[SPARK-30659][ML][PYSPARK] LogisticRegression blockify input vectors #28458
Conversation
|
performace test on code: import org.apache.spark.ml.classification._
import org.apache.spark.storage.StorageLevel
val df = spark.read.option("numFeatures", "2000").format("libsvm").load("/data1/Datasets/epsilon/epsilon_normalized.t").withColumn("label", (col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setBlockSize(1).setMaxIter(10)
lr.fit(df)
val results = Seq(1, 4, 16, 64, 256, 1024, 4096).map { size => val start = System.currentTimeMillis; val model = lr.setBlockSize(size).fit(df); val end = System.currentTimeMillis; (size, model.coefficients, end - start) }results: blockSize==1 blockSize==256 |
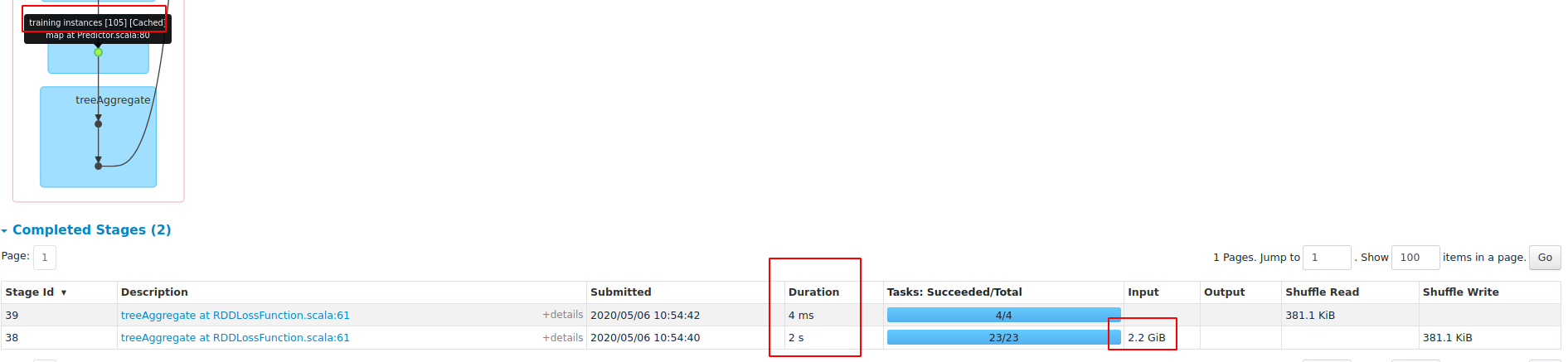

|
performace test on sparse dataset: the first 10,000 instances of code: val df = spark.read.option("numFeatures", "8289919").format("libsvm").load("/data1/Datasets/webspam/webspam_wc_normalized_trigram.svm.10k").withColumn("label", (col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setBlockSize(1).setMaxIter(10)
lr.fit(df)
val results = Seq(1, 4, 16, 64, 256, 1024, 4096).map { size => val start = System.currentTimeMillis; val model = lr.setBlockSize(size).fit(df); val end = System.currentTimeMillis; (size, model.coefficients, end - start) }results: blockSize==1 blockSize=16 test with Master: In this PR, when blockSize==1, the duration is 33948, so there will be no performance regression on sparse datasets. |
