[SPARK-27402][SQL][test-hadoop3.2][test-maven] Fix hadoop-3.2 test issue(except the hive-thriftserver module) #24391
Conversation
| for dep in dependencies: | ||
| dep.dependent_modules.add(self) | ||
| all_modules.append(self) | ||
| if name == "hive-thriftserver" and hadoop_version == "hadoop3.2": |
There was a problem hiding this comment.
Used to skip hive-thriftserver module for hadoop-3.2. Will revert this change once we can merge.
There was a problem hiding this comment.
Maybe leave a TODO here just to try to make sure that doesn't get lost
|
Test build #104646 has finished for PR 24391 at commit
|
|
retest this please |
| protected def isBarrierClass(name: String): Boolean = | ||
| name.startsWith(classOf[HiveClientImpl].getName) || | ||
| name.startsWith(classOf[Shim].getName) || | ||
| name.startsWith(classOf[ShimLoader].getName) || |
There was a problem hiding this comment.
Add org.apache.hadoop.hive.shims.ShimLoader to BarrierClass, otherwise hadoop-3.2 can't access the Hive metastore from 0.12 to 2.2:
build/sbt "hive/testOnly *.VersionsSuite" -Phadoop-3.2 -Phive
...
[info] - 0.12: create client *** FAILED *** (36 seconds, 207 milliseconds)
[info] java.lang.reflect.InvocationTargetException:
[info] at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
[info] at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
[info] at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
[info] at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
[info] at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:295)
[info] at org.apache.spark.sql.hive.client.HiveClientBuilder$.buildClient(HiveClientBuilder.scala:58)
[info] at org.apache.spark.sql.hive.client.VersionsSuite.$anonfun$new$7(VersionsSuite.scala:130)
[info] at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
[info] at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
[info] at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104)
[info] at org.scalatest.Transformer.apply(Transformer.scala:22)
[info] at org.scalatest.Transformer.apply(Transformer.scala:20)
[info] at org.scalatest.FunSuiteLike$$anon$1.apply(FunSuiteLike.scala:186)
[info] at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:105)
[info] at org.scalatest.FunSuiteLike.invokeWithFixture$1(FunSuiteLike.scala:184)
[info] at org.scalatest.FunSuiteLike.$anonfun$runTest$1(FunSuiteLike.scala:196)
[info] at org.scalatest.SuperEngine.runTestImpl(Engine.scala:289)
[info] at org.scalatest.FunSuiteLike.runTest(FunSuiteLike.scala:196)
[info] at org.scalatest.FunSuiteLike.runTest$(FunSuiteLike.scala:178)
[info] at org.scalatest.FunSuite.runTest(FunSuite.scala:1560)
[info] at org.scalatest.FunSuiteLike.$anonfun$runTests$1(FunSuiteLike.scala:229)
[info] at org.scalatest.SuperEngine.$anonfun$runTestsInBranch$1(Engine.scala:396)
[info] at scala.collection.immutable.List.foreach(List.scala:392)
[info] at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:384)
[info] at org.scalatest.SuperEngine.runTestsInBranch(Engine.scala:379)
[info] at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:461)
[info] at org.scalatest.FunSuiteLike.runTests(FunSuiteLike.scala:229)
[info] at org.scalatest.FunSuiteLike.runTests$(FunSuiteLike.scala:228)
[info] at org.scalatest.FunSuite.runTests(FunSuite.scala:1560)
[info] at org.scalatest.Suite.run(Suite.scala:1147)
[info] at org.scalatest.Suite.run$(Suite.scala:1129)
[info] at org.scalatest.FunSuite.org$scalatest$FunSuiteLike$$super$run(FunSuite.scala:1560)
[info] at org.scalatest.FunSuiteLike.$anonfun$run$1(FunSuiteLike.scala:233)
[info] at org.scalatest.SuperEngine.runImpl(Engine.scala:521)
