[SPARK-28577][YARN]Resource capability requested for each executor add offHeapMemorySize #25309
Conversation
…offHeapSize when offHeap is enable
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
Outdated
Show resolved
Hide resolved
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
Outdated
Show resolved
Hide resolved
 xuanyuanking
left a comment
xuanyuanking
left a comment
There was a problem hiding this comment.
+1 for choosing a safer config, just one nit for the log. cc @jerryshao.
| sparkConf.getSizeAsMb(MEMORY_OFFHEAP_SIZE.key, MEMORY_OFFHEAP_SIZE.defaultValueString) | ||
| require(size > 0, | ||
| s"${MEMORY_OFFHEAP_SIZE.key} must be > 0 when ${MEMORY_OFFHEAP_ENABLED.key} == true") | ||
| logInfo(s"${MEMORY_OFFHEAP_ENABLED.key} is true, ${MEMORY_OFFHEAP_SIZE.key} is $size, " + |
There was a problem hiding this comment.
How about only gives a warning log when we find the overhead is less than offHeap? We use the warning to notice user the changes of the config and explain why we change it, so there's no extra log for the same behavior as before.
There was a problem hiding this comment.
@xuanyuanking Thx for ur review , in 9421fbe change to print a warn log when offHeapSize more than overhead
| } | ||
| size | ||
| } else 0 | ||
| math.max(overhead, offHeap).toInt |
There was a problem hiding this comment.
I was wondering if it is better to change to overhead = overhead + offHeap if off-heap is enabled. Mainly because off heap memory is not only used for Spark itself related, but also for Netty and other native libraries. If we only guarantee overhead > offHeap, then it would somehow occupy the usage of Netty and others. Just my two cents :).
There was a problem hiding this comment.
Got it ~, So should we add 2 field like isOffHeapEnabled and executorOffHeapMemory to YarnAllocator then use executorMemory + memoryOverhead + pysparkWorkerMemory + executorOffHeapMemory to request resource and no longer modify memoryOverhead?
There was a problem hiding this comment.
Hmm, that's a bit complex as for now:
- If we assume overhead memory includes all the off-heap memory Spark used (include everything). Then user should be aware of the different off-heap memory settings, and carefully set the overhead number to cover all the usages.
- If we assume that overhead memory only related to some additional memory usage (not explicitly set by Spark, like off-heap memory). Then the overall executor memory should add all as mentioned above.
I think it would be better to involve other's opinion. CC @vanzin @tgravescs .
There was a problem hiding this comment.
yeah I always thought this was a bit weird off heap was just included in the overhead, but never took the time to go back to see if it was discussed.
I think it's better to specifically add the off heap instead of include in the overhead. Just like we did for the pyspark memory. executorMemory + memoryOverhead + pysparkWorkerMemory + executorOffHeapMemory. I think that keeps things more consistent and obvious to the user.
There was a problem hiding this comment.
@tgravescs Agree with you, overhead should be used to describe memory not use by Spark, like Netty used or JVM used as @jerryshao said, and we should clearly describe it in the configuration document.
So change to use executorMemory + memoryOverhead + pysparkWorkerMemory + executorOffHeapMemory to request resource?
There was a problem hiding this comment.

@beliefer Now YarnAllocator line 150 use executorMemory + memoryOverhead + pysparkWorkerMemory to new Resource Instance, Is this wrong?
There was a problem hiding this comment.
On the other hand, if the user configures offheapMemory and pysparkWorkerMemory,
He still needs to configure overhead Memroy and ensure that the configuration is reasonable(memoryOverhead > offheapMemory + pysparkWorkerMemory) in Yarn mode, so that users may need to care about more details.
There was a problem hiding this comment.
@jerryshao Is the current approach feasible?
There was a problem hiding this comment.
I have check the code and doc, there exists some inconsistent. According to the docs, memoryOverhead should comprise pysparkWorkerMemory. But the code have different behavior.
We need to fix the inconsistent. I think should reduce parameter to control memory, because more simple. @JoshRosen Could you take a look at this PR?
There was a problem hiding this comment.
