replace inv and det for 4x4 matrices, #260
Conversation
|
Failure is in 32bit systems due to fact that implicit conversion to float is to Float32. What do you recommend? |
Can you be more specific what is going on? There is no Float, only Float32 and Float64 (unlike Int, Int32, Int64) because also 32 bit systems have Float64. |
|
inv. and det for 4x4 do not specify type explicitly but instead rely on the system automatic promotion for x64 bit systems the test for ill conditioned matrix of size 4x4 passes EDIT: the original test was :@test_broken , that is, was supposed to fail on all systems. |
|
I think I am specifically curious which promotions go different on 32 systems. |
|
I may have a 32 bit system behind my facsimile sitting on top of my laser-disc ... no its not there anymore. :-) I agree it is interesting(it might have implications on embedded systems), but I can't help with that. |
|
The test is with a |
|
Yes, that is what I thought, but wasn't sure about. But it is not a catastrophic loss of accuracy anyway, replacing 10* by 12* would be a simple solution. |
Codecov Report
@@ Coverage Diff @@
## master #260 +/- ##
==========================================
+ Coverage 89.38% 92.63% +3.25%
==========================================
Files 36 36
Lines 2629 2622 -7
==========================================
+ Hits 2350 2429 +79
+ Misses 279 193 -86
Continue to review full report at Codecov.
|

|
Just chiming in since I was pointed here by @mschauer. Yes, AppVeyor 32-bit seems to apply different optimizations than 64-bit. We found this by very carefully comparing a whole bunch of different algorithms, and found some very small differences even when some macros were removed. SciML/DelayDiffEq.jl#20 As @fredrikekre points out:
Both 32-bit and 64-bit use |
| @test_broken norm(Matrix(inv(sm)*sm - eye(4))) < 10*norm(inv(m)*m - eye(4)) | ||
| @test_broken norm(Matrix(sm*inv(sm) - eye(4))) < 10*norm(m*inv(m) - eye(4)) | ||
| @test norm(Matrix(inv(sm)*sm - eye(4))) < 12*norm(inv(m)*m - eye(4)) | ||
| @test norm(Matrix(sm*inv(sm) - eye(4))) < 12*norm(m*inv(m) - eye(4)) |
There was a problem hiding this comment.
These tests were particularly chosen as examples where the previous implementation had trouble. So they're probably not that relevant to the new implementation.
Presumably we'd be able to find some equivalent problems by rerunning the code at the bottom of this file.
There was a problem hiding this comment.
This is still a difficult case (as evidenced by the bounds being quite tight). But running the problem generator would be a good idea.
| @test norm(Matrix(sm*inv(sm) - eye(4))) < 10*norm(m*inv(m) - eye(4)) | ||
| @test norm(Matrix(inv(sm)*sm - eye(4))) < 10*norm(inv(m)*m - eye(4)) | ||
| @test norm(Matrix(sm*inv(sm) - eye(4))) < 12*norm(m*inv(m) - eye(4)) | ||
| @test norm(Matrix(inv(sm)*sm - eye(4))) < 12*norm(inv(m)*m - eye(4)) |
There was a problem hiding this comment.
This change is ok I think. There's nothing special about the factor of 10 which you've replaced with 12 here. I'd say some difference is to be expected with a switch in algorithms.
src/inv.jl
Outdated
| (A[1,3]*A[2,4]*A[3,1] - A[1,4]*A[2,3]*A[3,1] + A[1,4]*A[2,1]*A[3,3] - A[1,1]*A[2,4]*A[3,3] - A[1,3]*A[2,1]*A[3,4] + A[1,1]*A[2,3]*A[3,4]) * idet | ||
| (A[1,4]*A[2,2]*A[3,1] - A[1,2]*A[2,4]*A[3,1] - A[1,4]*A[2,1]*A[3,2] + A[1,1]*A[2,4]*A[3,2] + A[1,2]*A[2,1]*A[3,4] - A[1,1]*A[2,2]*A[3,4]) * idet | ||
| (A[1,2]*A[2,3]*A[3,1] - A[1,3]*A[2,2]*A[3,1] + A[1,3]*A[2,1]*A[3,2] - A[1,1]*A[2,3]*A[3,2] - A[1,2]*A[2,1]*A[3,3] + A[1,1]*A[2,2]*A[3,3]) * idet] | ||
| return SMatrix{4,4,eltype(B),16}(B) |
There was a problem hiding this comment.
