[SPARK-38160][SQL] Shuffle by rand could lead to incorrect answers when ShuffleFetchFailed happend #35460
Conversation
|
@cloud-fan @maropu Can you please help review this? |
|
Can one of the admins verify this patch? |
|
also cc @srowen @viirya @yaooqinn I found there is a similar report before https://issues.apache.org/jira/browse/SPARK-24607 |
|
Isn't this why you shouldn't partition, shuffle, etc on some random value? use a hash? |
The data analyst may always have various needs such as Both of these sqls will generate a If we don't support shuffle by random value, we should disable this. |
|
Right, shouldn't we reject it? distributing by "hash(ID)" or similar makes more sense, not least of which because it is reproducible and deterministic across runs and environments |
Reject it maybe not a good idea.
|
|
If there is a fetch failure and the parent stage is |
Thanks for your reference. That's what I do in this MR for SparkSQL. |
|
I was not referring to the SQL changes per se @WangGuangxin, will let @srowen or @cloud-fan, etc review that. |
| /** | ||
| * Checks if the shuffle partitioning contains indeterminate expression/reference. | ||
| */ | ||
| private def isPartitioningIndeterminate(partitioning: Partitioning, plan: SparkPlan): Boolean = { |
There was a problem hiding this comment.
I think we need to build a framework to properly propagate the column-level nondeterministic information. This function looks quite fragile
