[SPARK-25357][SQL] Add metadata to SparkPlanInfo to dump more information like file path to event log #22353
Conversation
… in incomplete information in event log
|
@cloud-fan @gatorsmile @dongjoon-hyun , kindly help to review. |
|
A scenario here is after an application completed, there is no way to know the intact file path of File Scan Exec if the path width is longer than 100 chars. Besides file location, other information (e.g ReadSchema) is also impacted. |
| override def simpleString: String = { | ||
| val metadataEntries = metadata.toSeq.sorted.map { | ||
| case (key, value) => | ||
| key + ": " + StringUtils.abbreviate(redact(value), 100) |
There was a problem hiding this comment.
How about parameterizing the second value as a new SQLConf? Or, defining verboseString?
There was a problem hiding this comment.
I think it’s overkill to parameterizing it. And Spark user doesn’t care about it, no one will reset it before submitting app. Besides, simply raise up to 1000 also can resolve the problem on most cases, but longer than 1000 chars is still meanlessness.
There was a problem hiding this comment.
We already have spark.debug.maxToStringFields for debugging, so is it bad to add spark.debug.XXXX? Anyway, if most users don't care about this, I think changing the default number goes too far.
There was a problem hiding this comment.
Spark users don’t care about it but platform team care. The purpose is to add the missing information back in event log since PR#18600
There was a problem hiding this comment.
It’s not for debugging, it’s for offline analysis based on event log. For example, analyze the input/out folders to build a data lineage /usage/hot point from all Spark apps.
 dongjoon-hyun
left a comment
dongjoon-hyun
left a comment
There was a problem hiding this comment.
This may cause a regression on Spark UI, @LantaoJin . Could you check that?
In fact, this abbreviation is introduced over two years ago at Spark 2.0 via [SPARK-14476][SQL] Improve the physical plan visualization by adding meta info like table name and file path for data source . We had better update the PR and JIRA description.
|
@LantaoJin . Please check the following example in Spark UI; the hover text on scala> spark.range(20000).repartition(10000).write.mode("overwrite").parquet("/tmp/10000")
scala> spark.read.parquet("/tmp/10000/*").count |
|
Thanks @dongjoon-hyun . That would be a problem. Seems setting to 200 or 500 cause a limited regression on hover text all the same. Hard code to 500 shows: |
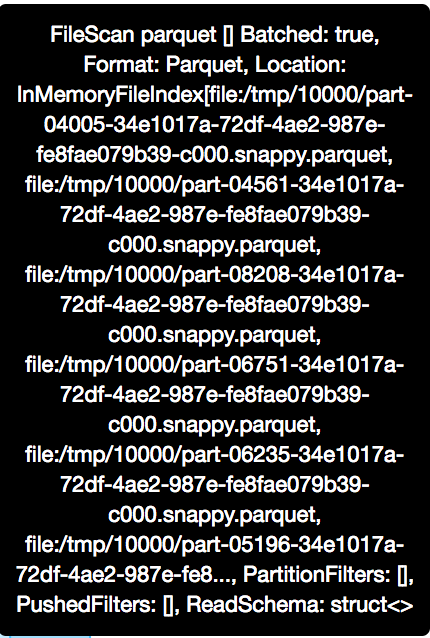
|
The purpose is logging meta info like file input file path to event log. So I revert the changes about simpleString and add back the metadata to SparkPlanInfo interface. This change will log metadata into event log in SparkListenerSQLExecutionStart and it is still benefited in #18600 . |
| * @return Metadata that describes more details of this SparkPlan. | ||
| */ | ||
| def metadata: Map[String, String] = Map.empty | ||
|
|
|
Although event log is in JSON format, it's mostly for internal usage, to be load by history server and used to build the Spark UI. For compatibility, we only focus on making history to be able to load event logs from different spark versions, not the event log itself. At the end it's still a log. Metadata is a hack which I really hate to add back. Can you describe more details about your use case? Let's see if we can solve it with the Spark driver log. |
Thanks @cloud-fan. AFAIK, there are more and more projects replay event log to analysis jobs offline, especially in a platform/infra team in a big company. Dr-elephant doesn't read event log, instead, query SHS to get information causing many problems like compatibility or data accuracy. In eBay we are building a system similar with Dr-elephant but much powerful. One of use cases in this system is building a data lineage and monitor the input/output path and data size for each application. Difference with Apache Altas who need attach a spark listener into the spark runtime, we choose to replay event log to build all context we need. Before 2.3, we can get above information from the |
|
Spark driver log is always distributed on various client nodes and depends on the log4j configs. In a big company, it's hard to collect them all and I think it's better to used for debug not analyze. |
|
So you need a way to reliably report some extra information like file path in the event logs, but don't want to show it in the UI as it maybe too long. Basically we shouldn't put such information in the event logs if it's not used in the UI, and we should build a new mechanism to make Spark easier to be analyzed. Also keep it mind that event logs are not reliable, Spark may drop some events if the event bus is too busy. I'm ok to add it back to the event logs since it was there before, but please don't add |
|
Thank you @cloud-fan for your reminding. We’ve handled the drop message case. Agree, I will update a commit tomorrow. |
|
ping @cloud-fan |
|
ok to test |
|
Test build #95993 has finished for PR 22353 at commit
|
| } | ||
|
|
||
| new SparkPlanInfo(plan.nodeName, plan.simpleString, children.map(fromSparkPlan), metrics) | ||
| // dump the file scan metadata (e.g file path) to event log |
There was a problem hiding this comment.