The return type here should arguably be deduced using similar_type rather than always returning SMatrix. See, for example, the implementations of _inv for the smaller sizes.
The idea here is that users can preserve the container type of their static matrix if they so please. I'm not sure this is used a lot in practice, but best for consistency to keep the same pattern.
There was a problem hiding this comment.
Agreed , waiting for my pull request regarding det.jl to be merged into master, since there are additional small fixes,and then I will merge back master here and change it to be consistent (adding the similar_type instead of SMatrix)
There was a problem hiding this comment.
Updated everywhere to return similar_type and not SMatrix
src/det.jl
Outdated
| end | ||
|
|
||
| @inline function _det(::Size{(4,4)}, A::StaticMatrix,S::Type) | ||
| A = similar_type(A,S)(A) |
There was a problem hiding this comment.
There used to be compiler (type inference) problems with variable names that change types. Has this been fixed? (I.e. is code optimal here when eltype(A) != S?)
There was a problem hiding this comment.
yes there is a difference , it is not big (about 2 ns difference) , but the code produced if
we avoid variable name changing type looks better .it looks like what you would expect hand optimized assembly code would look like, a long list of vector intrinsics.
There was a problem hiding this comment.
Any preferred style?
I thought of changing each function that this line appears as the first line in this way:
@inline function _det(::Size{(3,3)}, A::StaticMatrix, S::Type)
A = similar_type(A,S)(A)
would become:
@inline function _det(::Size{(3,3)}, _A::StaticMatrix, S::Type)
A = similar_type(_A,S)(_A)
There was a problem hiding this comment.
Or move the promoting to the dispatching function all together and dropping the propagation of the promoted type.
Better in my opinion
@andyferris Both will work , what style do you prefer?
There was a problem hiding this comment.
By now, I am used to the "SSA" form so I do tend to write a2 = f(a); a3 = g(a2) etc. In this case something like A_S would look clear.
Dispatch might be a very clean solution - the line won't even appear when S is already correct, which may be important for e.g. heap allocated static arrays or if similar_type always changes types or if the compiler doesn't optimize away the construction for some reason.
So let's try dispatch!
|
@c42f your requested changes are in place, det inv and logdet give correct result in a speedy manner for matrices of small size up to size 4 with any type that Base supports including integer and unsigned , and calls Base on large matrices |
src/inv.jl
Outdated
| T = eltype(A) | ||
| S = typeof((one(T)*zero(T) + zero(T))/one(T)) | ||
| newtype = similar_type(A, S) | ||
| A_S = similar_type(A,S)(A) |
There was a problem hiding this comment.
A_S = convert(similar_type(A, S), A)
src/det.jl
Outdated
| T = eltype(A) | ||
| S = typeof((one(T)*zero(T) + zero(T))/one(T)) | ||
| _det(Size(A),A,S) | ||
| A_S = similar_type(A,S)(A) |
There was a problem hiding this comment.
A_S = convert(similar_type(A, S), A)
There was a problem hiding this comment.
Can potentially remove a new allocation of e.g. a MMatrix.
There was a problem hiding this comment.
I dont see that changes anything , but I am updating anyway
There was a problem hiding this comment.