There was a problem hiding this comment.
For example, Filter(rand_cond, Project(a, b, c, ...)). I think all the columns are nondeterministic after Filter, even though attributes a, b and c are deterministic.
There was a problem hiding this comment.
You mean the QueryPlan's deterministic? #34470
There was a problem hiding this comment.
that's plan level, not column level. We need something more fine-grained
There was a problem hiding this comment.
ok, I'll first try to add a column level nondeterministic information before this pr
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
What changes were proposed in this pull request?
When we do shuffle on indeterminate expressions such as
rand, and ShuffleFetchFailed happend, we may get incorrent result since it only retries failed map tasks.To illustrate this, suppose we have a dataset with two columns
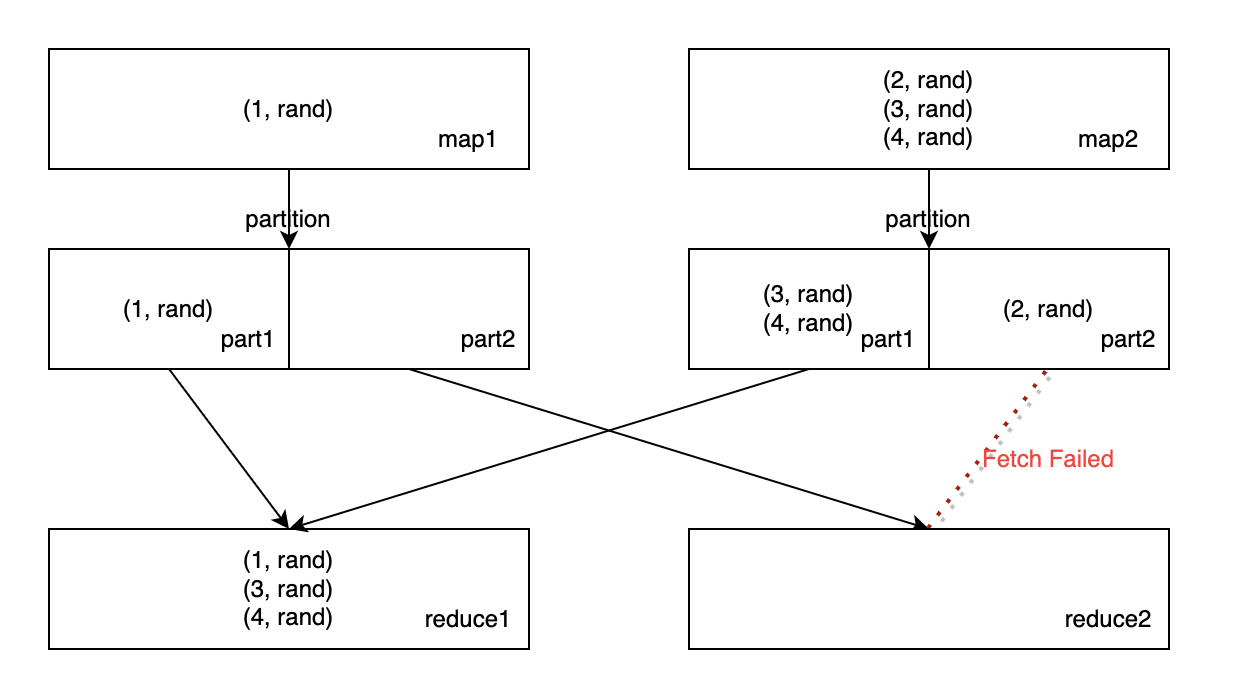
(range(1, 5) as a, rand() as b), we shuffle bybusing two map tasks and two reduce tasks.When there is a fetch failed and we need to rerun map task 2, the generated partitions maybe different compared with last attempt, and finally we get a duplicate record with a = 4
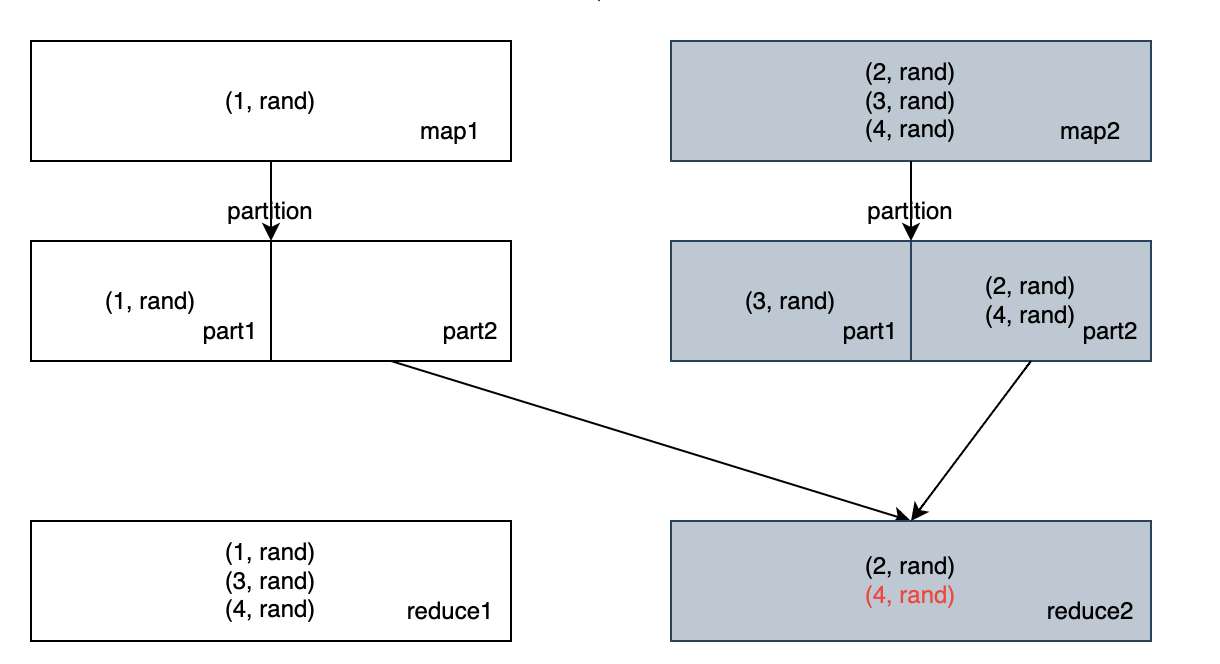
This is very similary to the bug in Repartition+Shuffle, which is fixed by #22112.
This PR try to fix this by reuse current machenism.
Why are the changes needed?
Fix data inconsistent issue.
Does this PR introduce any user-facing change?
No
How was this patch tested?
Added UT