[SPARK-31331][SQL][DOCS] Document Spark integration with Hive UDFs/UDAFs/UDTFs #28104
Conversation
|
Test build #120738 has finished for PR 28104 at commit
|
docs/sql-ref-functions-udf-hive.md
Outdated
|
|
||
| <pre><code> | ||
| // Register a Hive UDF and use it in Spark SQL | ||
| // Scala |
There was a problem hiding this comment.
Probably, we need ADD JAR for the hive UDF below here.
docs/sql-ref-functions-udf-hive.md
Outdated
| // GenericUDTFCount2 outputs the number of rows seen, twice. | ||
| // The function source code can be found at: | ||
| // https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide+UDTF | ||
| sql(s"ADD JAR ${hiveContext.getHiveFile("TestUDTF.jar").getCanonicalPath}") |
There was a problem hiding this comment.
Since hiveContext.getHiveFile is a method for our test use and users easily cannot undersntad this example, I think we had not better use it for the document.
|
Test build #120753 has finished for PR 28104 at commit
|
|
Test build #120752 has finished for PR 28104 at commit
|
|
retest this please |
|
Test build #120757 has finished for PR 28104 at commit
|
|
@huaxingao It seems all the reviews have been not adressed yet, e.g., https://github.com/apache/spark/pull/28104/files#r402692479 |
|
Test build #120887 has finished for PR 28104 at commit
|
|
Test build #120886 has finished for PR 28104 at commit
|
|
@huaxingao I brushed up the doc based on your PR. Could you check this? huaxingao#2 |
|
Test build #121004 has finished for PR 28104 at commit
|
docs/sql-ref-functions-udf-hive.md
Outdated
| // e.g., `spark.sql("ADD JAR yourHiveUDF.jar")`. | ||
| spark.sql("CREATE TEMPORARY FUNCTION testUDF AS 'org.apache.hadoop.hive.ql.udf.generic.GenericUDFAbs'") | ||
|
|
||
| spark.sql("SELECT * FROM hiveUDFTestTable").show() |
There was a problem hiding this comment.
Ur, my bad. nit: hiveUDFTestTable -> t.
btw, any reason to write this doc by Scala? Could we follow the SQL format here, too?
There was a problem hiding this comment.
OK. Will convert to SQL
|
Test build #121018 has finished for PR 28104 at commit
|
 maropu
left a comment
maropu
left a comment
There was a problem hiding this comment.
LGTM. Thanks, @huajianmao ! cc: @srowen
|
Merged to master/3.0 |
…AFs/UDTFs ### What changes were proposed in this pull request? Document Spark integration with Hive UDFs/UDAFs/UDTFs ### Why are the changes needed? To make SQL Reference complete ### Does this PR introduce any user-facing change? Yes <img width="1031" alt="Screen Shot 2020-04-02 at 2 22 42 PM" src="https://user-images.githubusercontent.com/13592258/78301971-cc7cf080-74ee-11ea-93c8-7d4c75213b47.png"> ### How was this patch tested? Manually build and check Closes #28104 from huaxingao/hive-udfs. Lead-authored-by: Huaxin Gao <[email protected]> Co-authored-by: Takeshi Yamamuro <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 61f903f) Signed-off-by: Sean Owen <[email protected]>
{kind=link}
|
Thank you everyone! |
…AFs/UDTFs ### What changes were proposed in this pull request? Document Spark integration with Hive UDFs/UDAFs/UDTFs ### Why are the changes needed? To make SQL Reference complete ### Does this PR introduce any user-facing change? Yes <img width="1031" alt="Screen Shot 2020-04-02 at 2 22 42 PM" src="https://user-images.githubusercontent.com/13592258/78301971-cc7cf080-74ee-11ea-93c8-7d4c75213b47.png"> ### How was this patch tested? Manually build and check Closes apache#28104 from huaxingao/hive-udfs. Lead-authored-by: Huaxin Gao <[email protected]> Co-authored-by: Takeshi Yamamuro <[email protected]> Signed-off-by: Sean Owen <[email protected]>
| AS 'org.apache.hadoop.hive.ql.udf.generic.GenericUDTFExplode'; | ||
|
|
||
| SELECT * FROM t; | ||
| +------+ |
There was a problem hiding this comment.
quick question. Why did we use:
+---+
|col|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
format over the Hive string format (which is produced by spark-sql script)?
There was a problem hiding this comment.
Also, seems like we should comment these output out.
There was a problem hiding this comment.
