[SPARK-2059][SQL] Add analysis checks #1263
Closed
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
Merged build triggered. |
|
Merged build started. |
|
Merged build finished. |
|
Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/16245/ |
Contributor
|
Maybe also add a test case? |
rxin
added a commit
to rxin/spark
that referenced
this pull request
Jun 30, 2014
[SPARK-2059][SQL] Add analysis checks
asfgit
pushed a commit
that referenced
this pull request
Jul 4, 2014
This replaces #1263 with a test case. Author: Reynold Xin <[email protected]> Author: Michael Armbrust <[email protected]> Closes #1265 from rxin/sql-analysis-error and squashes the following commits: a639e01 [Reynold Xin] Added a test case for unresolved attribute analysis. 7371e1b [Reynold Xin] Merge pull request #1263 from marmbrus/analysisChecks 448c088 [Michael Armbrust] Add analysis checks
asfgit
pushed a commit
that referenced
this pull request
Jul 4, 2014
This replaces #1263 with a test case. Author: Reynold Xin <[email protected]> Author: Michael Armbrust <[email protected]> Closes #1265 from rxin/sql-analysis-error and squashes the following commits: a639e01 [Reynold Xin] Added a test case for unresolved attribute analysis. 7371e1b [Reynold Xin] Merge pull request #1263 from marmbrus/analysisChecks 448c088 [Michael Armbrust] Add analysis checks (cherry picked from commit b3e768e) Signed-off-by: Reynold Xin <[email protected]>
asfgit
pushed a commit
that referenced
this pull request
Jul 4, 2014
