[SPARK-30642][ML][PYSPARK] LinearSVC blockify input vectors #28349
Conversation
|
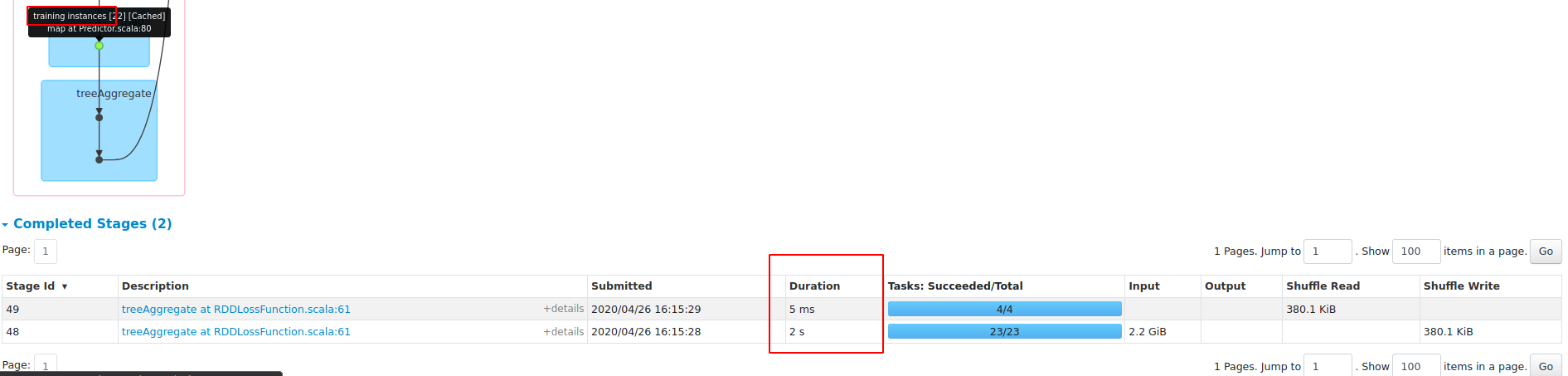
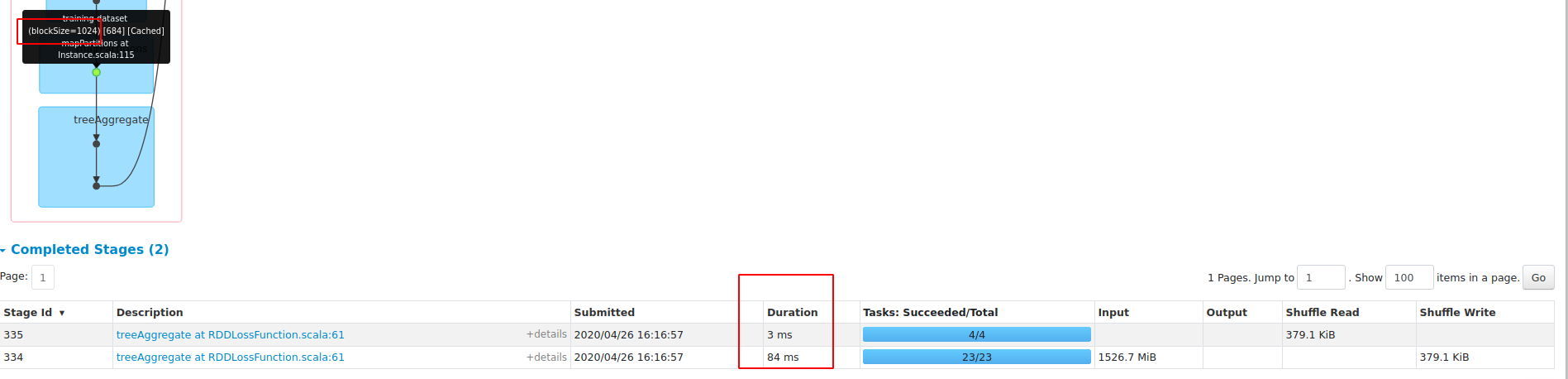
dataset: epsilon_normalized.t, numInstances=100,000, numFeatures=2,000 testCode: results ( scala> results.map(_._2).foreach{vec => println(vec.toString.take(150))}
[0.7494819225920858,-0.08640022531296566,2.3231273313690615,0.02563502913888478,0.041697717260290056,-0.008274929181709273,1.7654515767910142,0.073740
[0.7494819225920862,-0.08640022531296565,2.323127331369061,0.025635029138884782,0.041697717260290056,-0.008274929181709285,1.7654515767910144,0.073740
[0.7494819225920858,-0.08640022531296568,2.32312733136906,0.025635029138884782,0.04169771726029004,-0.008274929181709273,1.7654515767910144,0.07374022
[0.7494819225920852,-0.08640022531296565,2.3231273313690615,0.025635029138884782,0.04169771726029004,-0.00827492918170927,1.7654515767910142,0.0737402
[0.7494819225920866,-0.08640022531296565,2.3231273313690615,0.025635029138884782,0.041697717260290056,-0.008274929181709282,1.7654515767910144,0.07374
[0.7494819225920862,-0.08640022531296565,2.3231273313690615,0.025635029138884866,0.04169771726029005,-0.008274929181709245,1.7654515767910144,0.073740
[0.7494819225920862,-0.08640022531296568,2.323127331369061,0.025635029138884782,0.041697717260290056,-0.00827492918170928,1.7654515767910144,0.0737402
scala> results.map(_._3)
res13: Seq[Long] = List(43328, 8726, 8413, 9151, 9029, 8630, 9212)speed: blockSize=1024 RAM: blockSize=1024 Native BLAS is NOT used in this test |


|
friendly ping @srowen @WeichenXu123 To avoid performance regression on sparse datasets, switch to original impl by setting |
| instr.logNamedValue("lowestLabelWeight", labelSummarizer.histogram.min.toString) | ||
| instr.logNamedValue("highestLabelWeight", labelSummarizer.histogram.max.toString) | ||
| instr.logSumOfWeights(summarizer.weightSum) | ||
| if ($(blockSize) > 1) { |
There was a problem hiding this comment.
