Opencl improvements #579
Opencl improvements #579
Conversation
|
Having two tables instead of one is actually slower than to compute them directly. We talked about it here: #222. Or did you meant something else? |
|
I will update the PR with the suggested changes tomorrow. |
|
There are two other things. One is The other one is please use |
|
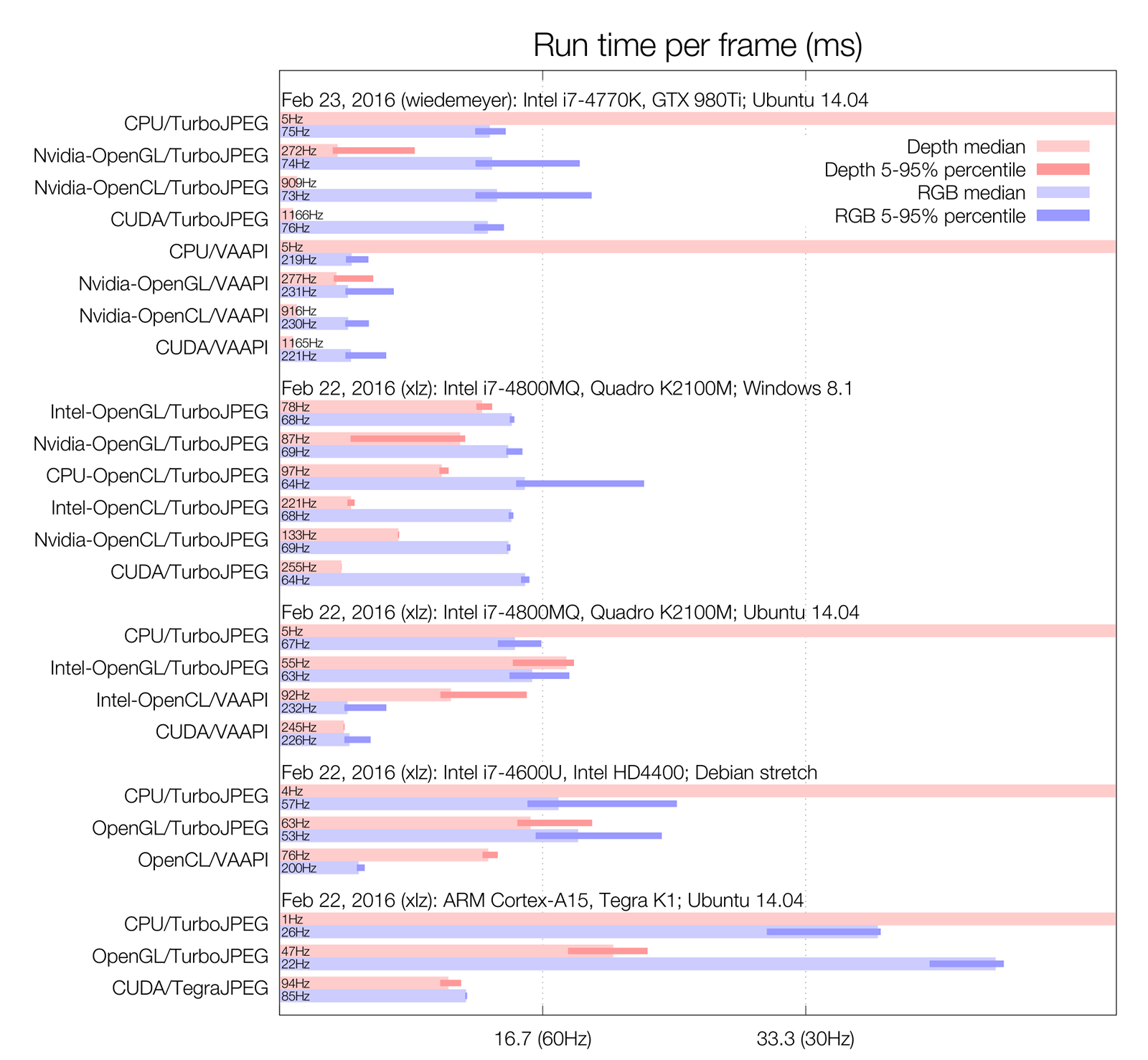
When you're done with the PR, please also provide some benchmark results using steps in https://github.com/OpenKinect/libfreenect2/wiki/Performance Results so far: Probably all of it has to be redone after your OpenCL optimization. |
…ses on the GPU, they are now precomputed once on the CPU. Details: Replaced sin(a+b) by sin(a)*cos(b)+cos(a)*sin(b), where sin(a),cos(b),cos(a),sin(b) are stored in a LUT. Simplyfied processPixelStage1 code and removed processMeasurementTriple. Moved one if from decodePixelMeasurement to processPixelStage1. Removed the first part of `valid && any(...)` because valid has been checked before.