As a next step of reviews, did you have a chance to test this on your real environment at least TPCDS 1TB?
This seems to increase the event log traffic dramatically in the worst case. Can we have some comparison before and after this PR? @LantaoJin .
There was a problem hiding this comment.
Not yet. This field only removed from 2.3. The event log size should be same with before 2.3. The main increasing is input path. The example above read 10000 parquet files will log 10000 paths in one SQLExecutionStart event. No regression pathes. The size increased is foreseeable.
…tion like file path to event log ## What changes were proposed in this pull request? Field metadata removed from SparkPlanInfo in #18600 . Corresponding, many meta data was also removed from event SparkListenerSQLExecutionStart in Spark event log. If we want to analyze event log to get all input paths, we couldn't get them. Instead, simpleString of SparkPlanInfo JSON only display 100 characters, it won't help. Before 2.3, the fragment of SparkListenerSQLExecutionStart in event log looks like below (It contains the metadata field which has the intact information): >{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4..., "metadata": {"Location": "InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4/test5/snapshot/dt=20180904]","ReadSchema":"struct<snpsht_start_dt:date,snpsht_end_dt:date,am_ntlogin_name:string,am_first_name:string,am_last_name:string,isg_name:string,CRE_DATE:date,CRE_USER:string,UPD_DATE:timestamp,UPD_USER:string>"} After #18600, metadata field was removed. >{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4..., So I add this field back to SparkPlanInfo class. Then it will log out the meta data to event log. Intact information in event log is very useful for offline job analysis. ## How was this patch tested? Unit test Closes #22353 from LantaoJin/SPARK-25357. Authored-by: LantaoJin <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit 6dc5921) Signed-off-by: Wenchen Fan <[email protected]>
|
thanks, merging to master/2.4/2.3! |
…tion like file path to event log ## What changes were proposed in this pull request? Field metadata removed from SparkPlanInfo in #18600 . Corresponding, many meta data was also removed from event SparkListenerSQLExecutionStart in Spark event log. If we want to analyze event log to get all input paths, we couldn't get them. Instead, simpleString of SparkPlanInfo JSON only display 100 characters, it won't help. Before 2.3, the fragment of SparkListenerSQLExecutionStart in event log looks like below (It contains the metadata field which has the intact information): >{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4..., "metadata": {"Location": "InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4/test5/snapshot/dt=20180904]","ReadSchema":"struct<snpsht_start_dt:date,snpsht_end_dt:date,am_ntlogin_name:string,am_first_name:string,am_last_name:string,isg_name:string,CRE_DATE:date,CRE_USER:string,UPD_DATE:timestamp,UPD_USER:string>"} After #18600, metadata field was removed. >{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4..., So I add this field back to SparkPlanInfo class. Then it will log out the meta data to event log. Intact information in event log is very useful for offline job analysis. ## How was this patch tested? Unit test Closes #22353 from LantaoJin/SPARK-25357. Authored-by: LantaoJin <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit 6dc5921) Signed-off-by: Wenchen Fan <[email protected]>
…tion like file path to event log ## What changes were proposed in this pull request? Field metadata removed from SparkPlanInfo in apache#18600 . Corresponding, many meta data was also removed from event SparkListenerSQLExecutionStart in Spark event log. If we want to analyze event log to get all input paths, we couldn't get them. Instead, simpleString of SparkPlanInfo JSON only display 100 characters, it won't help. Before 2.3, the fragment of SparkListenerSQLExecutionStart in event log looks like below (It contains the metadata field which has the intact information): >{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4..., "metadata": {"Location": "InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4/test5/snapshot/dt=20180904]","ReadSchema":"struct<snpsht_start_dt:date,snpsht_end_dt:date,am_ntlogin_name:string,am_first_name:string,am_last_name:string,isg_name:string,CRE_DATE:date,CRE_USER:string,UPD_DATE:timestamp,UPD_USER:string>"} After apache#18600, metadata field was removed. >{"Event":"org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart", Location: InMemoryFileIndex[hdfs://cluster1/sys/edw/test1/test2/test3/test4..., So I add this field back to SparkPlanInfo class. Then it will log out the meta data to event log. Intact information in event log is very useful for offline job analysis. ## How was this patch tested? Unit test Closes apache#22353 from LantaoJin/SPARK-25357. Authored-by: LantaoJin <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
What changes were proposed in this pull request?
Field metadata removed from SparkPlanInfo in #18600 . Corresponding, many meta data was also removed from event SparkListenerSQLExecutionStart in Spark event log. If we want to analyze event log to get all input paths, we couldn't get them. Instead, simpleString of SparkPlanInfo JSON only display 100 characters, it won't help.
Before 2.3, the fragment of SparkListenerSQLExecutionStart in event log looks like below (It contains the metadata field which has the intact information):
After #18600, metadata field was removed.
So I add this field back to SparkPlanInfo class. Then it will log out the meta data to event log. Intact information in event log is very useful for offline job analysis.
How was this patch tested?
Unit test