[SPARK-34064][SQL] Cancel the running broadcast sub-jobs when SQL statement is cancelled #31119
Conversation
…tement is cancelled
|
Without the patch, the driver log, the Job 0 and Job 1 are still executing. With the patch, the related driver log, we can see the Job 0 and Job 1 failed due to cancelling. |
|
Test build #133907 has finished for PR 31119 at commit
|
sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala
Outdated
Show resolved
Hide resolved
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #133912 has finished for PR 31119 at commit
|
|
Test build #133916 has finished for PR 31119 at commit
|
| import BroadcastExchangeExec._ | ||
|
|
||
| override val runId: UUID = UUID.randomUUID | ||
| private val groupId = sparkContext.getLocalProperty(SparkContext.SPARK_JOB_GROUP_ID) |
There was a problem hiding this comment.
is it reliable? does the local property always contain the group id of the query that this broadcast belongs to?
There was a problem hiding this comment.
For STS, I think so. Building this physical plan preformed in a thread of HiveServer2-Background-Pool, the same thread of setting up the job group Id, parsing, analyzing, and optimizing, etc. Still keeping UUID.randomUUID is to avoid UT failures IIUC.
|
Is "canceling SQL statement" a STS specific feature? It doesn't seem to be implemented properly, as we lack the ability to track all the spark jobs submitted by one SQL statement. |
|
hmm, IIRC the SQL UI can know all the jobs of a SQL statement, how is that done? cc @gengliangwang |
Job group is not a STS specific feature. It's a API in SparkContext. But currently, only STS sets it with |
For SQL execution, the SparkListenerJobStart event contains the SQL execution ID. So that Spark can associate the jobs to SQL execution in |
|
Nice catch.
I have no idea. I guess the IDs are mainly used for the listeners (SQLAppStatusListener and HiveThriftServer2Listener) to capture and track different SQL states. For canceling related jobs, I think the IDs are both OK to use I we want them to be unified |
|
@LantaoJin can you do a bit more manual test with broadcast inside a subquery? |
Sure, let me have a try. |
A |
|
The Could we move this change to BroadcastExchangeExec.scala#L49? |
|
Another reason I think is the generation of |
Better don't. BroadcastExchangeExec.scala#L49 is a |
|
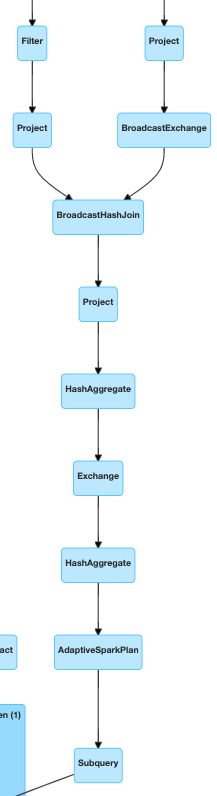
@cloud-fan I tested manually and broadcast inside a subquery could be cancelled with this patch (I also tested the same query without patch, and it cannot be cancelled). The plan was like this: |
sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala
Outdated
Show resolved
Hide resolved
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
GA passed, merging to master/3.1! (This is a bug fix of the SQL statement canceling feature in Spark thrift server) |
…tement is cancelled ### What changes were proposed in this pull request? #24595 introduced `private val runId: UUID = UUID.randomUUID` in `BroadcastExchangeExec` to cancel the broadcast execution in the Future when timeout happens. Since the runId is a random UUID instead of inheriting the job group id, when a SQL statement is cancelled, these broadcast sub-jobs are still executing. This PR uses the job group id of the outside thread as its `runId` to abort these broadcast sub-jobs when the SQL statement is cancelled. ### Why are the changes needed? When broadcasting a table takes too long and the SQL statement is cancelled. However, the background Spark job is still running and it wastes resources. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually test. Since broadcasting a table is too fast to cancel in UT, but it is very easy to verify manually: 1. Start a Spark thrift-server with less resource in YARN. 2. When the driver is running but no executors are launched, submit a SQL which will broadcast tables from beeline. 3. Cancel the SQL in beeline Without the patch, broadcast sub-jobs won't be cancelled.  With this patch, broadcast sub-jobs will be cancelled.  Closes #31119 from LantaoJin/SPARK-34064. Authored-by: LantaoJin <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit f1b21ba) Signed-off-by: Wenchen Fan <[email protected]>
{kind=link}
{kind=link}
|
Test build #134004 has finished for PR 31119 at commit
|
| override val runId: UUID = UUID.randomUUID | ||
| // Cancelling a SQL statement from Spark ThriftServer needs to cancel | ||
| // its related broadcast sub-jobs. So set the run id to job group id if exists. | ||
| override val runId: UUID = Option(sparkContext.getLocalProperty(SparkContext.SPARK_JOB_GROUP_ID)) |
There was a problem hiding this comment.
After a second thought, I think this is risky. It's possible that in a non-STS environment, users set job group id manually, and run some long-running jobs. If we capture the job group id here in broadcast exchange, when the broadcast timeout, it will cancel the whole job group which may kill the user's other long-running jobs unexpectedly.
I think we need to revisit the STS's SQL statement canceling feature. We should use SQL execution ID to find out all the jobs of a SQL query, and assign a unique job group id to them.
There was a problem hiding this comment.
@cloud-fan yes, the case you said is a problem in current implementation. I will give a new PR. Revert this first?
There was a problem hiding this comment.
Job group id is still a basic API which used to cancel the a group of jobs (depends on custom business). In a non-STS environment, users can set job group id manually, and run some long-running jobs. In some cases, such as a custom exception, user want to cancel all jobs with the same job group. And broadcast timeout shouldn't use job group Id to can broadcast job.
