[SPARK-27036][SPARK-SQL] Cancel the running jobs in the background if broadcast future timeout error occurs #24036
Conversation
…ce broadcast timeout occurs ## What changes were proposed in this pull request? Currently even Broadcast thread is timed out, Jobs are not aborted and it will run in the baakground, as per current design the broadcast future will be submitting the job whose result needs to be broadcasted wiithin a particular time, when the broadcast timeout happens the jobs which are scheduled will not getting killed and it will continue running in background even though time out happens. As part of solution we shall get the jobs based on execution id from appstatus store and cancel the respective job before throwing out the Future time out exception, this can help to terminate the job promptly when TimeOutException happens, this will also save the additional resources getting utilized even after timeout exception thrown from driver. In UI also the jobs are getting failed after applying this patch. ## How was this patch tested? Manually
|
cc @srowen @HyukjinKwon @jinxing64 |
|
Is it necessary to kill all these jobs? I get that they will probably fail without the broadcast, but, it's also possible they won't. |
|
|
@srowen hope i clarified your question. thanks |
|
I don't feel strongly about it, but I am not sure it's worth this complexity. |
For short tasks it may not harm much but long running tasks can unnecessary hold the resources, and ultimately the query results in failure. Moreover we dont have any control on type of broadcast jobs, it may vary based on business use-cases. When the jobs are not able finish in 5 mins(Default Broadcast timeout time) which means it can turn out to be a long running job. |
|
@sujith71955 Few Questions,
|
|
@srowen then in this case how do we justify to the end user who will see that his query has failed (due to timeout) but his resource are still being occupied by the failed query (which may or may not eventually complete). I think killing such orphaned tasks justifies the case |
|
ok to test |
|
Test build #103314 has finished for PR 24036 at commit
|
|
@HyukjinKwon Any suggestions regarding this PR, please let me know for any inputs. thanks |
|
@HyukjinKwon @cloud-fan @srowen |
| } catch { | ||
| case ex: TimeoutException => | ||
| logError(s"Could not execute broadcast in ${timeout.toSeconds} secs.", ex) | ||
| val executionUIData = sqlContext.sparkSession.sharedState.statusStore. |
There was a problem hiding this comment.
Is this a reliable way to get the associated jobs?
There was a problem hiding this comment.
SQLAppStatusListener will hold the live execution data, so i use the same for getting the associated jobs , If its not efficient way of getting then i will revisit the code and try to find a better mechanism for getting the associated job for the particular execution Id. please let me know for any suggestions. thanks for your valuable time.
There was a problem hiding this comment.
I cannot find an alternative to get Jobs based on the execution id in this layer of execution, seems to be this way shall be reliable as whenever we are submitting /processing events via dagscheduler, we are always posting the events to SQLAppStatusListener, this will make our job viable to retrieve the jobs from LiveExecutionData.
Please let me know if we have any better way to get this job done. Thanks .
|
Gentle ping @HyukjinKwon @cloud-fan @srowen |
|
maybe this is not the right place to do it. We should have a query manager that watches all the broadcasting of a query and cancel the entire query if one broadcasting fails. |
|
Yeah this shall be a cleaner approach, Need to think on the design 😊. Will
workout on this part and let you guys know before implementation. Hope it’s
fine
…On Mon, 18 Mar 2019 at 3:36 PM, Wenchen Fan ***@***.***> wrote:
maybe this is not the right place to do it. We should have a query manager
that watches all the broadcasting of a query and cancel the entire query if
one broadcasting fails.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#24036 (comment)>, or mute
the thread
<https://github.com/notifications/unsubscribe-auth/AMZZ-T5lI28gzrs3l9msto9JA-LLS0K4ks5vX2UzgaJpZM4bmirB>
.
|
|
Can one of the admins verify this patch? |
|
closing this PR as this scenario is already handled in below PR |
What changes were proposed in this pull request?
Currently even Broadcast thread is timed out, Jobs are not aborted and it will run in the background.
As per current design the broadcast future will be waiting till the timeout for the job result, which needs to be broadcasted , when the broadcast future timeout happens the
job tasks running in the background will not getting killed and it will continue running in background.
As part of solution we shall get the jobs based on execution id from app-status store and cancel the respective job before throwing out the Future time out exception,
this can help to terminate the job and its respective tasks promptly when Timeout-exception happens, this will also save the additional resources getting utilized even after timeout exception thrown from driver.
After fix In Spark web UI the jobs are getting failed once timeout error occurs.
How was this patch tested?
Manually
Before fix
Actual Result : Timeout exception thrown and still task will be running in background, in spark web ui also the task execution will be in progress and after execution the job status shown successful, please refer attachments for more details.