I agree with @tgravescs 's opinion.
yeah, I understand that, if we are going to change it, 3.0 is a good time to change that behavior. Like I said, I had found the off heap included in the overhead as confusing because you already had another separate config, why do I as a user have to add it into another config.
If overhead memory includes off-heap memory, pysparkWorkMemory and others, it makes user hard to set a proper overhead memory, users should know every other settings and figure out a proper number. As of time 3.0, I think we should give a good definition of overhead memory, it can be inconsistent with old version.
|
ok to test. |
|
Test build #108704 has finished for PR 25309 at commit
|
|
@jerryshao IMHO, Spark should reduce configuration parameters first. And then I think no matter what memory is, we use the unified parameter to control is better. Maybe separate parameter looks easy to understand. |
|
@beliefer I'm a little confused, do you want a unified parameter, or separated parameters, could you explain more?
|
| val sizeInMB = | ||
| sparkConf.getSizeAsMb(MEMORY_OFFHEAP_SIZE.key, MEMORY_OFFHEAP_SIZE.defaultValueString).toInt | ||
| require(sizeInMB > 0, | ||
| s"${MEMORY_OFFHEAP_SIZE.key} must be > 0 when ${MEMORY_OFFHEAP_ENABLED.key} == true") |
There was a problem hiding this comment.
Please check if MEMORY_OFFHEAP_SIZE could equal to 0. The definition of MEMORY_OFFHEAP_SIZE checks that it could be >= 0.
There was a problem hiding this comment.
A little conflict with the MemoryManager as following:
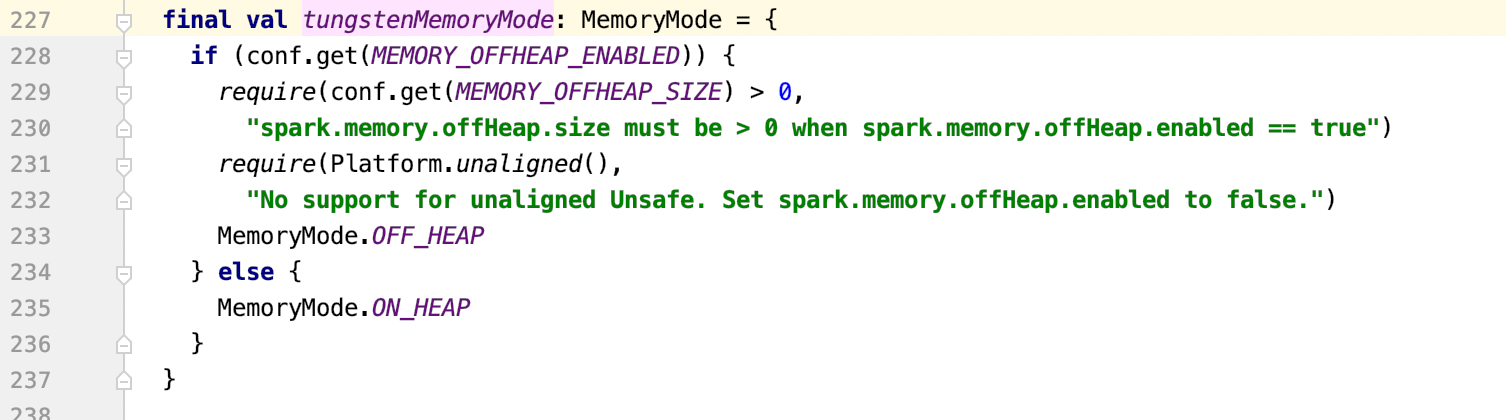
if MEMORY_OFFHEAP_ENABLED is enable, MemoryManager.tungstenMemoryMode will enter OFF_HEAP branch and need MEMORY_OFFHEAP_SIZE > 0 and I think we should be consistent.
There was a problem hiding this comment.
Then I think we should change the code here.
There was a problem hiding this comment.
0 is defaultValue, change to
.checkValue(_ > 0, "The off-heap memory size must be positive")
.createWithDefault(1)
?
otherwise will throw IllegalArgumentException when offHeapEnabled is false and defaultValue is 0.
There was a problem hiding this comment.
Maybe we should give a suitable defaultValue ,like 1073741824(1g)?
