[SPARK-23413][UI] Fix sorting tasks by Host / Executor ID at the Stage page #20601
Conversation
| HEADER_STATUS -> TaskIndexNames.STATUS, | ||
| HEADER_LOCALITY -> TaskIndexNames.LOCALITY, | ||
| HEADER_EXECUTOR -> TaskIndexNames.EXECUTOR, | ||
| HEADER_HOST -> TaskIndexNames.EXECUTOR, |
There was a problem hiding this comment.
sorting by host and executor is not the same ... you might have executors 1 & 5 on host A, and execs 2,3,4 on host B.
The 2.2 UI had both executor and host in the same column: https://github.com/apache/spark/blob/branch-2.2/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala#L1203
I think we either need to go back to having one column for both, or add an index on host.
thoughts @vanzin ?
There was a problem hiding this comment.
Seems we'd better have a new TaskIndexNames for host column.
There was a problem hiding this comment.
Hmmm... I agree that the correct thing would be to sort by host and have an index on that. The problem is that we'd be changing the data on disk, breaking compatibility with previous versions of the disk store. So unless that change goes into 2.3.0, that means revving the disk version number, which would require re-parsing all logs. And that kinda sucks. (I hope by the next major version I - or someone - get time to better investigate versioning of the disk data.)
Given this affects 2.3 we could potentially consider it a blocker. @sameeragarwal probably won't be very happy though.
2.2 actually sorts by executor id, and doesn't have a separate host column (added in SPARK-21675). That's one of these small changes I missed while merging all the SHS stuff.
There was a problem hiding this comment.
another alternative is to disable sorting by host, and just fix sorting by executor. That could go into 2.3.1 without breaking compatibility.
There was a problem hiding this comment.
I think that is good idea. I can extend taskHeadersAndCssClasses to store Tuple3 objects where the additional Boolean property flags whether the column is sortable. And for a not sortable column we are skipping the headerLink.
There was a problem hiding this comment.
or even go back to the 2.2 behavior, with executor & host in the same column.
I do think having a separate column for host, and having it be sortable, is actually better ... but just trying to think of simple solutions.
There was a problem hiding this comment.
Looks like we'll have a new RC, so I'll jump in the bandwagon and mark this one a blocker too. We can then add the new index in 2.3.0.
|
Test build #87411 has finished for PR 20601 at commit
|
| val HEADER_INPUT_SIZE = "Input Size / Records" | ||
| val HEADER_OUTPUT_SIZE = "Output Size / Records" | ||
| val HEADER_SHUFFLE_READ_TIME = "Shuffle Read Blocked Time" | ||
| val HEADER_SHUFFLE_TOTAL_READS = "Shuffle Read Size / Records" |
There was a problem hiding this comment.
nit: HEADER_SHUFFLE_TOTAL_READS -> HEADER_SHUFFLE_READ_SIZE ?
There was a problem hiding this comment.
In the header constants naming I have followed the existing task index names:
HEADER_SHUFFLE_TOTAL_READS -> TaskIndexNames.SHUFFLE_TOTAL_READS,|
I'm trying to think of a way that we can avoid these issues going forward - not that I expect this code to change much. Maybe have a unit test that makes sure all declared header constants are mapped to some index, or something like that, and fails if you add a new header constant without a mapping. |
|
@attilapiros could you take a look at the test case Ryan added in #20615 and add something like that to your patch? It'd be nice to catch these things in unit tests. |
|
Yes, of course. The test of @zsxwing is perfect to avoid similar problems in the future. |
|
LGTM pending tests. |
|
Test build #87477 has finished for PR 20601 at commit
|
|
jenkins retest this please |
|
Test build #87478 has finished for PR 20601 at commit
|
|
ah, flaky tests. retest this please |
|
LGTM |
|
Test build #87481 has finished for PR 20601 at commit
|
|
Everything that might have changed from this has passed, the failures are known flaky tests: https://issues.apache.org/jira/browse/SPARK-23369 https://issues.apache.org/jira/browse/SPARK-23390 merging to master / 2.3 |
…e page
## What changes were proposed in this pull request?
Fixing exception got at sorting tasks by Host / Executor ID:
```
java.lang.IllegalArgumentException: Invalid sort column: Host
at org.apache.spark.ui.jobs.ApiHelper$.indexName(StagePage.scala:1017)
at org.apache.spark.ui.jobs.TaskDataSource.sliceData(StagePage.scala:694)
at org.apache.spark.ui.PagedDataSource.pageData(PagedTable.scala:61)
at org.apache.spark.ui.PagedTable$class.table(PagedTable.scala:96)
at org.apache.spark.ui.jobs.TaskPagedTable.table(StagePage.scala:708)
at org.apache.spark.ui.jobs.StagePage.liftedTree1$1(StagePage.scala:293)
at org.apache.spark.ui.jobs.StagePage.render(StagePage.scala:282)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82)
at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:687)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
at org.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:848)
at org.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584)
```
Moreover some refactoring to avoid similar problems by introducing constants for each header name and reusing them at the identification of the corresponding sorting index.