This replaces #1263 with a test case. Author: Reynold Xin <[email protected]> Author: Michael Armbrust <[email protected]> Closes #1265 from rxin/sql-analysis-error and squashes the following commits: a639e01 [Reynold Xin] Added a test case for unresolved attribute analysis. 7371e1b [Reynold Xin] Merge pull request #1263 from marmbrus/analysisChecks 448c088 [Michael Armbrust] Add analysis checks (cherry picked from commit b3e768e) Signed-off-by: Reynold Xin <[email protected]>
xiliu82
pushed a commit
to xiliu82/spark
that referenced
this pull request
Sep 4, 2014
This replaces apache#1263 with a test case. Author: Reynold Xin <[email protected]> Author: Michael Armbrust <[email protected]> Closes apache#1265 from rxin/sql-analysis-error and squashes the following commits: a639e01 [Reynold Xin] Added a test case for unresolved attribute analysis. 7371e1b [Reynold Xin] Merge pull request apache#1263 from marmbrus/analysisChecks 448c088 [Michael Armbrust] Add analysis checks
wangyum
added a commit
that referenced
this pull request
May 26, 2023
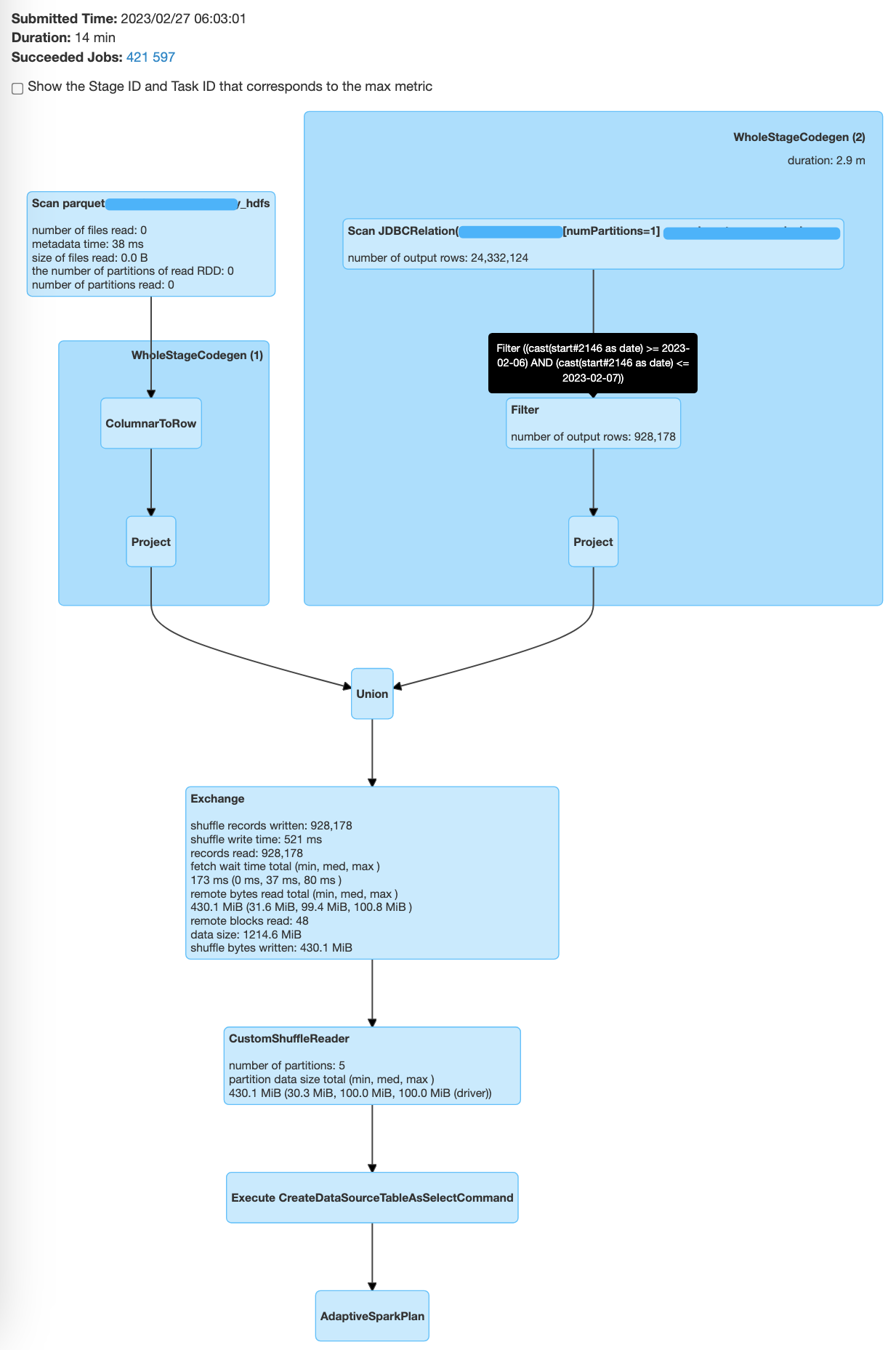
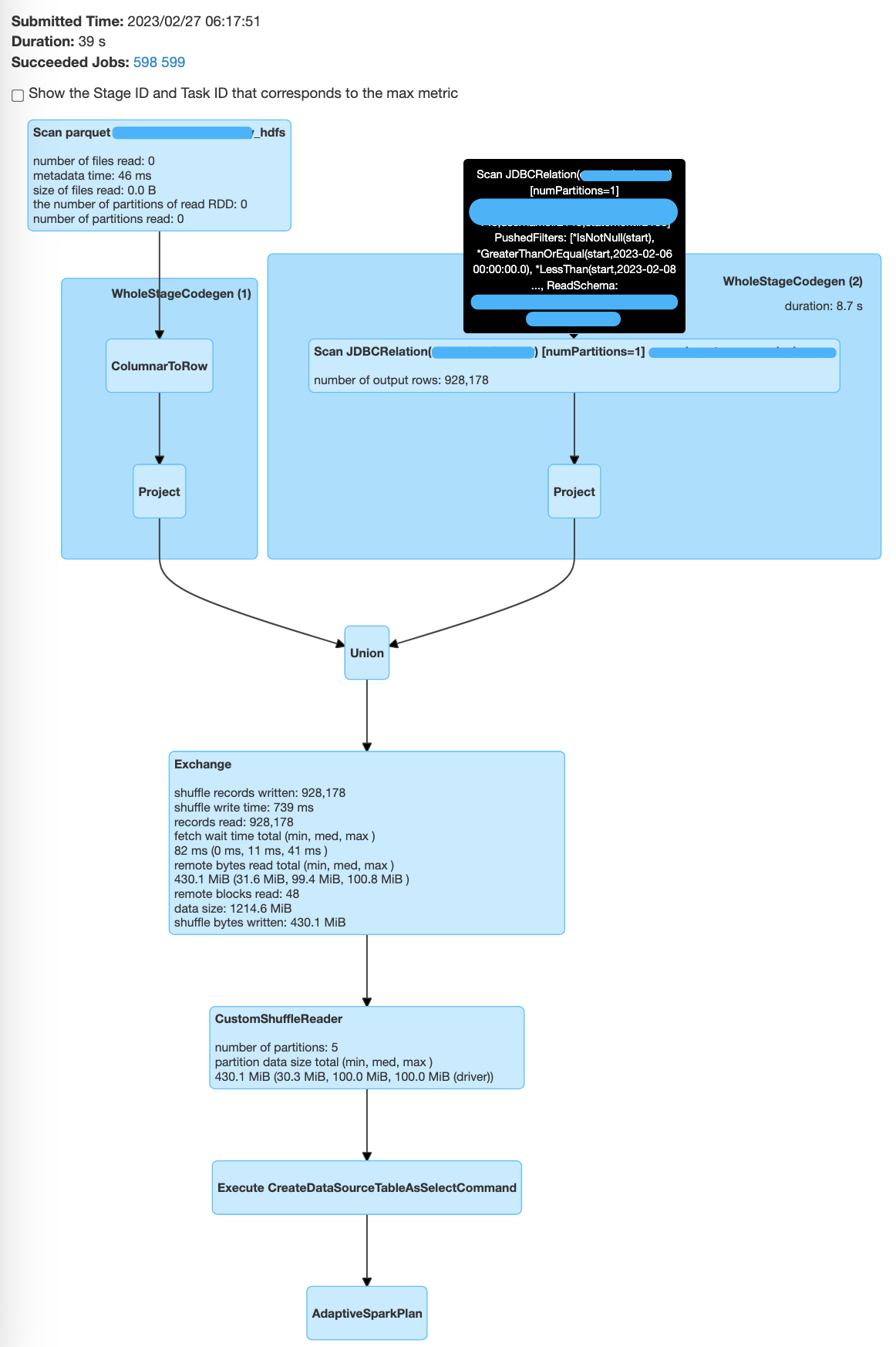
…#1263) ### What changes were proposed in this pull request? This PR enhance `UnwrapCastInBinaryComparison` to support unwrap timestamp type. The way to unwrap timestamp type are: ``` GreaterThan(Cast(ts, DateType), date) -> GreaterThanOrEqual(ts, Cast(date + 1, TimestampType)) GreaterThanOrEqual(Cast(ts, DateType), date) -> GreaterThanOrEqual(ts, Cast(date, TimestampType)) LessThan(Cast(ts, DateType), date) -> LessThan(ts, Cast(date, TimestampType)) LessThanOrEqual(Cast(ts, DateType), date) -> LessThan(ts, Cast(date + 1, TimestampType)) EqualTo(Cast(ts, DateType), date) -> And(GreaterThanOrEqual(ts, Cast(date, TimestampType)), LessThan(ts, Cast(date + 1, TimestampType))) ``` ### Why are the changes needed? Improve query performance. A common use case. We store cold data in HDFS by partition, store hot data in MySQL, and then union all the results. The filter in the MySQL branch cannot be pushed down, which affects performance: ```sql CREATE TABLE t_cold(id bigint, start timestamp, dt date) using parquet PARTITIONED BY (dt); CREATE TABLE t_hot(id bigint, start timestamp) using org.apache.spark.sql.jdbc OPTIONS (`url` '***', `dbtable` 'db.t2', `user` 'spark', `password` '***'); CREATE VIEW all_data AS SELECT * FROM t_cold UNION ALL SELECT *, to_date(start) FROM t_hot; SELECT * FROM all_data WHERE start BETWEEN '2023-02-06' AND '2023-02-07'; ``` Before this PR | After this PR -- | -- <img src="https://user-images.githubusercontent.com/5399861/221576723-7fc45356-65db-48e2-8d40-88420c21c9f5.png" width="400" height="730"> | <img src="https://user-images.githubusercontent.com/5399861/221575848-5b975ed0-70ab-4527-acfe-796cc20e169b.png" width="400" height="730"> ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test.
{kind=link}
{kind=link}
ashevchuk123
pushed a commit
to mapr/spark
that referenced
this pull request
Oct 27, 2025
…code and UI for MultiauthWebUiFilter (apache#1263)
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
3 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
An initial version of analysis checks. Long term we are going to want something more complete, but this at least prevents us from making it all the way execution with obvious problems. For example, doing a sort on a misspelled attribute is actually enough to kill the DAG scheduler.