There was a problem hiding this comment.
@jerryshao Do we need to change 0 to a suitable defaultValue?
There was a problem hiding this comment.
I see, then I would suggest not to change it. Seems there's no good value which could cover most of the scenarios, so good to leave as it is.
There was a problem hiding this comment.
its odd that check is >= 0 in the config, seems like we should change but can you file a separate jira for that?
There was a problem hiding this comment.
OK~ I will add a new jira to discuss this issue.
| s"memory capability of the cluster ($maxMem MB per container)") | ||
| val executorMem = executorMemory + executorMemoryOverhead + pysparkWorkerMemory | ||
| val executorMem = | ||
| executorMemory + executorOffHeapMemory +executorMemoryOverhead + pysparkWorkerMemory |
| assert(executorOffHeapMemory == offHeapMemoryInMB) | ||
| } | ||
|
|
||
| test("executorMemoryOverhead when MEMORY_OFFHEAP_ENABLED is true, " + |
There was a problem hiding this comment.
Just wondering if we could add some yarn side UT to verify the container memory size, rather than verifying the correctness of off-heap configuration.
There was a problem hiding this comment.
ok ~ I'll try to add it.
There was a problem hiding this comment.
Add a new test suite SPARK-28577#YarnAllocator.resource.memory should include offHeapSize when offHeapEnabled is true. in YarnAllocatorSuite
|
Test build #108823 has finished for PR 25309 at commit
|
|
@jerryshao Should we continue to complete this patch? |
|
Test build #109620 has finished for PR 25309 at commit
|
|
test this please |
|
Test build #109642 has finished for PR 25309 at commit
|
| def executorOffHeapMemorySizeAsMb(sparkConf: SparkConf): Int = { | ||
| if (sparkConf.get(MEMORY_OFFHEAP_ENABLED)) { | ||
| val sizeInMB = | ||
| Utils.byteStringAsMb(s"${sparkConf.get(MEMORY_OFFHEAP_SIZE)}B").toInt |
There was a problem hiding this comment.
you should be able to use memoryStringToMb instead.
// Convert to bytes, rather than directly to MiB, because when no units are specified the unit
// is assumed to be bytes
|
Test build #109713 has finished for PR 25309 at commit
|
| s"memory capability of the cluster ($maxMem MB per container)") | ||
| val executorMem = executorMemory + executorMemoryOverhead + pysparkWorkerMemory | ||
| val executorMem = | ||
| executorMemory + executorOffHeapMemory + executorMemoryOverhead + pysparkWorkerMemory |
There was a problem hiding this comment.
I think we should also update the doc to reflect the changes here.
There was a problem hiding this comment.
ok, I'll try to update description about MemoryOverhead & OffHeapMemory in configuration.md, in this pr or new one ?
There was a problem hiding this comment.
It would be better to change the doc in this PR.
There was a problem hiding this comment.
There's some strange behavior about spark.executor.pyspark.memory:
if we config spark.executor.pyspark.memory , the pyspark executor memory is Independent , but if we not config spark.executor.pyspark.memory , the memoryOverhead include it.
| s"offHeap memory ($executorOffHeapMemory) MB, overhead ($executorMemoryOverhead MB), " + | ||
| s"and PySpark memory ($pysparkWorkerMemory MB) is above the max threshold ($maxMem MB) " + | ||
| s"of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' " + | ||
| s"and/or 'yarn.nodemanager.resource.memory-mb'.") |
There was a problem hiding this comment.
No need to add string interpolation for this line and above.
|
Test build #109729 has finished for PR 25309 at commit
|
|
Test build #109788 has finished for PR 25309 at commit
|
|
retest this please |
|
Test build #109811 has finished for PR 25309 at commit
|
docs/configuration.md
Outdated
| (e.g. increase <code>spark.driver.memoryOverhead</code> or | ||
| <code>spark.executor.memoryOverhead</code>). | ||
| <em>Note:</em> If off-heap memory is enabled, may need to raise | ||
| <code>spark.driver.memoryOverhead</code> size. |
There was a problem hiding this comment.
actually this brings up a good question, the size configs say they work for off heap size for executors, so what cases does this need to apply to the driver. Is this config really applying to both driver and executors for things like broadcast blocks, etc.