## How was this patch tested?
Manually:
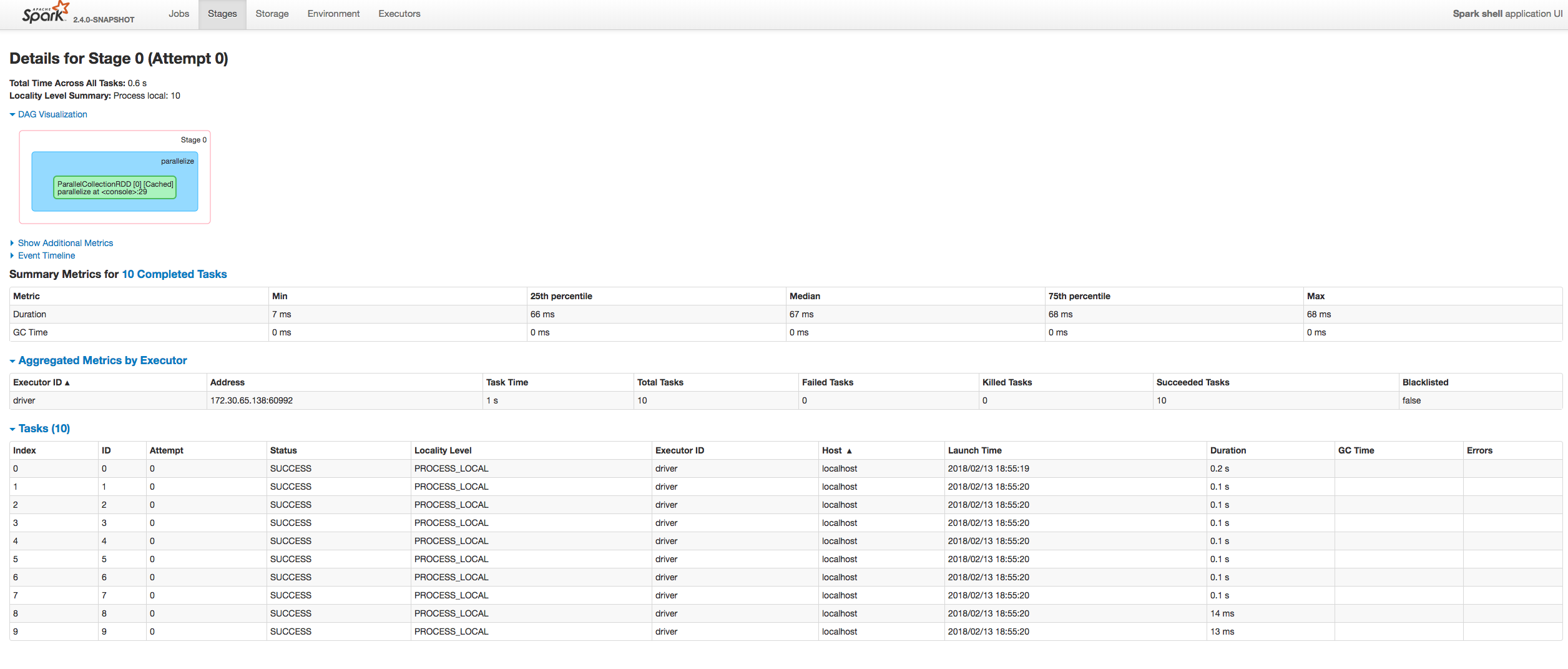
Author: “attilapiros” <[email protected]>
Closes apache#20601 from attilapiros/SPARK-23413.
(cherry picked from commit 1dc2c1d)
{kind=link}
|
ack I merged to master but screwed up on 2.3 -- fixing that here: #20623 |
|
Test build #87487 has finished for PR 20601 at commit
|
What changes were proposed in this pull request?
Fixing exception got at sorting tasks by Host / Executor ID:
Moreover some refactoring to avoid similar problems by introducing constants for each header name and reusing them at the identification of the corresponding sorting index.
How was this patch tested?
Manually: