[SPARK-27931][SQL] Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. #25458
Conversation
…a boolean data type.
| Set("t", "true", "y", "yes", "1", "on").map(UTF8String.fromString) | ||
|
|
||
| private[this] val falseStrings = | ||
| Set("f", "false", "n", "no", "0", "off").map(UTF8String.fromString) |
There was a problem hiding this comment.
It seems only PostgreSQL accepts on and off?
There was a problem hiding this comment.
Yes I guess so. Do you know other common string representattion used in other databases?
There was a problem hiding this comment.
But PostgreSQL also acceptsof, tru, fals, ...:
postgres=# select cast('of' as boolean), cast('tru' as boolean), cast('fals' as boolean);
bool | bool | bool
------+------+------
f | t | f
(1 row)There was a problem hiding this comment.
Ah okay. Let me add that too. Thank you
|
Test build #109139 has finished for PR 25458 at commit
|
…he boolean data type.
|
Unique prefixes of strings, for example, "true", "tre", "tr" and "t" also accepted. |
|
@HyukjinKwon, @srowen Could you please review this PR? |
|
cc @dongjoon-hyun, @cloud-fan and @gatorsmile as well. |
|
Test build #109158 has finished for PR 25458 at commit
|
|
|
||
| -- [SPARK-27931] Trim the string when cast string type to boolean type | ||
| SELECT boolean(' f ') AS `false`; | ||
| SELECT boolean(' f ') AS `true`; |
There was a problem hiding this comment.
@wangyum I think it should be 'true'. Is it correct?
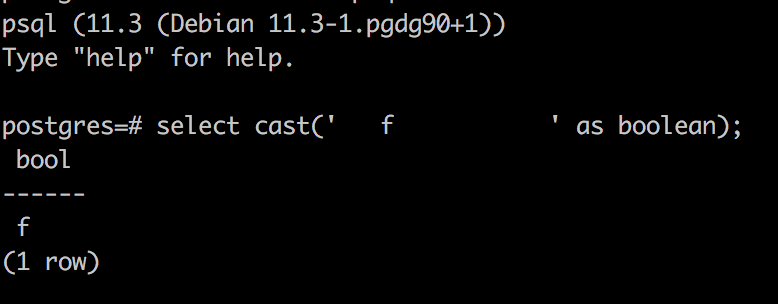
|
retest this please |
|
Test build #109222 has finished for PR 25458 at commit
|
|
Test build #109234 has finished for PR 25458 at commit
|
|
Could you please review this PR? @HyukjinKwon @dongjoon-hyun @cloud-fan and @gatorsmile |
| checkCast("n", false) | ||
| checkCast("0", false) | ||
| checkCast("off", false) | ||
| checkCast("of", false) |
There was a problem hiding this comment.
@younggyuchun, just for doubly sure, did you double check the behaviours against PostgreSQL?

There was a problem hiding this comment.
This is not documented: https://www.postgresql.org/docs/devel/datatype-boolean.html
Postgres may support of for history reasons, I don't think we have to follow it.
There was a problem hiding this comment.
@cloud-fan @dongjoon-hyun @HyukjinKwon
This build accepts several unique prefixes for the boolean data type. For example, tru, tr, ye, fals, fal, fa and of, which are not documented. Do we want to not to accept these prefixes?
There was a problem hiding this comment.
@cloud-fan . It's a documented feature in that document. We had better support it.
Unique prefixes of these strings are also accepted, for example t or n. Leading or trailing whitespace is ignored, and case does not matter.
cc @gatorsmile
There was a problem hiding this comment.
BTW, @younggyuchun . Please add a negative test case.
o is not supported because it's not unique. It's a common prefix for on and off.
It should be null.
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/StringUtils.scala
Show resolved
Hide resolved
There was a problem hiding this comment.
Hi, @younggyuchun . Thank you for this contribution. Could you add a comment to the non-trivial code part? Also, please update the PR title and description accordingly since this PR seems to be almost ready for merge. I'll review this PR again after updating.
