[SPARK-36183][SQL] Push down limit 1 through Aggregate if it is group only #33397
Conversation
|
Kubernetes integration test unable to build dist. exiting with code: 1 |
|
Test build #141165 has finished for PR 33397 at commit
|
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
Outdated
Show resolved
Hide resolved
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #141258 has finished for PR 33397 at commit
|
|
Test build #141266 has finished for PR 33397 at commit
|
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
Outdated
Show resolved
Hide resolved
…mizer/Optimizer.scala Co-authored-by: Wenchen Fan <[email protected]>
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Merged to master. |
|
Test build #141311 has finished for PR 33397 at commit
|
|
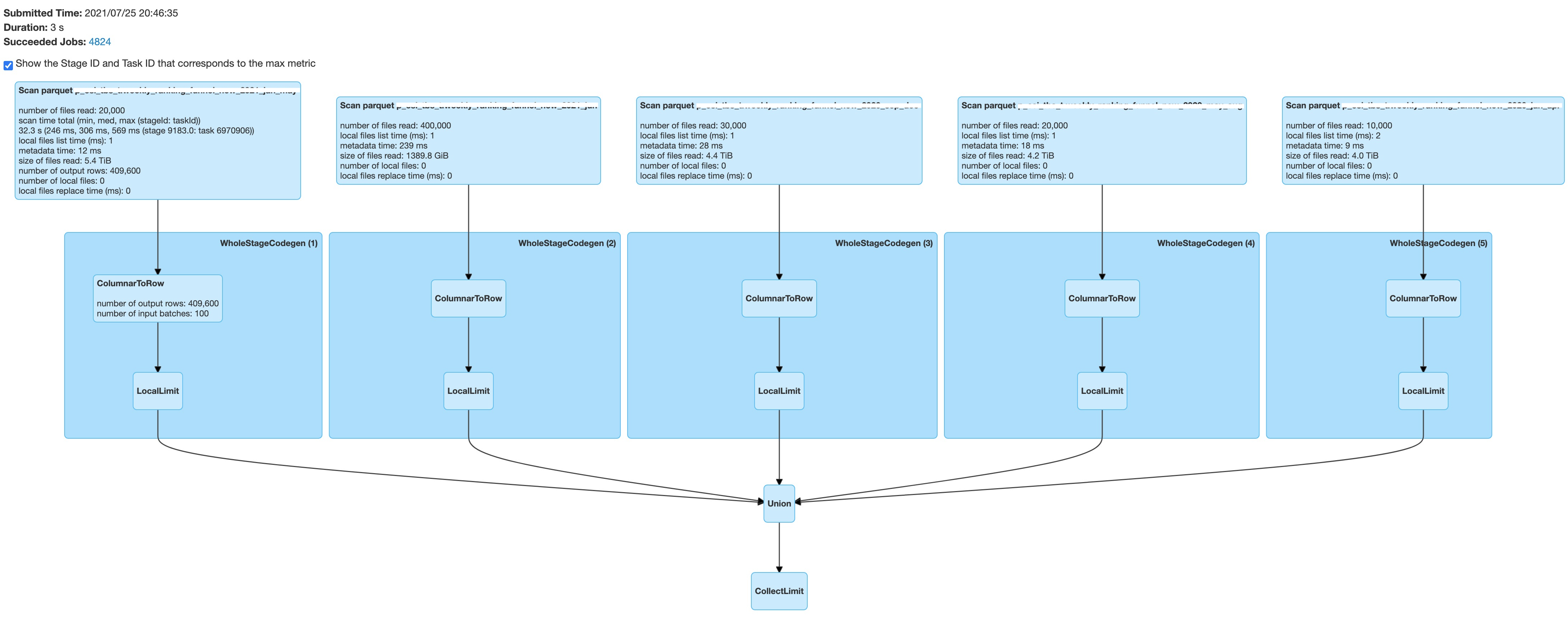
The benchmark result:
|

…oject ### What changes were proposed in this pull request? This is a follow-up of #33397 to avoid sub-optimal plans. After converting `Aggregate` to `Project`, there is information lost: `Aggregate` doesn't care about the data order of inputs, but `Project` cares. `EliminateSorts` can remove `Sort` below `Aggregate`, but it doesn't work anymore if we convert `Aggregate` to `Project`. This PR fixes this issue by tagging the `Project` to be order-irrelevant if it's converted from `Aggregate`. Then `EliminateSorts` optimizes the tagged `Project`. ### Why are the changes needed? avoid sub-optimal plans ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? new test ### Was this patch authored or co-authored using generative AI tooling? No Closes #44310 from cloud-fan/sort. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…oject ### What changes were proposed in this pull request? This is a follow-up of apache#33397 to avoid sub-optimal plans. After converting `Aggregate` to `Project`, there is information lost: `Aggregate` doesn't care about the data order of inputs, but `Project` cares. `EliminateSorts` can remove `Sort` below `Aggregate`, but it doesn't work anymore if we convert `Aggregate` to `Project`. This PR fixes this issue by tagging the `Project` to be order-irrelevant if it's converted from `Aggregate`. Then `EliminateSorts` optimizes the tagged `Project`. ### Why are the changes needed? avoid sub-optimal plans ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? new test ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#44310 from cloud-fan/sort. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
What changes were proposed in this pull request?
Push down limit 1 and turn
AggregateintoProjectthroughAggregateif it is group only. For example:Why are the changes needed?
Improve query performance. This is a real case from the cluster:

Does this PR introduce any user-facing change?
No.
How was this patch tested?
Unit test.