[info] at org.scalatest.FunSuiteLike.run(FunSuiteLike.scala:233)
[info] at org.scalatest.FunSuiteLike.run$(FunSuiteLike.scala:232)
[info] at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:54)
[info] at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:213)
[info] at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210)
[info] at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208)
[info] at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:54)
[info] at org.scalatest.tools.Framework.org$scalatest$tools$Framework$$runSuite(Framework.scala:314)
[info] at org.scalatest.tools.Framework$ScalaTestTask.execute(Framework.scala:507)
[info] at sbt.ForkMain$Run$2.call(ForkMain.java:296)
[info] at sbt.ForkMain$Run$2.call(ForkMain.java:286)
[info] at java.util.concurrent.FutureTask.run(FutureTask.java:266)
[info] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
[info] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
[info] at java.lang.Thread.run(Thread.java:748)
[info] Cause: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.2.0
[info] at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:286)
[info] at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:187)
[info] at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:119)|
Test build #104649 has finished for PR 24391 at commit
|
…commons-httpclient.jar (1ms)
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/package.scala
Outdated
Show resolved
Hide resolved
|
Test build #104647 has finished for PR 24391 at commit
|
|
Test build #104657 has finished for PR 24391 at commit
|
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/IsolatedClientLoader.scala
Outdated
Show resolved
Hide resolved
# Conflicts: # pom.xml
|
Test build #104750 has finished for PR 24391 at commit
|
|
retest this please |
|
Test build #104768 has finished for PR 24391 at commit
|
|
retest this please |
|
Test build #104805 has finished for PR 24391 at commit
|
|
Test build #104809 has finished for PR 24391 at commit
|
|
retest this please |
|
Test build #104838 has finished for PR 24391 at commit
|
|
Test build #104963 has finished for PR 24391 at commit
|
|
retest this please |
|
Test build #104964 has finished for PR 24391 at commit
|
|
retest this please |
|
|
||
| if (analyzedBySpark) { | ||
| if (HiveUtils.isHive23) { | ||
| assert(numRows.isDefined && numRows.get == 500) |
There was a problem hiding this comment.
Finally, Hive fixed this annoying bug. The statistics are very important for us too. Please add this in the migration guide and document the behavior difference when they used different Hadoop profile.
| assert(properties("totalSize").toLong <= 0, "external table totalSize must be <= 0") | ||
| assert(properties("rawDataSize").toLong <= 0, "external table rawDataSize must be <= 0") | ||
| if (HiveUtils.isHive23) { | ||
| assert(properties("totalSize").toLong > 0, "external table totalSize must be > 0") |
There was a problem hiding this comment.
what is the number? How does Hive collect this info?
|
My review is not finished. I will review it this weekend. If I do not leave the comments, please ping me using IMs |
|
Test build #105106 has finished for PR 24391 at commit
|
| hadoop_version = os.environ.get("AMPLAB_JENKINS_BUILD_PROFILE", "hadoop2.7") | ||
| else: | ||
| hadoop_version = os.environ.get("HADOOP_PROFILE", "hadoop2.7") | ||
|
|
There was a problem hiding this comment.
We should have a log message to show which profile we are using; otherwise, it is hard for us to know which profile is activated.
There was a problem hiding this comment.