I think it is up to the end user to choose whether high-level blas is used and which BLAS lib is used.
Here computes the sparsity of dataset, if input it too sparse, log a warning.
|
The main part of this PR is similar to #27360, |
|
The speedup is more significiant than that in #27360, |
|
|
||
| block.matrix match { | ||
| case dm: DenseMatrix => | ||
| BLAS.nativeBLAS.dgemv("N", dm.numCols, dm.numRows, 1.0, dm.values, dm.numCols, |
There was a problem hiding this comment.
directly update the first numFeatures elements in localGradientSumArray, avoiding creating a temp vector and then adding it to localGradientSumArray
| if (fitIntercept) localGradientSumArray(numFeatures) += vec.values.sum | ||
|
|
||
| case sm: SparseMatrix if fitIntercept => | ||
| BLAS.gemv(1.0, sm.transpose, vec, 0.0, linearGradSumVec) |
There was a problem hiding this comment.
No avaiable method to update the first numFeatures, so need a temp output vector linearGradSumVec
|
Test build #121838 has finished for PR 28349 at commit
|
|
Test build #121841 has finished for PR 28349 at commit
|
|
Test build #121842 has finished for PR 28349 at commit
|
|
Test build #121845 has finished for PR 28349 at commit
|
|
I also test on sparse dataset: results: Master: If we keep |
|
Test build #121896 has finished for PR 28349 at commit
|
|
Test build #121950 has finished for PR 28349 at commit
|
|
Test build #121976 has finished for PR 28349 at commit
|
|
I will merge this PR this week if nobody object. |
a97a8fc to
58c0a1e
Compare
|
Test build #122058 has finished for PR 28349 at commit
|
 srowen
left a comment
srowen
left a comment
There was a problem hiding this comment.
It'd be great to have @mengxr comment here. I think the issue last time was indeed sparse performance. If the default should not produce any slowdown on sparse, I think it's reasonable, but we need to tell the user about this tradeoff in the doc above.
I'm a little concerned about the extra complexity, but the speedup is promising.
| setDefault(aggregationDepth -> 2) | ||
|
|
||
| /** | ||
| * Set block size for stacking input data in matrices. |
There was a problem hiding this comment.
We might provide a little more comment about what this does. Increasing it increases performance, but at the risk of what, slowing down on sparse input?
There was a problem hiding this comment.
The choice of size needs tuning, it depends on dataset sparsity and numFeatures, Increasing it may not always increases performance.
| if ($(standardization)) None else Some(getFeaturesStd))) | ||
| } else None | ||
|
|
||
| def regParamL1Fun = (index: Int) => 0D |
|
Test build #122101 has finished for PR 28349 at commit
|
|
Test build #122103 has finished for PR 28349 at commit
|
|
Test build #122266 has finished for PR 28349 at commit
|
@srowen I think there maybe other implementations (LoR/LiR/KMeans/GMM/...) that will support blockifying, so I perfer to add a description in the For LinearSVC, I added some doc in the setter of |
|
Merged to master |
|
@zhengruifeng, let's avoid to merge without an approval, in particular, when the changes are pretty big. From a cursory look, it's even pretty invasive. This is not a great pattern to merge PRs without approvals when we should call more reviews and approvals. |
What changes were proposed in this pull request?
1, add new param
blockSize;2, add a new class InstanceBlock;
3, if
blockSize==1, keep original behavior; ifblockSize>1, stack input vectors to blocks (like ALS/MLP);4, if
blockSize>1, standardize the input outside of optimization procedure;Why are the changes needed?
1, reduce RAM to persist traing dataset; (save about 40% RAM)
2, use Level-2 BLAS routines; (4x ~ 5x faster on dataset
epsilon)Does this PR introduce any user-facing change?
Yes, a new param is added
How was this patch tested?
existing and added testsuites