…fixes of these strings are accepted.
|
Hi @dongjoon-hyun, |
|
Test build #109830 has finished for PR 25458 at commit
|
|
Retest this please |
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastSuite.scala
Show resolved
Hide resolved
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CastSuite.scala
Outdated
Show resolved
Hide resolved
| checkCast("off", false) | ||
| checkCast("of", false) | ||
|
|
||
| checkEvaluation(cast("o", BooleanType), null) |
There was a problem hiding this comment.
@dongjoon-hyun
Add a negative test for "o"
|
Test build #109927 has finished for PR 25458 at commit
|
|
Test build #109931 has finished for PR 25458 at commit
|
|
Test build #109933 has finished for PR 25458 at commit
|
…an type" comment.
|
The last commit removes 4 comments from Merged to master. Thank you all! |
|
Thank you all. |
|
Test build #109957 has finished for PR 25458 at commit
|
|
@dongjoon-hyun @maropu @cloud-fan @HyukjinKwon This is a behavior change. We need to document it if it is on by default. I think it should be guarded by a global dialect flag, for postgreSQL compatibility instead of doing it for all the cases. WDYT? |
|
I believe postgreSQL compatibility is a very important feature. We will add more and more such behavior changes in the near future. Let us move these changes behind a conf like |
|
Yep. I agree. Sounds good to me. And, what is the default value of the conf? |
|
I think |
|
Got it. So, Apache Spark 3.0.0 starts with |
|
Yes. I think that might be a good choice. |
|
https://issues.apache.org/jira/browse/SPARK-28934 is filed. After we create the configuration, we can wrap the existing work one-by-one safely. |
|
Sounds good to me, too. |
### What changes were proposed in this pull request? After #25158 and #25458, SQL features of PostgreSQL are introduced into Spark. AFAIK, both features are implementation-defined behaviors, which are not specified in ANSI SQL. In such a case, this proposal is to add a configuration `spark.sql.dialect` for choosing a database dialect. After this PR, Spark supports two database dialects, `Spark` and `PostgreSQL`. With `PostgreSQL` dialect, Spark will: 1. perform integral division with the / operator if both sides are integral types; 2. accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. ### Why are the changes needed? Unify the external database dialect with one configuration, instead of small flags. ### Does this PR introduce any user-facing change? A new configuration `spark.sql.dialect` for choosing a database dialect. ### How was this patch tested? Existing tests. Closes #25697 from gengliangwang/dialect. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? Reprocess all PostgreSQL dialect related PRs, listing in order: - #25158: PostgreSQL integral division support [revert] - #25170: UT changes for the integral division support [revert] - #25458: Accept "true", "yes", "1", "false", "no", "0", and unique prefixes as input and trim input for the boolean data type. [revert] - #25697: Combine below 2 feature tags into "spark.sql.dialect" [revert] - #26112: Date substraction support [keep the ANSI-compliant part] - #26444: Rename config "spark.sql.ansi.enabled" to "spark.sql.dialect.spark.ansi.enabled" [revert] - #26463: Cast to boolean support for PostgreSQL dialect [revert] - #26584: Make the behavior of Postgre dialect independent of ansi mode config [keep the ANSI-compliant part] ### Why are the changes needed? As the discussion in http://apache-spark-developers-list.1001551.n3.nabble.com/DISCUSS-PostgreSQL-dialect-td28417.html, we need to remove PostgreSQL dialect form code base for several reasons: 1. The current approach makes the codebase complicated and hard to maintain. 2. Fully migrating PostgreSQL workloads to Spark SQL is not our focus for now. ### Does this PR introduce any user-facing change? Yes, the config `spark.sql.dialect` will be removed. ### How was this patch tested? Existing UT. Closes #26763 from xuanyuanking/SPARK-30125. Lead-authored-by: Yuanjian Li <[email protected]> Co-authored-by: Maxim Gekk <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
What changes were proposed in this pull request?
This PR aims to add "true", "yes", "1", "false", "no", "0", and unique prefixes as input for the boolean data type and ignore input whitespace. Please see the following what string representations are using for the boolean type in other databases.
https://www.postgresql.org/docs/devel/datatype-boolean.html
https://docs.aws.amazon.com/redshift/latest/dg/r_Boolean_type.html
How was this patch tested?
Added new tests to CastSuite.