There was a problem hiding this comment.
Let me revert this first. Please let me know when you have a new fix, thanks!
There was a problem hiding this comment.
W/ a conf(maybe named spark.jobGroubID.inherited) to decide whether the runId is re-generated or inherited from the former specified one. Users may develop applications like ThriftServer in C/S architecture as a server-like spark program.
There was a problem hiding this comment.
Sorry, I don't get the point. If a user set spark.jobGroubID.inherited to true and set a custom jobGroupId to a UUID value, when the broadcast timeout, what's behavior?
There was a problem hiding this comment.
Do you mean this?
override val runId: UUID =
if (SQLConf.get.getConf(spark.jobGroubID.inherited)) {
UUID.randomUUID
} else {
UUID.fromString(sparkContext.getLocalProperty(SparkContext.SPARK_JOB_GROUP_ID))
}There was a problem hiding this comment.
Ok, I know. To be transparent to users, how about add a new thread local property SparkContext.SPARK_RESERVED_JOB_GROUP_ID or SPARK_THRIFTSERVER_JOB_GROUP_ID to separate it.
diff --git a/core/src/main/scala/org/apache/spark/SparkContext.scala b/core/src/main/scala/org/apache/spark/SparkContext.scala
index f6e8a5694d..cc3efed713 100644
--- a/core/src/main/scala/org/apache/spark/SparkContext.scala
+++ b/core/src/main/scala/org/apache/spark/SparkContext.scala
@@ -760,9 +760,13 @@ class SparkContext(config: SparkConf) extends Logging {
* may respond to Thread.interrupt() by marking nodes as dead.
*/
def setJobGroup(groupId: String,
- description: String, interruptOnCancel: Boolean = false): Unit = {
+ description: String, interruptOnCancel: Boolean = false, reserved: Boolean = false): Unit = {
setLocalProperty(SparkContext.SPARK_JOB_DESCRIPTION, description)
- setLocalProperty(SparkContext.SPARK_JOB_GROUP_ID, groupId)
+ if (reserved) {
+ setLocalProperty(SparkContext.SPARK_RESERVED_JOB_GROUP_ID, groupId)
+ } else {
+ setLocalProperty(SparkContext.SPARK_JOB_GROUP_ID, groupId)
+ }
// Note: Specifying interruptOnCancel in setJobGroup (rather than cancelJobGroup) avoids
// changing several public APIs and allows Spark cancellations outside of the cancelJobGroup
// APIs to also take advantage of this property (e.g., internal job failures or canceling from
@@ -2760,6 +2764,7 @@ object SparkContext extends Logging {
private[spark] val SPARK_JOB_DESCRIPTION = "spark.job.description"
private[spark] val SPARK_JOB_GROUP_ID = "spark.jobGroup.id"
+ private[spark] val SPARK_RESERVED_JOB_GROUP_ID = "spark.reservedJobGroup.id"
private[spark] val SPARK_JOB_INTERRUPT_ON_CANCEL = "spark.job.interruptOnCancel"
private[spark] val SPARK_SCHEDULER_POOL = "spark.scheduler.pool"
private[spark] val RDD_SCOPE_KEY = "spark.rdd.scope
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala b/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala
index c322d5eef5..25abb4f2d3 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/BroadcastExchangeExec.scala
@@ -76,7 +76,8 @@ case class BroadcastExchangeExec(
// Cancelling a SQL statement from Spark ThriftServer needs to cancel
// its related broadcast sub-jobs. So set the run id to job group id if exists.
- override val runId: UUID = Option(sparkContext.getLocalProperty(SparkContext.SPARK_JOB_GROUP_ID))
+ override val runId: UUID =
+ Option(sparkContext.getLocalProperty(SparkContext.SPARK_RESERVED_JOB_GROUP_ID))
.map(UUID.fromString).getOrElse(UUID.randomUUID)
override lazy val metrics = Map(
diff --git a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
index 8ca0ab91a7..4db50e8d00 100644
--- a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
+++ b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
@@ -286,7 +286,7 @@ private[hive] class SparkExecuteStatementOperation(
parentSession.getSessionState.getConf.setClassLoader(executionHiveClassLoader)
}
- sqlContext.sparkContext.setJobGroup(statementId, substitutorStatement, forceCancel)
+ sqlContext.sparkContext.setJobGroup(statementId, substitutorStatement, forceCancel, true)
result = sqlContext.sql(statement)
logDebug(result.queryExecution.toString())
HiveThriftServer2.eventManager.onStatementParsed(statementId,
|
reverted. |
|
@cloud-fan , it is a little bit hard to use execution id as group Id since |
|
|
Can we introduce a new special local property? The semantic can be: if it's set, all the jobs submitted by SQL queries should use it as job group id, regardless of what the current job group id is in the local properties. Then STS can set that special local property. |
What changes were proposed in this pull request?
#24595 introduced
private val runId: UUID = UUID.randomUUIDinBroadcastExchangeExecto cancel the broadcast execution in the Future when timeout happens. Since the runId is a random UUID instead of inheriting the job group id, when a SQL statement is cancelled, these broadcast sub-jobs are still executing. This PR uses the job group id of the outside thread as itsrunIdto abort these broadcast sub-jobs when the SQL statement is cancelled.Why are the changes needed?
When broadcasting a table takes too long and the SQL statement is cancelled. However, the background Spark job is still running and it wastes resources.
Does this PR introduce any user-facing change?
No
How was this patch tested?
Manually test.
Since broadcasting a table is too fast to cancel in UT, but it is very easy to verify manually:
Without the patch, broadcast sub-jobs won't be cancelled.

With this patch, broadcast sub-jobs will be cancelled.