There was a problem hiding this comment.
I have the same question :),broadcast in driver side may not use offheap, TorrentBroadcast.writeBlocks method call blockManager.putSingle method use StorageLevel.MEMORY_AND_DISK and call blockManager.putBytes method use StorageLevel.MEMORY_AND_DISK_SER, both these 2 StorageLevel not use offheap memory, maybe we should remove these 2 line.
There was a problem hiding this comment.
Originally, off-heap memory will not affect the container memory, so we must consider it and config spark.driver.memoryOverhead bigger.
There was a problem hiding this comment.
But which component uses offheap in driver side?
| private[yarn] val resource: Resource = { | ||
| val resource = Resource.newInstance( | ||
| executorMemory + memoryOverhead + pysparkWorkerMemory, executorCores) | ||
| executorMemory + executorOffHeapMemory + memoryOverhead + pysparkWorkerMemory, executorCores) |
There was a problem hiding this comment.
According line 258 to 260 in docs/configuration.md, memoryOverhead includes pysparkWorkerMemory, but looks difference here.
There was a problem hiding this comment.
Described in the document is Additional memory includes PySpark executor memory (when <code>spark.executor.pyspark.memory</code> is not configured), I think we need a new jira to discuss how to solve this problem.
There was a problem hiding this comment.
Yes, this makes me confused.
There was a problem hiding this comment.
Isn't this what spark.executor.memoryOverhead already adds via memoryOverhead?
I guess I'm wondering what MEMORY_OFFHEAP_SIZE does that's supposed to be different.
There was a problem hiding this comment.
@srowen memoryOverhead include MEMORY_OFFHEAP_SIZE before this pr, and memoryOverhead and MEMORY_OFFHEAP_SIZE had to be modified at the same time to ensure request enough resources from yarn if I want to increase MEMORY_OFFHEAP_SIZE , this is not user friendly, and this has always been confusing, why we need to modify two memory-related parameters simultaneously for one purpose? This pr let them be independent.
| processes running in the same container. The maximum memory size of container to running executor | ||
| is determined by the sum of <code>spark.executor.memoryOverhead</code> and | ||
| <code>spark.executor.memory</code>. | ||
| <em>Note:</em> Additional memory includes PySpark executor memory |
There was a problem hiding this comment.
another problem is Additional better than Non-heap?
There was a problem hiding this comment.
How to explain Non-heap? Now MemoryOverHead not includes offheap, and maybe PySpark executor memory should add a default value and separate from MemoryOverHead, should we redefinition this concept.
Any other suggested names?
There was a problem hiding this comment.
So this PR looks a little conflict with origin definition.
Non-heap includes all the memory but java heap.
There was a problem hiding this comment.
that is the point, we are changing it so that you don't have to include off heap inside of overhead memory. User is already specifying off heap size so why should they have to add it to overhead memory? it works just the other configs - pyspark memory, heap memory,
There was a problem hiding this comment.
I know the meaning of this PR. Maybe the new idea is a way. As I know, the origin decision is to unify all the different part.
| <td>executorMemory * 0.10, with minimum of 384 </td> | ||
| <td> | ||
| Amount of non-heap memory to be allocated per executor process in cluster mode, in MiB unless | ||
| Amount of additional memory to be allocated per executor process in cluster mode, in MiB unless |
There was a problem hiding this comment.
maybe we should remove interned strings, it use heap space after Java8
|
Test build #110085 has finished for PR 25309 at commit
|
|
@LuciferYang Because it has been merged to master by Thomas. :) |
|
Thanks to all reviewers ~ @jerryshao @tgravescs @xuanyuanking @kiszk @beliefer @srowen |
What changes were proposed in this pull request?
If MEMORY_OFFHEAP_ENABLED is true, add MEMORY_OFFHEAP_SIZE to resource requested for executor to ensure instance has enough memory to use.
In this pr add a helper method
executorOffHeapMemorySizeAsMbinYarnSparkHadoopUtil.How was this patch tested?
Add 3 new test suite to test
YarnSparkHadoopUtil#executorOffHeapMemorySizeAsMb