Add async train doc #400
Add async train doc #400
Conversation
|
请先提供预览效果图 |
…to add-async-train-doc
|
|
|
|
|
|
|
这个PR里有三篇文档,能分3个PR么,有助于merge。 |
| pserver模式分布式异步训练 | ||
| ====================== | ||
|
|
||
| API详细使用方法参考 :ref:<DistributeTranspiler> ,简单实例用法: |
|
|
||
| 以上参数中: | ||
|
|
||
| - :code:`trainer_id` : trainer节点的id,从0到n-1,n为当前训练任务中trainer节点的个数 |
There was a problem hiding this comment.
其他的参数说明可以ref到同步?这里说明异步只需要修改sync_mode?
There was a problem hiding this comment.
其他的参数说明可以ref到同步?这里说明异步只需要修改sync_mode?
同意@typhoonzero 的意见。
|
|
||
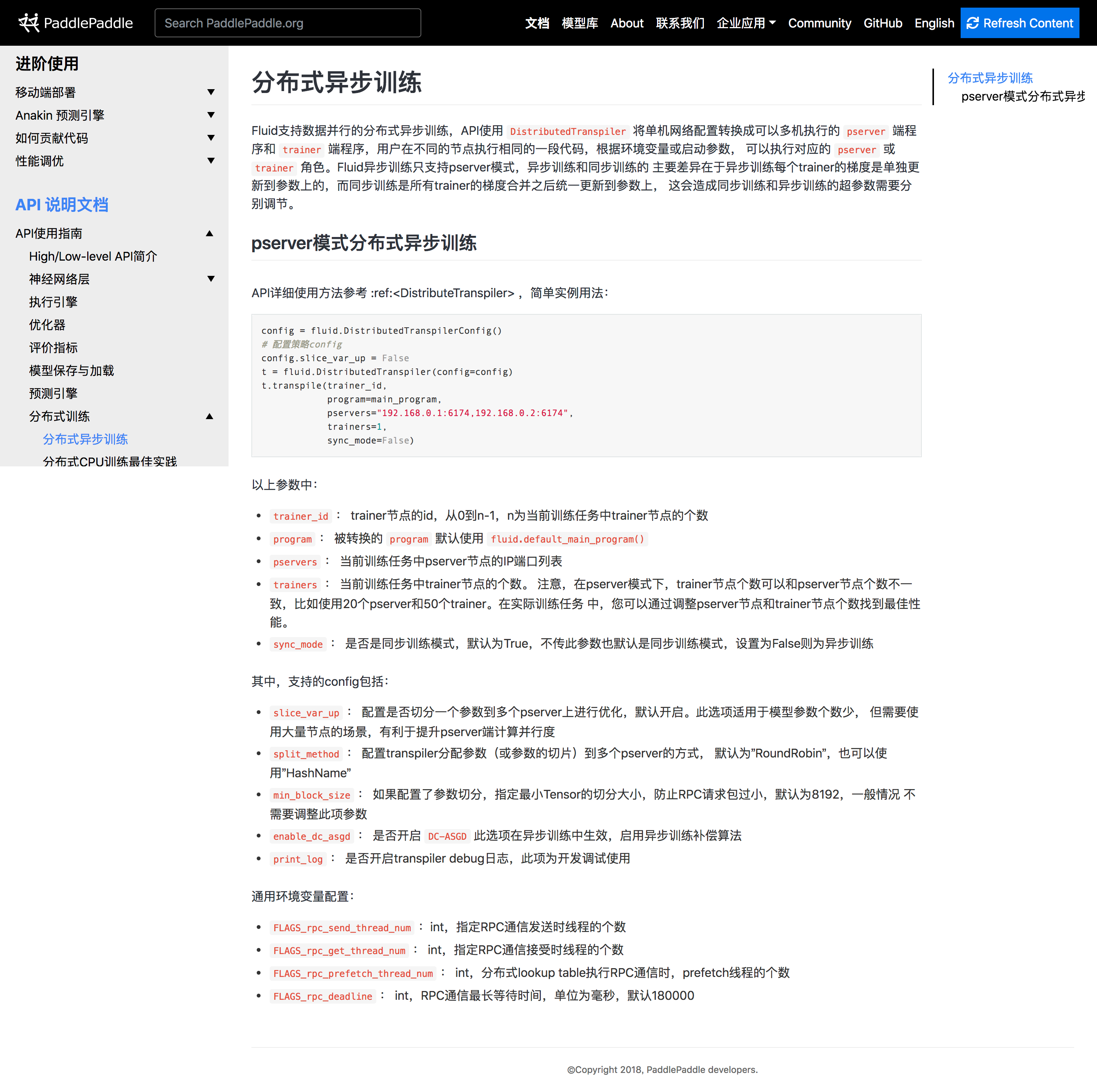
| Fluid支持数据并行的分布式异步训练,API使用 :code:`DistributedTranspiler` 将单机网络配置转换成可以多机执行的 | ||
| :code:`pserver` 端程序和 :code:`trainer` 端程序,用户在不同的节点执行相同的一段代码,根据环境变量或启动参数, | ||
| 可以执行对应的 :code:`pserver` 或 :code:`trainer` 角色。Fluid异步训练只支持pserver模式,异步训练和同步训练的 |
| pserver模式分布式异步训练 | ||
| ====================== | ||
|
|
||
| API详细使用方法参考 :ref:<DistributeTranspiler> ,简单实例用法: |
There was a problem hiding this comment.