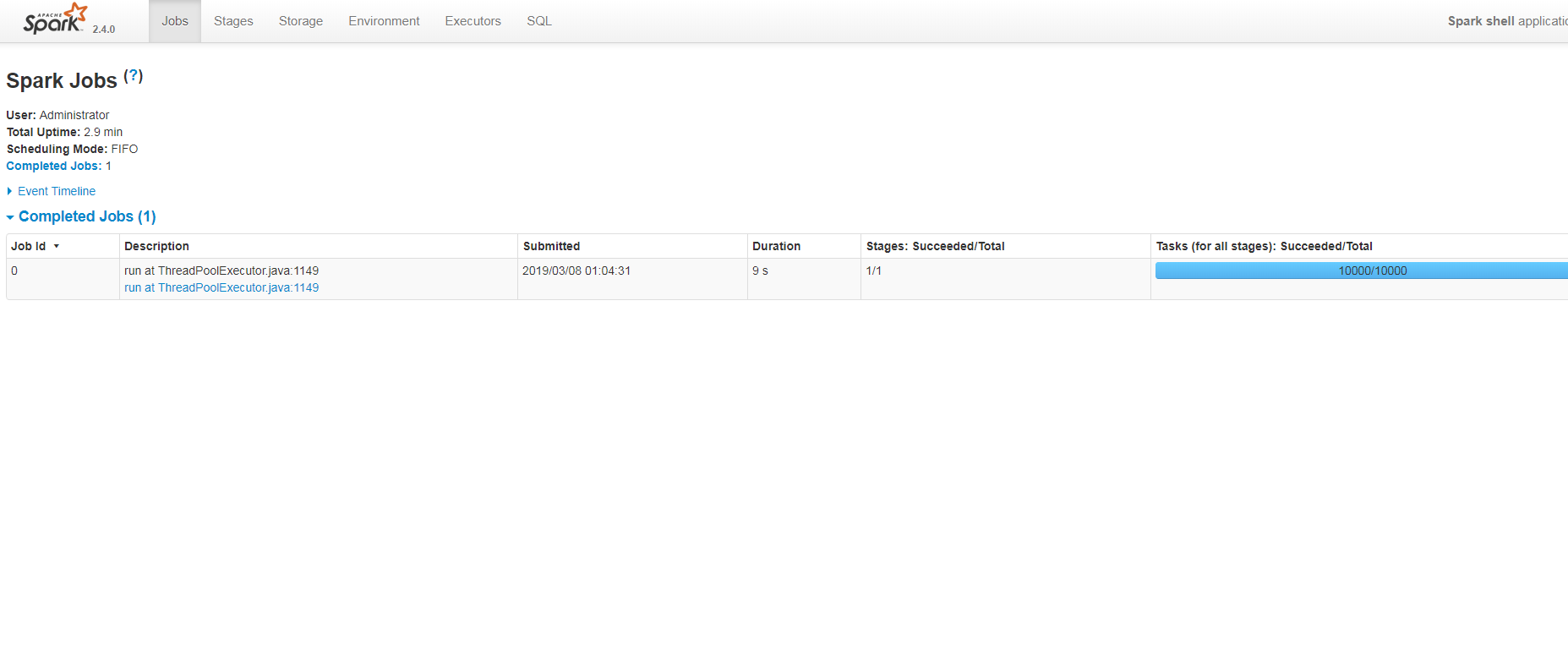
Web UI
After Fix:
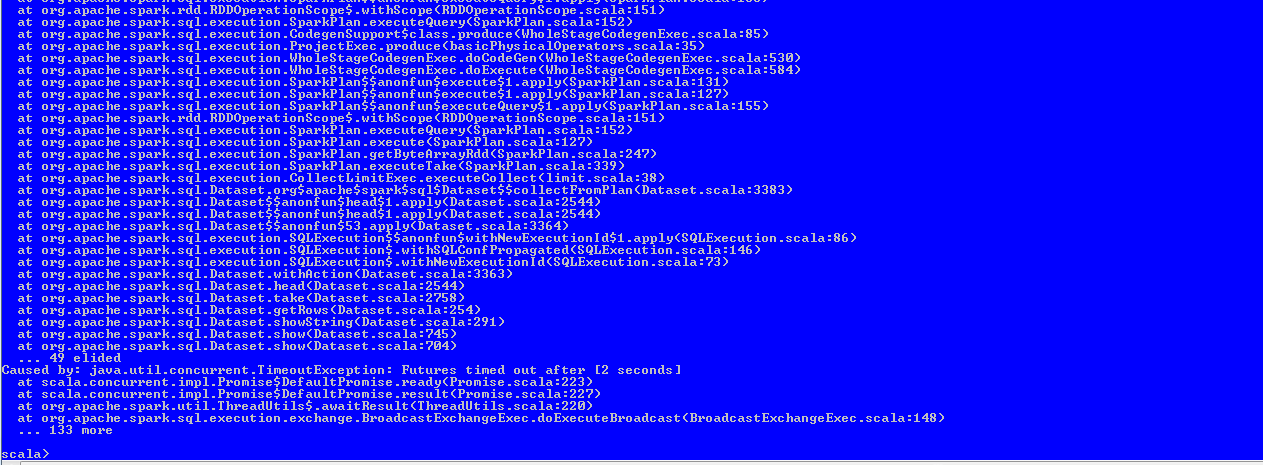
Once timeout occurs the job will be cancelled and even in UI the job status displayed as failed.
Web UI