Yes. we already have these log message:
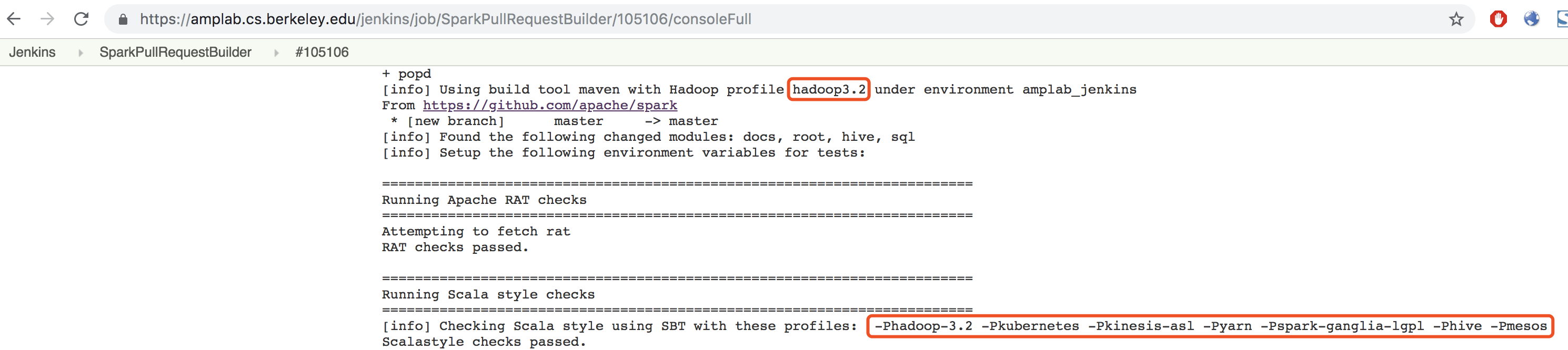
https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105106/consoleFull
There was a problem hiding this comment.
What I mean, we should have a log message to show which profile is being actually used.
Just relying on the command parameter lists does not sound very reliable

docs/sql-migration-guide-upgrade.md
Outdated
|
|
||
| ## Upgrading From Spark SQL 2.4 to 3.0 | ||
|
|
||
| - Since Spark 3.0, we upgraded the built-in Hive to 2.3 for hadoop-3.x. This upgrade fixes some Hive issues: |
There was a problem hiding this comment.
for hadoop-3.x
when enabling the Hadoop 3.2+ profile.
|
Test build #105177 has finished for PR 24391 at commit
|
docs/sql-migration-guide-upgrade.md
Outdated
|
|
||
| ## Upgrading From Spark SQL 2.4 to 3.0 | ||
|
|
||
| - Since Spark 3.0, we upgraded the built-in Hive to 2.3 when enabling the Hadoop 3.2+ profile. This upgrade fixes some Hive issues: |
There was a problem hiding this comment.
some Hive issues -> the following issues:
|
Test build #105302 has finished for PR 24391 at commit
|
| // assert(storageFormat.properties.get("path") === expected) | ||
| // } | ||
| assert(storageFormat.locationUri === Some(expected)) | ||
| assert(Some(storageFormat.locationUri.get.getPath) === Some(expected.getPath)) |
There was a problem hiding this comment.
Do we need to add Some?
What is the reason we need to change this test case?
There was a problem hiding this comment.

Add Some to support both Hive 1.2 and 2.3.
There was a problem hiding this comment.
storageFormat.locationUri.map(_.getPath) then
| // We hard-code these configurations here to allow bin/spark-shell, bin/spark-sql | ||
| // and sbin/start-thriftserver.sh automatically creates Derby metastore. | ||
| hiveConf.setBoolean("hive.metastore.schema.verification", false) | ||
| hiveConf.setBoolean("datanucleus.schema.autoCreateAll", true) |
There was a problem hiding this comment.
Could you add a test case to ensure that we still respect the values set from users?
For example, if users set a different value, we do not reset them to our values.
There was a problem hiding this comment.
I update it to:
def conf: HiveConf = {
val hiveConf = state.getConf
// Hive changed the default of datanucleus.schema.autoCreateAll from true to false
// and hive.metastore.schema.verification from false to true since Hive 2.0.
// For details, see the JIRA HIVE-6113, HIVE-12463 and HIVE-1841.
// For the production environment. Either isDefaultMSUri or isDerbyMS should not be true.