| API详细使用方法参考 :ref:<DistributeTranspiler> ,简单实例用法: | |
| API详细使用方法参考 :ref: `api_fluid_DistributeTranspiler` ,简单实例用法: |
| 分布式CPU训练最佳实践 | ||
| ################## | ||
|
|
||
| 提高CPU分布式训练的训练速度,主要要从两个方面来考虑,一个是提高训练速度,这个方面主要是要提高CPU的使用率,另外一方面 |
There was a problem hiding this comment.
提高CPU分布式训练的训练速度,主要要从两个方面来考虑:1)提高训练速度,主要是提高CPU的使用率;2)提高通信速度,主要是减少通信传输的数据量。
|
|
||
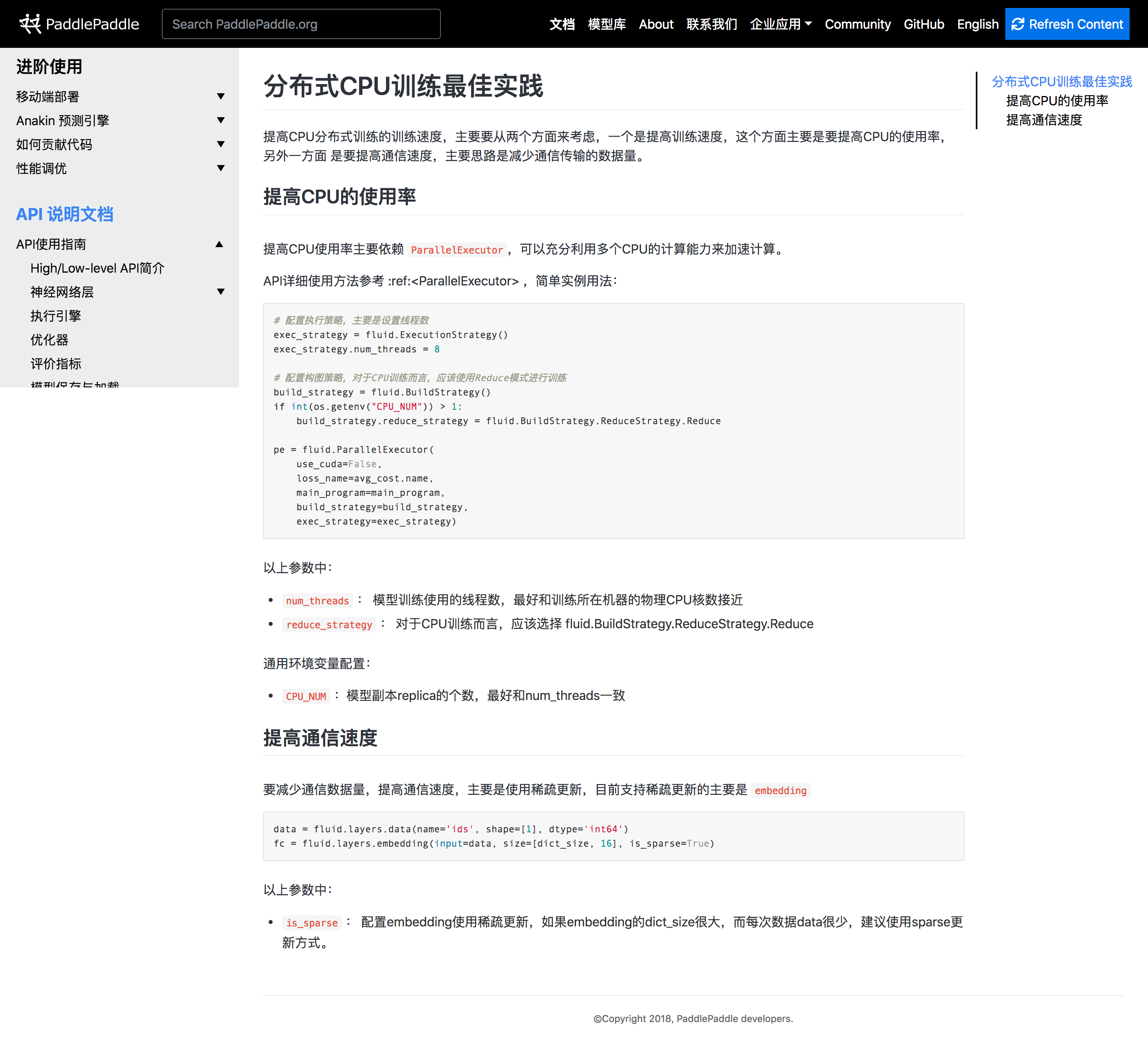
| 提高CPU使用率主要依赖 :code:`ParallelExecutor`,可以充分利用多个CPU的计算能力来加速计算。 | ||
|
|
||
| API详细使用方法参考 :ref:<ParallelExecutor> ,简单实例用法: |
There was a problem hiding this comment.
| API详细使用方法参考 :ref:<ParallelExecutor> ,简单实例用法: | |
| API详细使用方法参考 :ref:`api_fluid_ParallelExecutor` ,简单实例用法: |
| ============= | ||
|
|
||
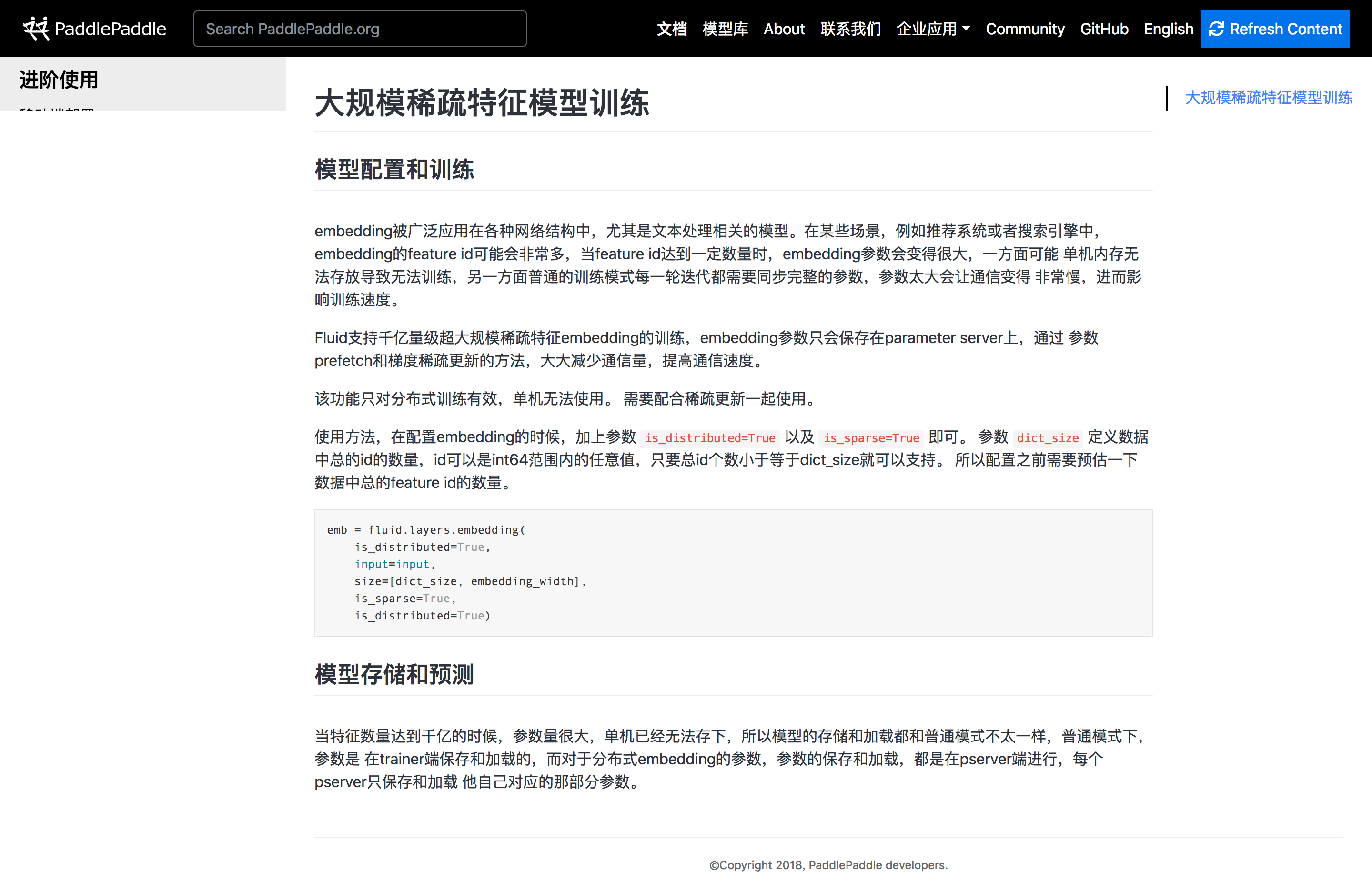
| embedding被广泛应用在各种网络结构中,尤其是文本处理相关的模型。在某些场景,例如推荐系统或者搜索引擎中, | ||
| embedding的feature id可能会非常多,当feature id达到一定数量时,embedding参数会变得很大,一方面可能 |
