Misspelling Model #549
Description
Detailed description
In most of practical settings, text often contains misspelling that could deteriorate NLP algorithms. To simulate such situations and evaluate how the problems could affect our algorithms, we need to simulate such misspelling.
I propose to create a misspelling model based on neighborhood characters with respect to the standard Thai keyboard layout. For example, consider ก we could replace it with ห ำ พ ด ป แ (illustrated below).
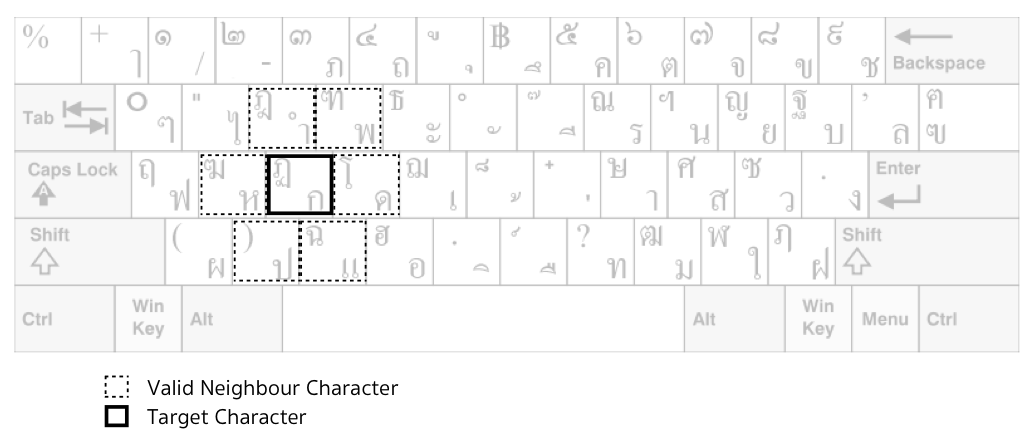
For Thai characters that require to type with Shift, its neighbor characters are at the same buttons. For example, consider ฏ, its neighbor characters are ฆ ฎ ฑ โ ) ฉ
For a sentence, we can randomly select a character in a sentence and replaced it with its randomly selected neighborhood character as mentioned above. For example, consider a sentence นาย[ก]พูดไม่รู้เรื่อง where we assume that [_] is the location we want to simulate a misspelling. These are possible misspelled versions that we can randomly select
นาย[ห]พูดไม่รู้เรื่อง
นาย[ำ]พูดไม่รู้เรื่อง
นาย[พ]พูดไม่รู้เรื่อง
นาย[ด]พูดไม่รู้เรื่อง
นาย[ป]พูดไม่รู้เรื่อง
นาย[แ]พูดไม่รู้เรื่อง
Context
When we have this model, we could test how much these tasks are affected
- syllable and word tokenization
- part-of-speech tagging
- name entity recognition
Possible implementation
My prototype can be found at https://colab.research.google.com/drive/1N3EeYyfTN8Qd8m5io6kzGqB5ndV6gA6J#scrollTo=ipeVmYz_0YcX.