// We hard-code hive.metastore.schema.verification and datanucleus.schema.autoCreateAll to allow
// bin/spark-shell, bin/spark-sql and sbin/start-thriftserver.sh to automatically create the
// Derby Metastore when running Spark in the non-production environment.
val isDefaultMSUri = hiveConf.getVar(METASTOREURIS).equals(METASTOREURIS.defaultStrVal)
val isDerbyMS = hiveConf.getVar(METASTORECONNECTURLKEY).startsWith("jdbc:derby")
if (isDefaultMSUri && isDerbyMS) {
hiveConf.setBoolean("hive.metastore.schema.verification", false)
hiveConf.setBoolean("datanucleus.schema.autoCreateAll", true)
}
hiveConf
}Because we don't know it's default value or set by user. so just set it for non-production environment.
|
My review is finished. Overall, it looks good to me. After we ensure that maven can pass all the tests, we also need to rerun SBT as well. |
|
@wangyum Thank you for your hard work!!! |
| for dep in dependencies: | ||
| dep.dependent_modules.add(self) | ||
| all_modules.append(self) | ||
| if name == "hive-thriftserver" and hadoop_version == "hadoop3.2": |
There was a problem hiding this comment.
Maybe leave a TODO here just to try to make sure that doesn't get lost
docs/sql-migration-guide-upgrade.md
Outdated
|
|
||
| ## Upgrading From Spark SQL 2.4 to 3.0 | ||
|
|
||
| - Since Spark 3.0, we upgraded the built-in Hive to 2.3 when enabling the Hadoop 3.2+ profile. This upgrade fixes the following issues: |
There was a problem hiding this comment.
Does this need to go in the migration guide? it's helpful info but does it help a user know what they need to do differently?
There was a problem hiding this comment.
The JIRA lists can be moved to the PR description, but we should document the actual behavior difference in migration guide.
There was a problem hiding this comment.
OK. Create SPARK-27686 to update migration guide
| // assert(storageFormat.properties.get("path") === expected) | ||
| // } | ||
| assert(storageFormat.locationUri === Some(expected)) | ||
| assert(Some(storageFormat.locationUri.get.getPath) === Some(expected.getPath)) |
There was a problem hiding this comment.
storageFormat.locationUri.map(_.getPath) then
sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/HiveOrcFilterSuite.scala
Show resolved
Hide resolved
|
Test build #105319 has finished for PR 24391 at commit
|
|
Test build #105326 has finished for PR 24391 at commit
|
|
|
||
| /** Returns the configuration for the current session. */ | ||
| def conf: HiveConf = state.getConf | ||
| def conf: HiveConf = { |
There was a problem hiding this comment.
To avoid a regression, could you change it to ?
if (!isHive23) {
state.getConf
} else {
...
}|
Test build #105344 has finished for PR 24391 at commit
|
|
retest this please |
|
Test build #105346 has finished for PR 24391 at commit
|
|
LGTM Thanks! Merged to master. |
| import re | ||
| import os | ||
|
|
||
| if os.environ.get("AMPLAB_JENKINS"): |
There was a problem hiding this comment.
@wangyum, this will shows the info every time this modules is imported. why did we do this here?
There was a problem hiding this comment.
okay. it's a temp fix so I'm fine. I will make a followup to handle https://github.com/apache/spark/pull/24639/files
There was a problem hiding this comment.
Skip the hive-thriftserver module when running the hadoop-3.2 test. Will remove it in another PR: https://github.com/apache/spark/pull/24628/files
What changes were proposed in this pull request?
This pr fix hadoop-3.2 test issues(except the
hive-thriftservermodule):hive.metastore.schema.verificationanddatanucleus.schema.autoCreateAllto HiveConf.After SPARK-27176 and this PR, we upgraded the built-in Hive to 2.3 when enabling the Hadoop 3.2+ profile. This upgrade fixes the following issues:
How was this patch tested?
This pr test Spark’s Hadoop 3.2 profile on jenkins and #24591 test Spark’s Hadoop 2.7 profile on jenkins
This PR close #24591