There was a problem hiding this comment.
embedding参数会变得很大,会带来两个问题:1)单机内存由于无法存放如此巨大的embedding参数,导致无法训练;2)普通的训练模式每一轮迭代都需要同步完整的参数,参数太大会让通信变得非常慢,进而影响训练速度。
| 该功能只对分布式训练有效,单机无法使用。 | ||
| 需要配合稀疏更新一起使用。 | ||
|
|
||
| 使用方法,在配置embedding的时候,加上参数 :code:`is_distributed=True` 以及 :code:`is_sparse=True` 即可。 |
There was a problem hiding this comment.
| 使用方法,在配置embedding的时候,加上参数 :code:`is_distributed=True` 以及 :code:`is_sparse=True` 即可。 | |
| 使用方法:在配置embedding的时候,加上参数 :code:`is_distributed=True` 以及 :code:`is_sparse=True` 即可。 |
或者把“使用方法”作为一个小标题,在前面加项目符号
| 模型存储和预测 | ||
| ============= | ||
|
|
||
| 当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不太一样,普通模式下,参数是 |
There was a problem hiding this comment.
| 当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不太一样,普通模式下,参数是 | |
| 当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不一致,普通模式下,参数是 |
There was a problem hiding this comment.
所以模型的存储和加载都和普通模式不太一样:1)普通模式下,参数是在trainer端保存和加载的;2)分布式模式下,参数的保存和加载,都是在pserver端进行,每个pserver只保存和加载xxx。
| 模型存储和预测 | ||
| ============= | ||
|
|
||
| 当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不太一样,普通模式下,参数是 |
| ============= | ||
|
|
||
| 当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不太一样,普通模式下,参数是 | ||
| 在trainer端保存和加载的,而对于分布式embedding的参数,参数的保存和加载,都是在pserver端进行,每个pserver只保存和加载 |
|
|
||
| 当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不太一样,普通模式下,参数是 | ||
| 在trainer端保存和加载的,而对于分布式embedding的参数,参数的保存和加载,都是在pserver端进行,每个pserver只保存和加载 | ||
| 他自己对应的那部分参数。 No newline at end of file |
There was a problem hiding this comment.
| 他自己对应的那部分参数。 | |
| 该pserver对应部分的参数。 |
| ############ | ||
|
|
||
| Fluid支持数据并行的分布式异步训练,API使用 :code:`DistributedTranspiler` 将单机网络配置转换成可以多机执行的 | ||
| :code:`pserver` 端程序和 :code:`trainer` 端程序,用户在不同的节点执行相同的一段代码,根据环境变量或启动参数, |
There was a problem hiding this comment.