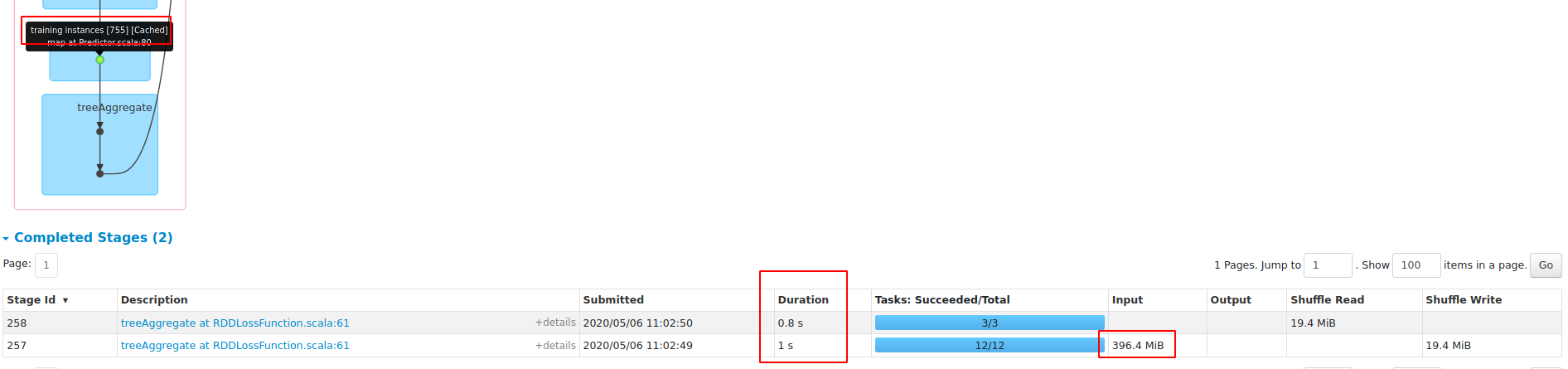
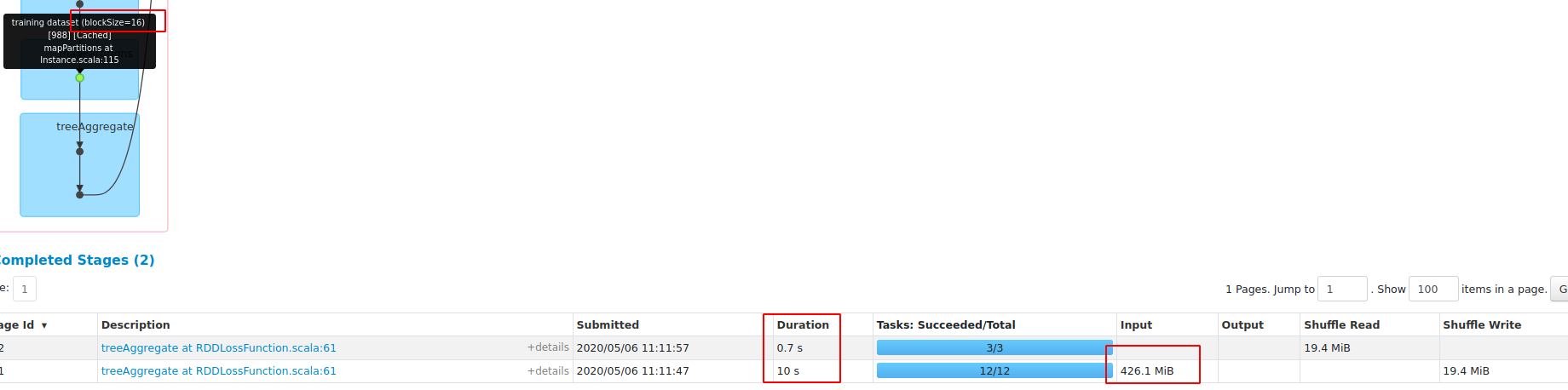
|
Test build #122334 has finished for PR 28458 at commit
|
|
Test build #122338 has finished for PR 28458 at commit
|
|
retest this please |
|
Test build #122345 has finished for PR 28458 at commit
|
|
retest this please |
|
Test build #122349 has finished for PR 28458 at commit
|
|
Test build #122356 has finished for PR 28458 at commit
|
|
Test build #122357 has finished for PR 28458 at commit
|
|
This PR is a update of #27374, it can avoid performance regression on sparse datasets by default (with blockSize=1). |
|
Merged to master |
|
@zhengruifeng, this was reviewed by nobody while the codes are near 1k lines. |
What changes were proposed in this pull request?
1, reorg the
fitmethod in LR to several blocks (createModel,createBounds,createOptimizer,createInitCoefWithInterceptMatrix);2, add new param blockSize;
3, if blockSize==1, keep original behavior, code path
trainOnRows;4, if blockSize>1, standardize and stack input vectors to blocks (like ALS/MLP), code path
trainOnBlocksWhy are the changes needed?
On dense dataset
epsilon_normalized.t:1, reduce RAM to persist traing dataset; (save about 40% RAM)
2, use Level-2 BLAS routines; (4x ~ 5x faster)
Does this PR introduce any user-facing change?
Yes, a new param is added
How was this patch tested?
existing and added testsuites