Commit d3255a5
revert [SPARK-21743][SQL] top-most limit should not cause memory leak
## What changes were proposed in this pull request?
There is a performance regression in Spark 2.3. When we read a big compressed text file which is un-splittable(e.g. gz), and then take the first record, Spark will scan all the data in the text file which is very slow. For example, `spark.read.text("/tmp/test.csv.gz").head(1)`, we can check out the SQL UI and see that the file is fully scanned.
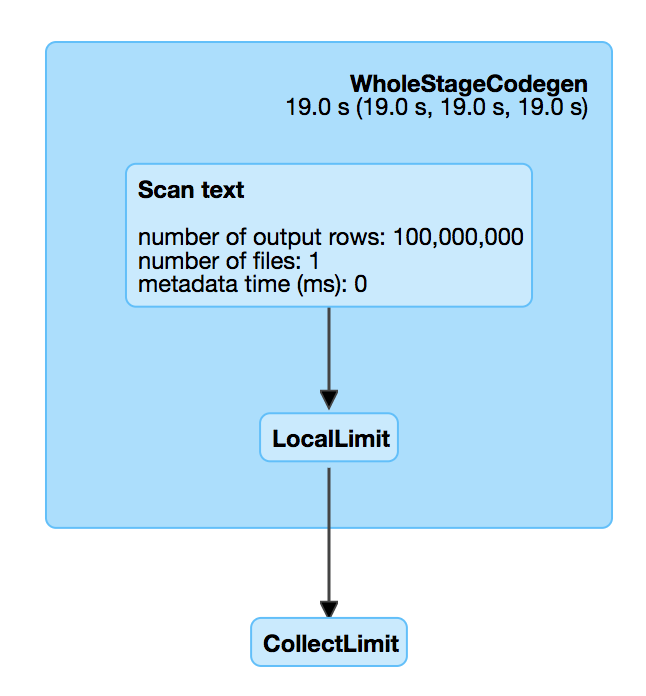
This is introduced by #18955 , which adds a LocalLimit to the query when executing `Dataset.head`. The foundamental problem is, `Limit` is not well whole-stage-codegened. It keeps consuming the input even if we have already hit the limitation.
However, if we just fix LIMIT whole-stage-codegen, the memory leak test will fail, as we don't fully consume the inputs to trigger the resource cleanup.
To fix it completely, we should do the following
1. fix LIMIT whole-stage-codegen, stop consuming inputs after hitting the limitation.
2. in whole-stage-codegen, provide a way to release resource of the parant operator, and apply it in LIMIT
3. automatically release resource when task ends.
Howere this is a non-trivial change, and is risky to backport to Spark 2.3.
This PR proposes to revert #18955 in Spark 2.3. The memory leak is not a big issue. When task ends, Spark will release all the pages allocated by this task, which is kind of releasing most of the resources.
I'll submit a exhaustive fix to master later.
## How was this patch tested?
N/A
Author: Wenchen Fan <[email protected]>
Closes #21573 from cloud-fan/limit.{kind=link}
1 parent 7f1708a commit d3255a5
File tree
2 files changed
+1
-11
lines changed- sql/core/src
- main/scala/org/apache/spark/sql/execution
- test/scala/org/apache/spark/sql
2 files changed
+1
-11
lines changedLines changed: 1 addition & 6 deletions
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
70 | 70 | | |
71 | 71 | | |
72 | 72 | | |
73 | | - | |
74 | | - | |
75 | | - | |
76 | | - | |
77 | | - | |
78 | | - | |
| 73 | + | |
79 | 74 | | |
80 | 75 | | |
81 | 76 | | |
| |||
Lines changed: 0 additions & 5 deletions
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
2720 | 2720 | | |
2721 | 2721 | | |
2722 | 2722 | | |
2723 | | - | |
2724 | | - | |
2725 | | - | |
2726 | | - | |
2727 | | - | |
2728 | 2723 | | |
2729 | 2724 | | |
2730 | 2725 | | |
| |||
0 commit comments