Add wangchanberta #540
Add wangchanberta #540
Conversation
|
Hello @wannaphong! Thanks for updating this PR. We checked the lines you've touched for PEP 8 issues, and found: There are currently no PEP 8 issues detected in this Pull Request. Cheers! 🍻 Comment last updated at 2021-03-15 15:56:14 UTC |
fixed grouped_entities
|
Google colab notebook for test: https://colab.research.google.com/drive/1VfM7161u5ExKD6vFMDmxFTZf19EnrhgI?usp=sharing |
There was a problem hiding this comment.
Can you fix the behavior where it adds _ in the beginning of sentence token? This is an artifact from when we train the model:
t.get_ner("ผมกินข้าวที่มหาลัยจุฬา",tag=True)
>> ▁ผมกินข้าวที่<ORGANIZATION>มหาลัย</ORGANIZATION><ORGANIZATION>จุฬา</ORGANIZATION>
I think it would be better for users if we return:
t.get_ner("ผมกินข้าวที่มหาลัยจุฬา",tag=True)
>> ผมกินข้าวที่<ORGANIZATION>มหาลัย</ORGANIZATION><ORGANIZATION>จุฬา</ORGANIZATION>
Also, I understand this is probably not best practice but the model tends to split entities like มหาลัย and จุฬา above (both labelled B-ORG by the model). Do you think it will be better if we merge B-X, B-X to X even though it is not B-X, I-X?
Yes, It can choices |
Fixed. |
still returns |
|
Before merging this PR, perhaps, it might be useful to compare the proposed and the equivalent existing ones in PyThaiNLP. According to โมเดลประมวลผลภาษาไทยที่ใหญ่และก้าวหน้าที่สุดในขณะนี้ (Medium, 2020), it seems
IMHO, doing this comparison would allow us to
|
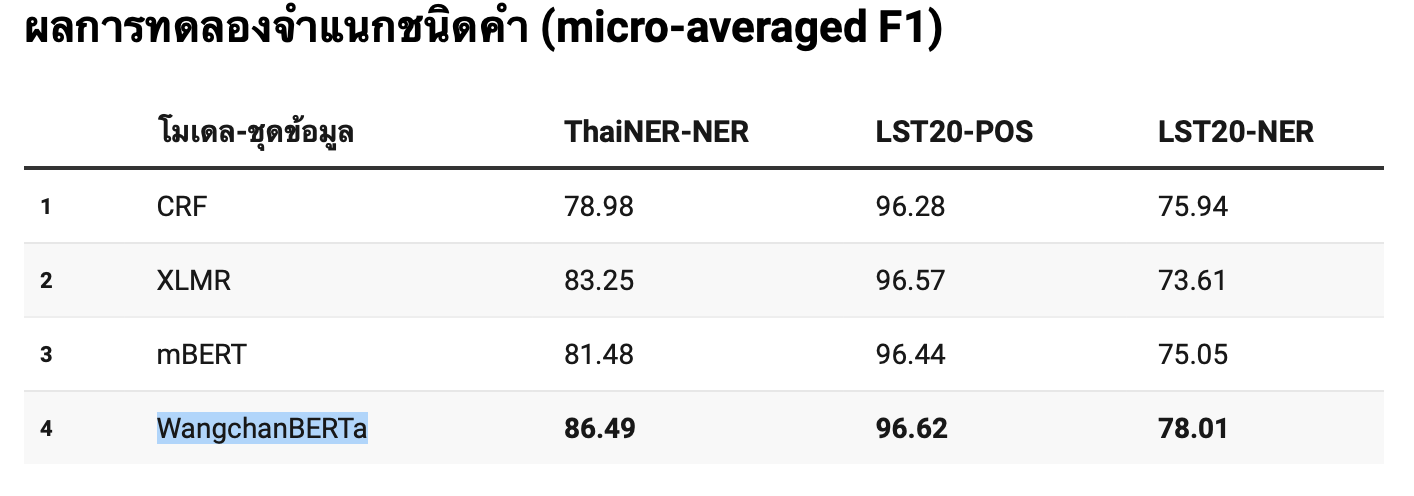
|
@wannaphong The issue for WangchanBERTa has been resolved in the getting started notebook. |
Agreed speed benchmark is a nice thing to have, although I would not mind merging without since users will have the choice to choose which modules (CRF or WangchanBERTa) when they use it anyways. |
Fixed |
|
LGTM. You can add the speed benchmark @heytitle asked for later. |
I think that could be done later. |
Speed Benchmark
Notebook: |
LGTM |
What does this changes
I add ner from
wangchanbertamodel.GitHub: https://github.com/vistec-AI/thai2transformers
How to used
Your checklist for this pull request
🚨Please review the guidelines for contributing to this repository.