。(逗号改句号)用户在不同的节点执行相同的一段代码,
| Fluid支持数据并行的分布式异步训练,API使用 :code:`DistributedTranspiler` 将单机网络配置转换成可以多机执行的 | ||
| :code:`pserver` 端程序和 :code:`trainer` 端程序,用户在不同的节点执行相同的一段代码,根据环境变量或启动参数, | ||
| 可以执行对应的 :code:`pserver` 或 :code:`trainer` 角色。Fluid异步训练只支持pserver模式,异步训练和同步训练的 | ||
| 主要差异在于异步训练每个trainer的梯度是单独更新到参数上的,而同步训练是所有trainer的梯度合并之后统一更新到参数上, |
| :code:`pserver` 端程序和 :code:`trainer` 端程序,用户在不同的节点执行相同的一段代码,根据环境变量或启动参数, | ||
| 可以执行对应的 :code:`pserver` 或 :code:`trainer` 角色。Fluid异步训练只支持pserver模式,异步训练和同步训练的 | ||
| 主要差异在于异步训练每个trainer的梯度是单独更新到参数上的,而同步训练是所有trainer的梯度合并之后统一更新到参数上, | ||
| 这会造成同步训练和异步训练的超参数需要分别调节。 |
There was a problem hiding this comment.
“这会造成同步训练和异步训练的超参数需要分别调节”-》因此,同步训练和异步训练的超参数需要分别调节。
|
|
||
| 以上参数中: | ||
|
|
||
| - :code:`trainer_id` : trainer节点的id,从0到n-1,n为当前训练任务中trainer节点的个数 |
There was a problem hiding this comment.
其他的参数说明可以ref到同步?这里说明异步只需要修改sync_mode?
同意@typhoonzero 的意见。
|
|
||
| Fluid支持数据并行的分布式异步训练,API使用 :code:`DistributedTranspiler` 将单机网络配置转换成可以多机执行的 | ||
| :code:`pserver` 端程序和 :code:`trainer` 端程序,用户在不同的节点执行相同的一段代码,根据环境变量或启动参数, | ||
| 可以执行对应的 :code:`pserver` 或 :code:`trainer` 角色。Fluid异步训练只支持pserver模式,异步训练和同步训练的 |
| 分布式CPU训练最佳实践 | ||
| ################## | ||
|
|
||
| 提高CPU分布式训练的训练速度,主要要从两个方面来考虑,一个是提高训练速度,这个方面主要是要提高CPU的使用率,另外一方面 |
There was a problem hiding this comment.
提高CPU分布式训练的训练速度,主要要从两个方面来考虑:1)提高训练速度,主要是提高CPU的使用率;2)提高通信速度,主要是减少通信传输的数据量。
| 提高通信速度 | ||
| ========== | ||
|
|
||
| 要减少通信数据量,提高通信速度,主要是使用稀疏更新,目前支持稀疏更新的主要是 :code:`embedding` |
There was a problem hiding this comment.
- 49行加句号。
- 稀疏更新,等 Add sparse update API guide. #399 merge后,加入内链。 @shanyi15
- embedding需要加内链。
| ============= | ||
|
|
||
| embedding被广泛应用在各种网络结构中,尤其是文本处理相关的模型。在某些场景,例如推荐系统或者搜索引擎中, | ||
| embedding的feature id可能会非常多,当feature id达到一定数量时,embedding参数会变得很大,一方面可能 |
There was a problem hiding this comment.
embedding参数会变得很大,会带来两个问题:1)单机内存由于无法存放如此巨大的embedding参数,导致无法训练;2)普通的训练模式每一轮迭代都需要同步完整的参数,参数太大会让通信变得非常慢,进而影响训练速度。
| 参数prefetch和梯度稀疏更新的方法,大大减少通信量,提高通信速度。 | ||
|
|
||
| 该功能只对分布式训练有效,单机无法使用。 | ||
| 需要配合稀疏更新一起使用。 |
| 模型存储和预测 | ||
| ============= | ||
|
|
||
| 当特征数量达到千亿的时候,参数量很大,单机已经无法存下,所以模型的存储和加载都和普通模式不太一样,普通模式下,参数是 |
There was a problem hiding this comment.
所以模型的存储和加载都和普通模式不太一样:1)普通模式下,参数是在trainer端保存和加载的;2)分布式模式下,参数的保存和加载,都是在pserver端进行,每个pserver只保存和加载xxx。
|
Done |
|
还有 #400 (comment) 没有修改。 |
这里不太确定怎么改,请 @jacquesqiao 看一下 |
|
Done |
No description provided.