:
fixed alerts:
|
Example A
|


















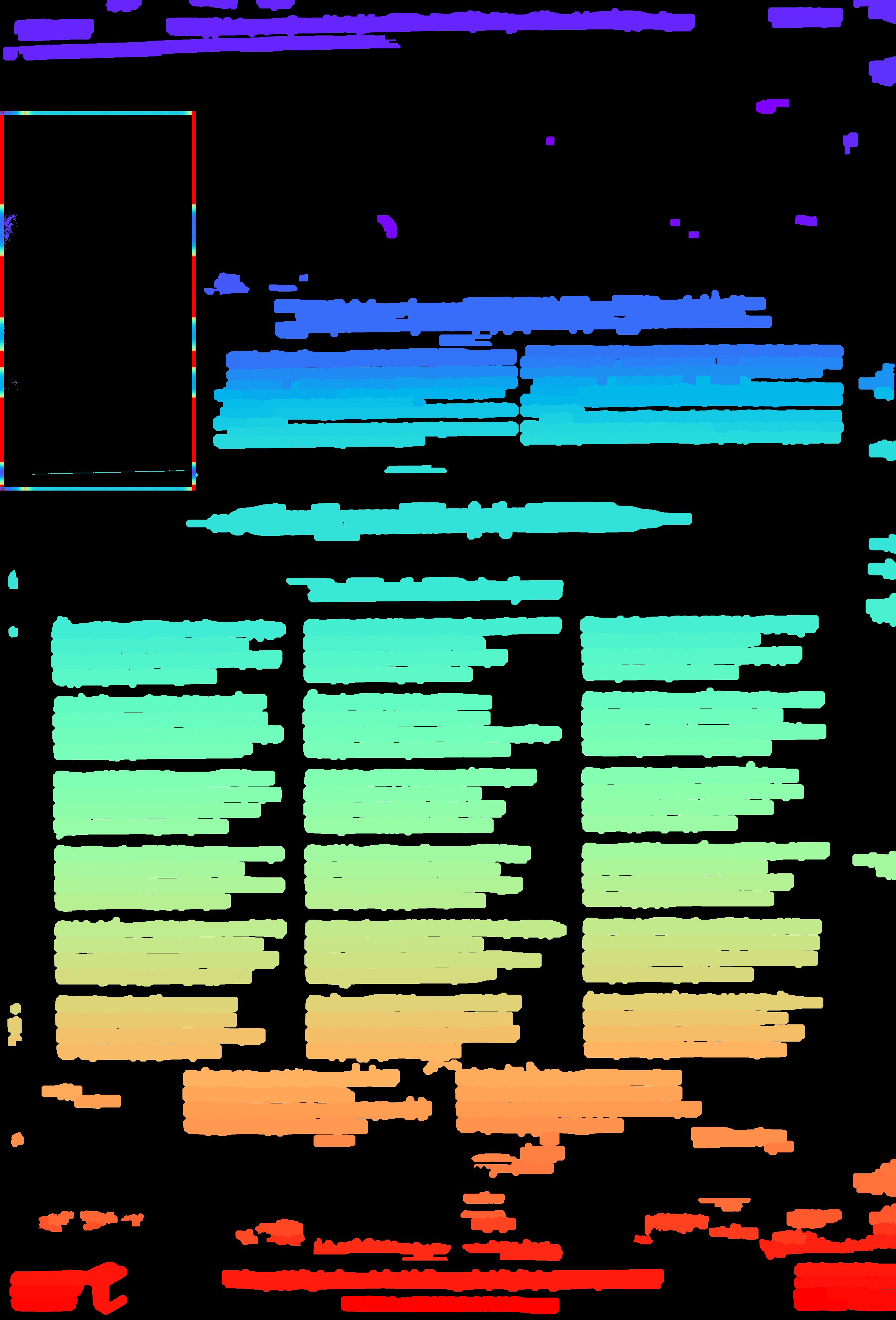








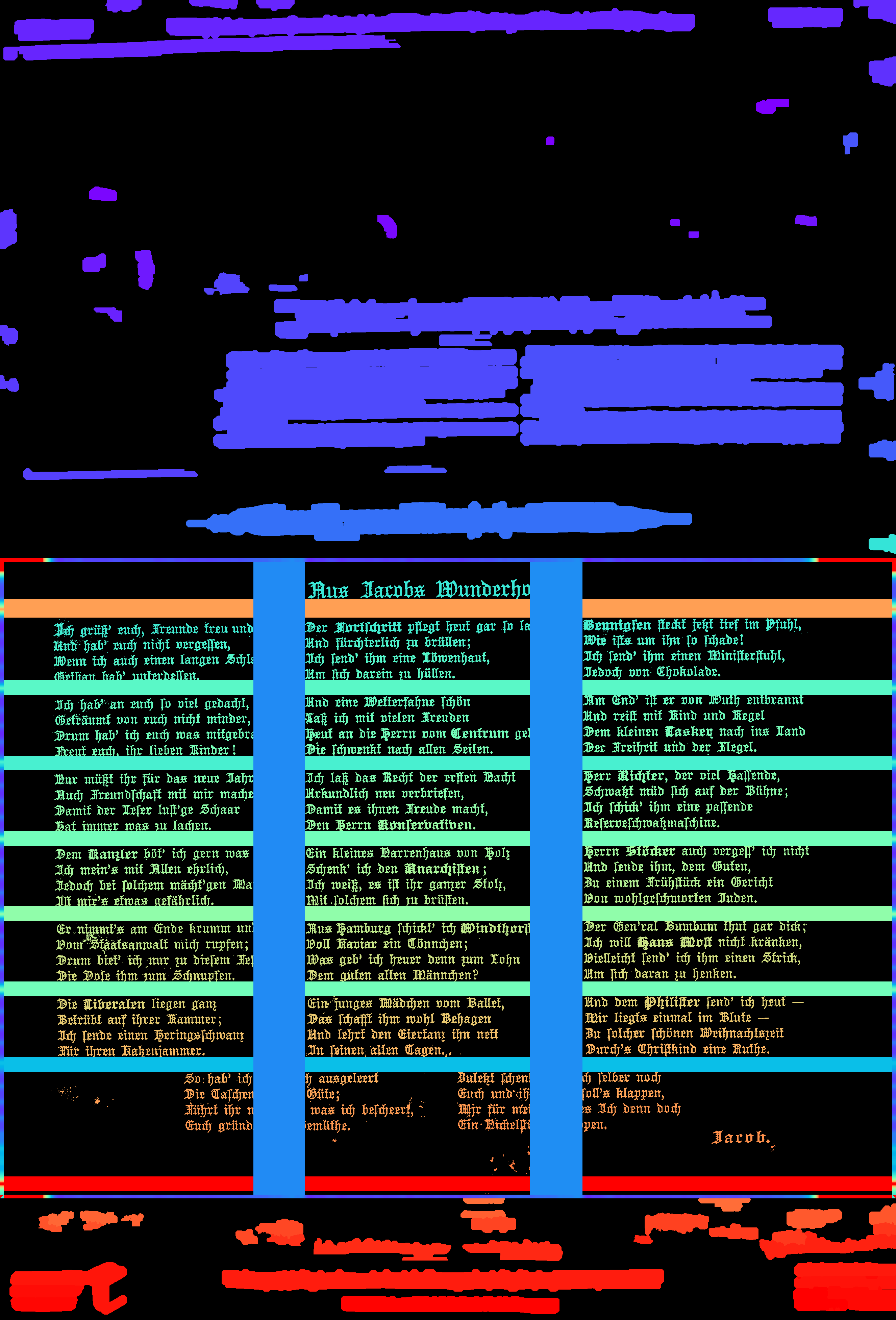



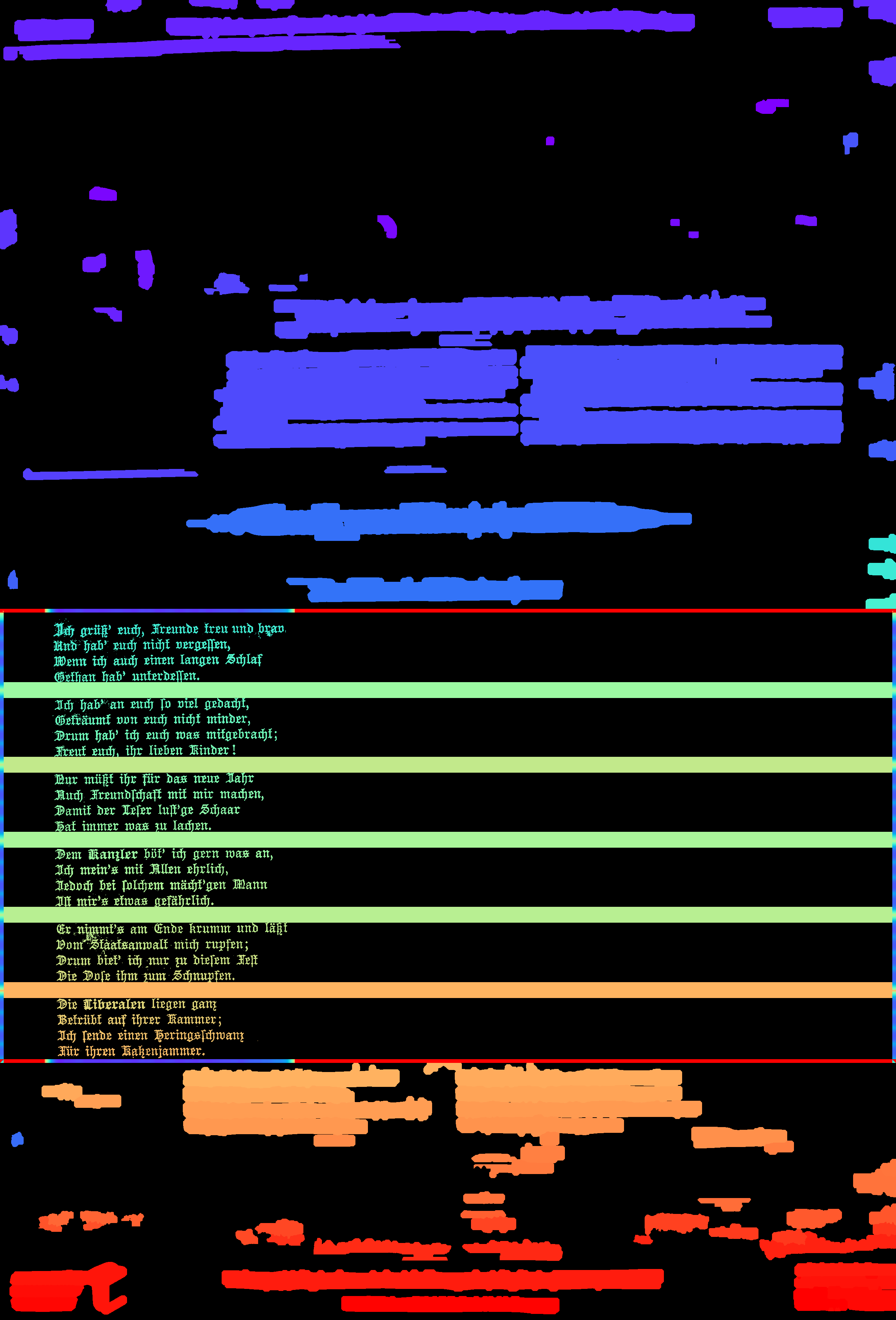










Example B
|















Example C
|




























|
One word about performance: I should also mention that there are quite a few parameters to control page segmentation. I have no idea how general my defaults are though. If you get strange results, look at the number and length of lines to be detected, number of images to be detected, and especially Or activate the ocrd_cis/ocrd_cis/ocropy/common.py Lines 389 to 390 in f242984 |
|
This pull request introduces 6 alerts and fixes 3 when merging 907c00f into 48a89e9 - view on LGTM.com new alerts:
fixed alerts:
|
907c00f to
32786a6
Compare
|
This pull request introduces 1 alert and fixes 3 when merging 32786a6 into 48a89e9 - view on LGTM.com new alerts:
fixed alerts:
|
|
This pull request introduces 1 alert and fixes 3 when merging b505d65 into 48a89e9 - view on LGTM.com new alerts:
fixed alerts:
|
This is a major rework of Ocropy's rule-based segmentation.
It greatly improves the situation with some long-standing problems, among them…
…but also offers solutions to unchartered terrain (for ocropus/ocrolib, that is)…
The OCR-D processor most affected by this is
ocrd-cis-ocropy-segment(now with a usablelevel-of-operation=pageand a newlevel-of-operation=table), and to a lesser extentocrd-cis-ocropy-resegment.For the details, see changelog of the individual commits.
Here's from the
segmentprocessor docstring:(Example images following shortly.)