…ion. loadXZTables, loadLookupTable and loadP0TablesFromCommandResponse will now directly write to the OpenCL buffers.
Reverted back to calculating sine and cosine on the GPU.
…_CL_ERROR obsolete.
Usage of LIBFREENECT2_WITH_PROFILING. Changed CHECK_CL macros. OpenCLAllocator can now be used for input and output buffers. OpenCLFrame now uses OpenCLBuffer from allocator. IMAGE_SIZE and LUT_SIZE as static const. Added Allocators for input and output buffers. Moved allocate_opencl to top. Added good method.
|
Here are the benchmark results.
|
||||||||||||||||||||||||
Enabling profiling in OpenCL effects the performance, so for profiling libfreenect2s processors, it should be disabled and only used when testing improvements of the OpenCL code itself.
|
I added all the recommended changes except the |
|
Which GPU (Intel or Nvidia) did the OpenCL case use? (Hopefully both Intel and Nvidia GPUs can be tested with OpenCL) |
|
Nvidia, i edited the previous post. |
|
I reviewed some of the changes. There is a lot of back and forth so it's no longer practical to reorganize this into standalone functional patches. I'll merge the code as-is but will format the subjects and commit messages. Do you want to add something in CMakeLists.txt to turn on LIBFREENECT2_WITH_PROFILING_CL more easily or revert it to a file-level macro like |
|
I have added your results to the wiki (Do you have permissions to edit it?). Also after reviewing your patches I realize the CUDA processor still lacks some of the improvement you added here, good catches. |
|
The back and forth wasn't intended. |
|
You can add the benchmark results directly to the wiki next time. I'll try to add the per core usage stats programmatically. |
|
Well, per core usage is not that important. Adding the stats is quite intrusive so I give up. |
|
Manually merged. If you don't feel like it, just ignore and not collect the per core usage. So far it is only useful in identifying the memory access on Tegra is extremely slow. |
|
@wiedemeyer Can you run the CUDA test again? Hopefully VAAPI will have smaller variance. |
|
yes, I will run it this afternoon. |
|
@xlz But there is something wrong with the CUDA processor. When I run VAAPI with CUDA Protonect uses ~70% CPU, that is much compared to OpenCL with only ~33% CPU, or OpenGL with ~41% CPU. The CPU usage refers to the usage of the whole process as show by htop. You can also see that in the results from the profiling in the wiki. |
|
I'll render the image. According the your usage data, only the registration in the main thread has unusual CPU usage. It's weird. There really is nothing special in the registration routines. I'll take a look at what's going on on my side. You can check too. |
|
I ran kinect2_bidge and subscribed to |
|
The slowness in Registration is caused by a wrong write combined flag used in CUDA. Fixed in 18d1cff This fix doesn't seem to have significant effect on performance in CUDA or VAAPI. |
|
But it fixed the high CPU load with CUDA. I updated the CPU usage in my wiki performance entries. |
Which this PR includes:
With this improvements the OpenCL depth processor takes between 1.09 ms and 1.11 ms on my system, instead of ~2 ms. Most due to the pinned memory.