There was a problem hiding this comment.
Hmm.. I see. I double checked other references such as https://docs.snowflake.com/en/sql-reference/constructs/join.html, https://docs.oracle.com/cd/B19306_01/server.102/b14200/statements_10002.htm, https://www.postgresql.org/docs/10/sql-select.html.
Looks they don't add leading two spaces at least(?). I don't have a strong opinion on this yet. Can we at least remove leading two spaces?
There was a problem hiding this comment.
Also, seems like we should comment these output out.
Not sure to comment out the output or not. In SQL syntax section, we didn't comment out any of the output. But in the UDAF SQL example, I commented out the output to be consistent with the scala and java examples.
There was a problem hiding this comment.
Yea, removing the spaces looks fine. I personally think the most important thing is just to keep the almost same format over the documents. So, I think we can update each rule in the current format if we have a better one. Anyway, thanks for the check, @HyukjinKwon
There was a problem hiding this comment.
Okay, thank you guys. It's not urgent but let's remove the two leading spaces. I think that looks more consistent with other references at least.
What changes were proposed in this pull request?
Document Spark integration with Hive UDFs/UDAFs/UDTFs
Why are the changes needed?
To make SQL Reference complete
Does this PR introduce any user-facing change?
Yes
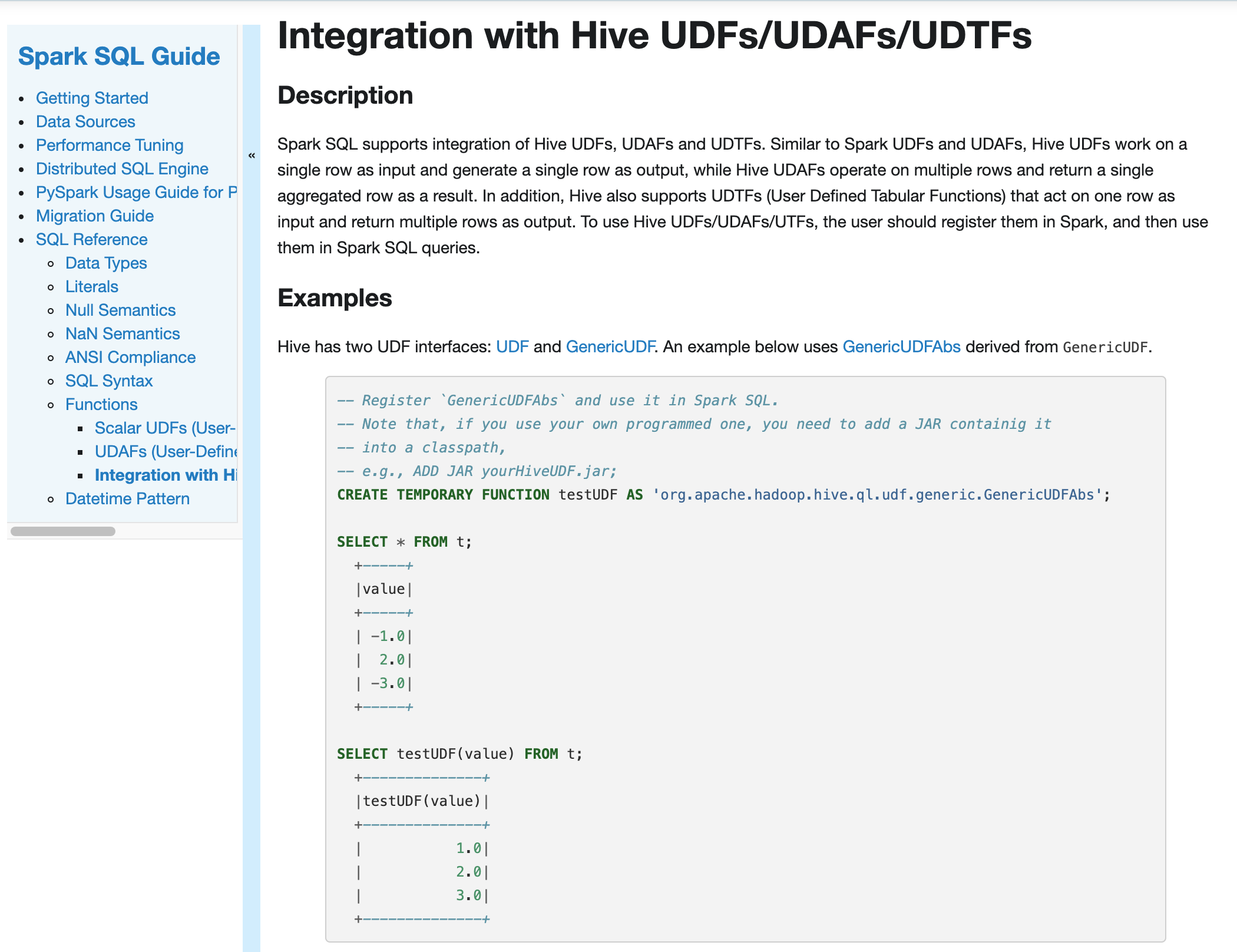
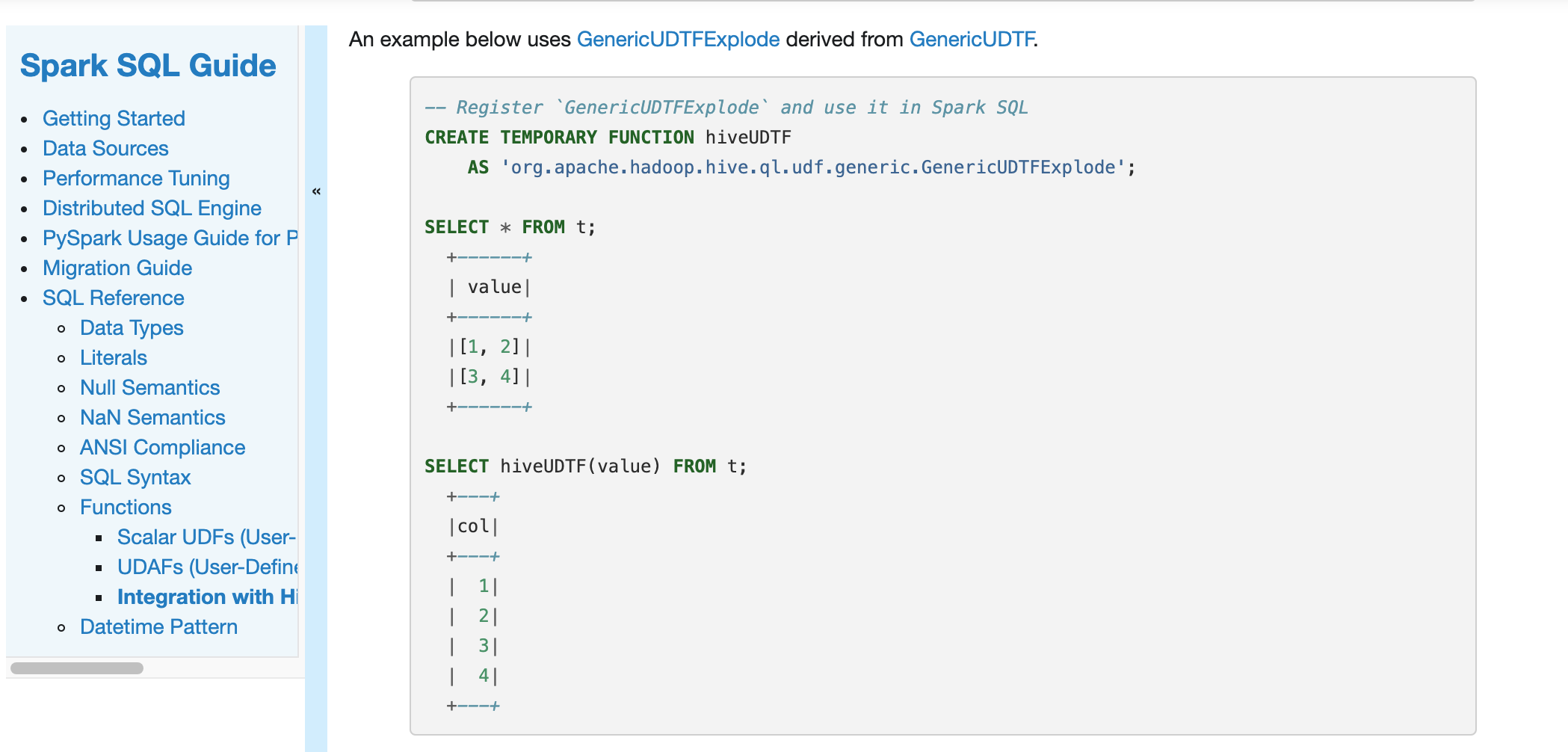

How was this patch tested?
Manually build and check