[SPARK-34659] Fix that Web UI always correctly get appId #31774
Conversation
|
Can one of the admins verify this patch? |
|
Thank you for making a PR, @ornew . |
|
@ornew could you show reproduce steps on Spark? It seems that the jupyterhub is using a different Spark UI URL from Spark.
|
|
Gentle ping, @ornew . |
|
@dongjoon-hyun @gengliangwang Thank you for your reply.
It's easy. Please run JupyterHub with jupyter-server-proxy, and PySpark. I build Jupyter Hub on Kubernetes and provide a sandbox for a large number of users. Accessing the Spark UI requires some kind of proxy. JupyterHub's Server Proxy allows you to access ports in your sandbox environment without user interaction. from pyspark import *
from pyspark.sql import *
spark = SparkSession.builder.getOrCreate()
When accessing the Spark UI by port, the Jupyter Server Proxy path contains
|
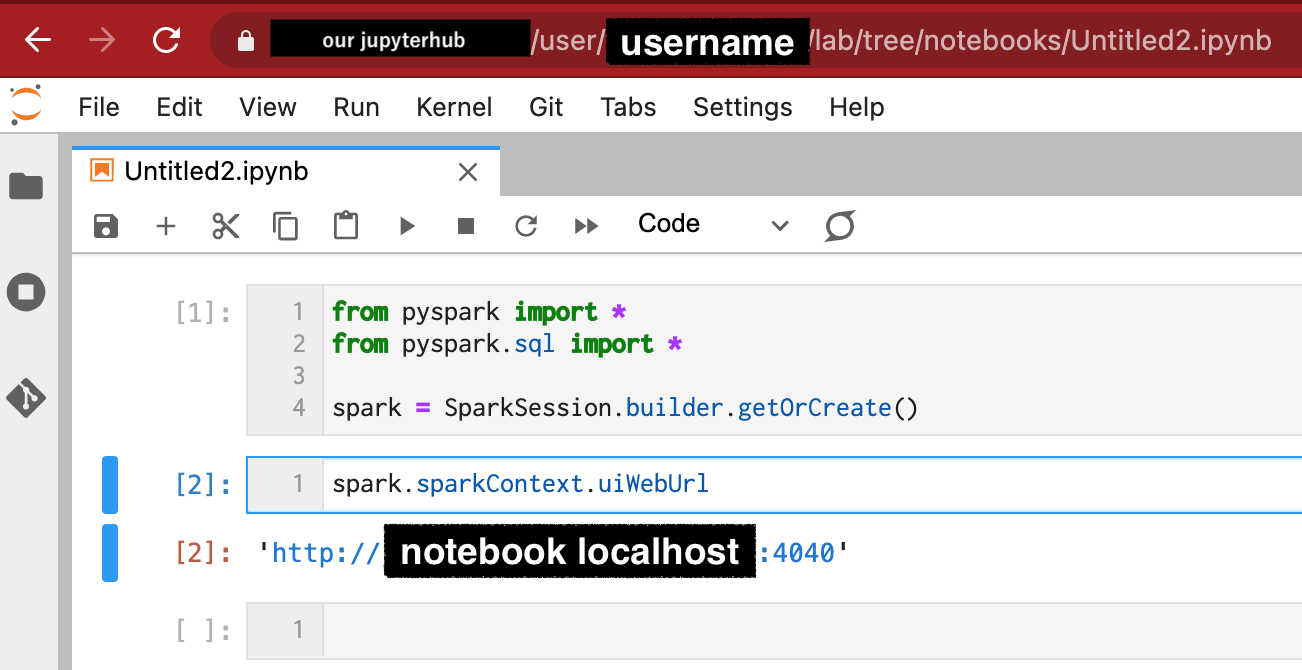
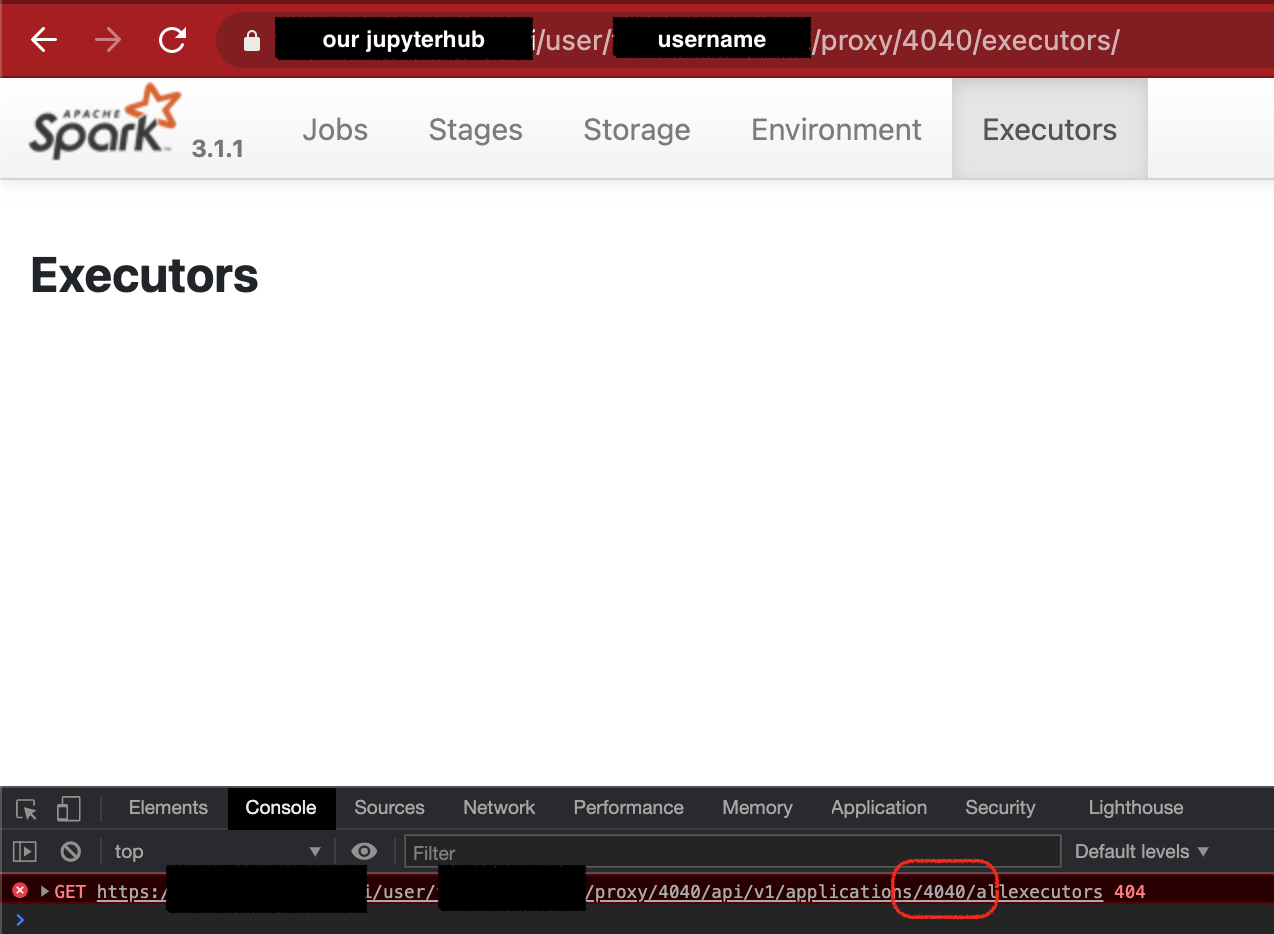
|
@ornew Is it possible to fix it in JupyterHub? The issue is not on Spark itself. |
|
@gengliangwang I think this is a Spark issue. This always happens when the path contains |
There was a problem hiding this comment.
BTW, have you tested the code changes for Spark UI behind proxy and Spark UI of History server?
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
|
@gengliangwang -- I actually have a very simple reproducer using nginx as a reverse proxy and not jupyterhub (to eliminate that failure mode). The following script will set up the proxy, note that it redirects proxy-fail.sh #!/bin/bash
cat << \EOT > nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '[$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_x_forwarded_for"';
access_log /dev/stdout main;
server {
listen 5050;
server_name localhost;
location /user/PerilousApricot/proxy/4040/ {
error_log /dev/stderr debug;
proxy_pass http://localhost:4040/;
proxy_pass_header Content-Type;
}
}
}
EOT
docker run -it --rm=true --name spark-31174-proxy --network=host -v $(pwd)/nginx.conf:/etc/nginx/nginx.conf:ro nginxRun that proxy in one terminal, then run pyspark: Open Notice, however that there is a failed request (and the reason of this PR) - If you run curl manually on both that URL, you can see that it fails both at the reverse proxy and at the actual webui itself: But if you copy-paste the appId from the spark console (in my case I have: To confirm the issue, let's restart the proxy and pyspark, but instead of proxying and then run in a different terminal Open this version requests the status of the executors from I hope this is enough to show that @ornew did the right analysis -- Th fault isn't with jupyterhub, it is simply the fact that the logic that tries to look up the appId chokes if there is a path element named "proxy" in the URL. Can you please re-examine this? EDIT: I tested with spark 3.2.0 |
|
@PerilousApricot Are you running Spark as a cluster? If yes, Spark supports reverse proxy, see the following PRs for details: |
|
Hi @gengliangwang this is running in client mode. The use-case is running spark within a jupyter notebook Thanks for the pointers, but the point of the PR is that there is a bug in how the reverse proxying is handled. If you see the reproducer, I am using the config options mentioned in #13950 and #29820. |
|
In the current master, when you reverse proxy to then Spark UI tries to do an API call to to retrieve the executor status, but this is incorrect, it should be (where local-1639523380430 is the appId of the SparkContext). The problem is that Spark itself bungles the handling of the appId. You said in #31774 (comment) that the problem was unreproducible in a Spark cluster, I hope that the reproducer I put in the comment above is enough to show the issue. Please let me know if I can help clarify it better. |
|
Hello @gengliangwang and Happy New years! I'm back from vacation and was wondering if you had further thoughts on this issue. Were you able to reproduce the bug? |
|
Hello @gengliangwang checking up on this issue. I gave a reproducer above that clearly shows the issue. Have you had a chance to take a look? |
|
@PerilousApricot I will take a close look before the 3.3 release. |
|
@gengliangwang Thank you very much! This would be a huge relief for our use-case |
|
@gengliangwang Any chance this is finished soon? |
|
This is really important for us, so I hope it doesn't slip through the
cracks. Is there anyone else available to review?--
It's dark in this basement.
|
|
According to the recent comments, I removed |
|
Hello @dongjoon-hyun I'm happy to update the PR if there is someone available to review and merge the resulting code. |
|
@gengliangwang @dongjoon-hyun Could you, please, help to review this if we plan to have it in 3.3 (just in case, it is in the allow list). |
|
@ornew Please, resolve conflicts. |
|
@ornew @PerilousApricot I think I got your point now. You would like to use the revert proxy feature on a single Spark node, instead of standalone mode with master/worker. |
@PerilousApricot should all the port be 5050? You are setting the revert proxy URL as |
|
@gengliangwang Yes, thanks for the catch. I'll update my comment (must've transposed something when copy-pasting) |
…e proxy URL ### What changes were proposed in this pull request? When the reverse proxy URL contains "proxy" or "history", the application ID in UI is wrongly parsed. For example, if we set spark.ui.reverseProxyURL as "/test/proxy/prefix" or "/test/history/prefix", the application ID is parsed as "prefix" and the related API calls will fail in stages/executors pages: ``` .../api/v1/applications/prefix/allexecutors ``` instead of ``` .../api/v1/applications/app-20220413142241-0000/allexecutors ``` There are more contexts in #31774 We can fix this entirely like #36174, but it is risky and complicated to do that. ### Why are the changes needed? Avoid users setting keywords in reverse proxy URL and getting wrong UI results. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? A new unit test. Also doc preview: <img width="1743" alt="image" src="https://user-images.githubusercontent.com/1097932/163126641-da315012-aae5-45a5-a048-340a5dd6e91e.png"> Closes #36176 from gengliangwang/forbidURLPrefix. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
{kind=link}
|
@MaxGekk there are some things @gengliangwang and @dongjoon-hyun would like fixed with this PR, but I'm hopeful that we can converge soon on a solution they'll accept. |
Web UI does not correctly get appId when it has `proxy` or `history` in URL. In my case, it's happened on `https://jupyterhub.hosted.our/my-name/proxy/4040/executors/`. There is relative issue in jupyterhub jupyterhub/jupyter-server-proxy#57 It should not get appId from document.BaseURI. A request will occur, but performance impacts will be a bit.
14bd9b2 to
9548338
Compare
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
|
@PerilousApricot use this to workaround |
Web UI does not correctly get appId when it has
proxyorhistoryin URL.In my case, it happens on
https://jupyterhub.hosted.us/my-name/proxy/4040/executors/.Web developer console says:
jquery-3.4.1.min.js:2 GET https://jupyterhub.hosted.us/user/my-name/proxy/4040/api/v1/applications/4040/allexecutors 404, and it shows blank pages to me.There is relative issue in jupyterhub jupyterhub/jupyter-server-proxy#57
spark/core/src/main/resources/org/apache/spark/ui/static/utils.js
Lines 93 to 105 in 2526fde
It should not get from document.baseURI.
A request will occur, but performance impacts will be a bit.
What changes were proposed in this pull request?
This always get an appId using the API.
Why are the changes needed?
The UI does not appear correctly in some environments. For example, there is a Jupyterhub.
Does this PR introduce any user-facing change?
No, this is bug fix.
How was this patch tested?
I see it correctly works in my browser.