And the biggest problem is that inv for MMatrix returns SMatrix
|
Hi guys, any chance that this is getting in soon? |
|
Ah, this one slipped off my radar. Looks good now thanks. @mschauer I did rerun the problem generator, and it produced the following graphs which compare the two different methods of computing the 4x4 inverse with the Base implementation: Partitioning method (previous) Adjugate method (changes here) So clearly the new method behaves more robustly for well conditioned matrices (the dark blue blob is tight). If nothing else, it's clear we need to do this well, so I think this is a reasonable tradeoff for now. The new method does have some has some systematic problems for approximately low ranked matrices, where if fares a lot worse than the previous method. We'll just have to put up with that for now. |
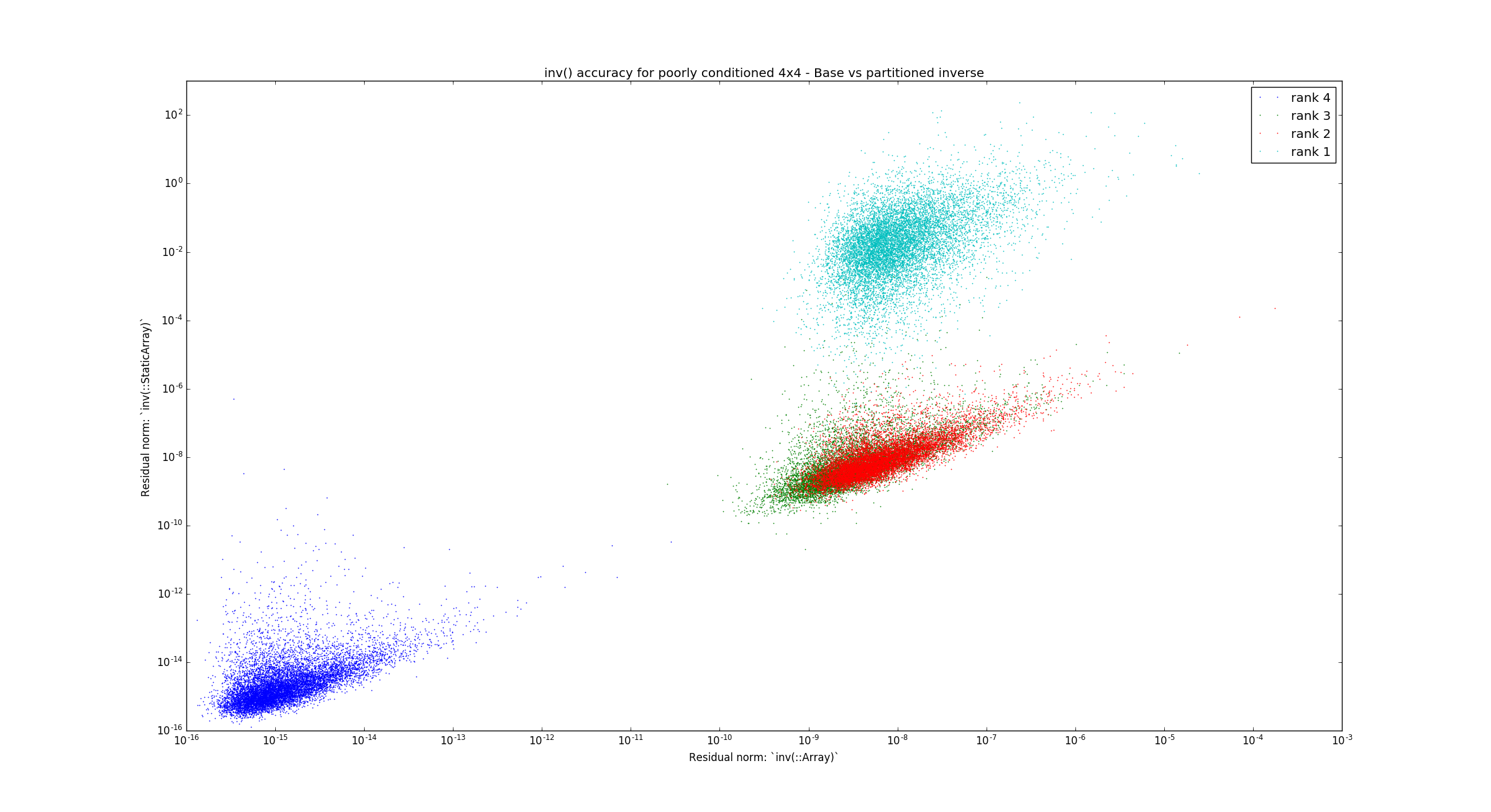
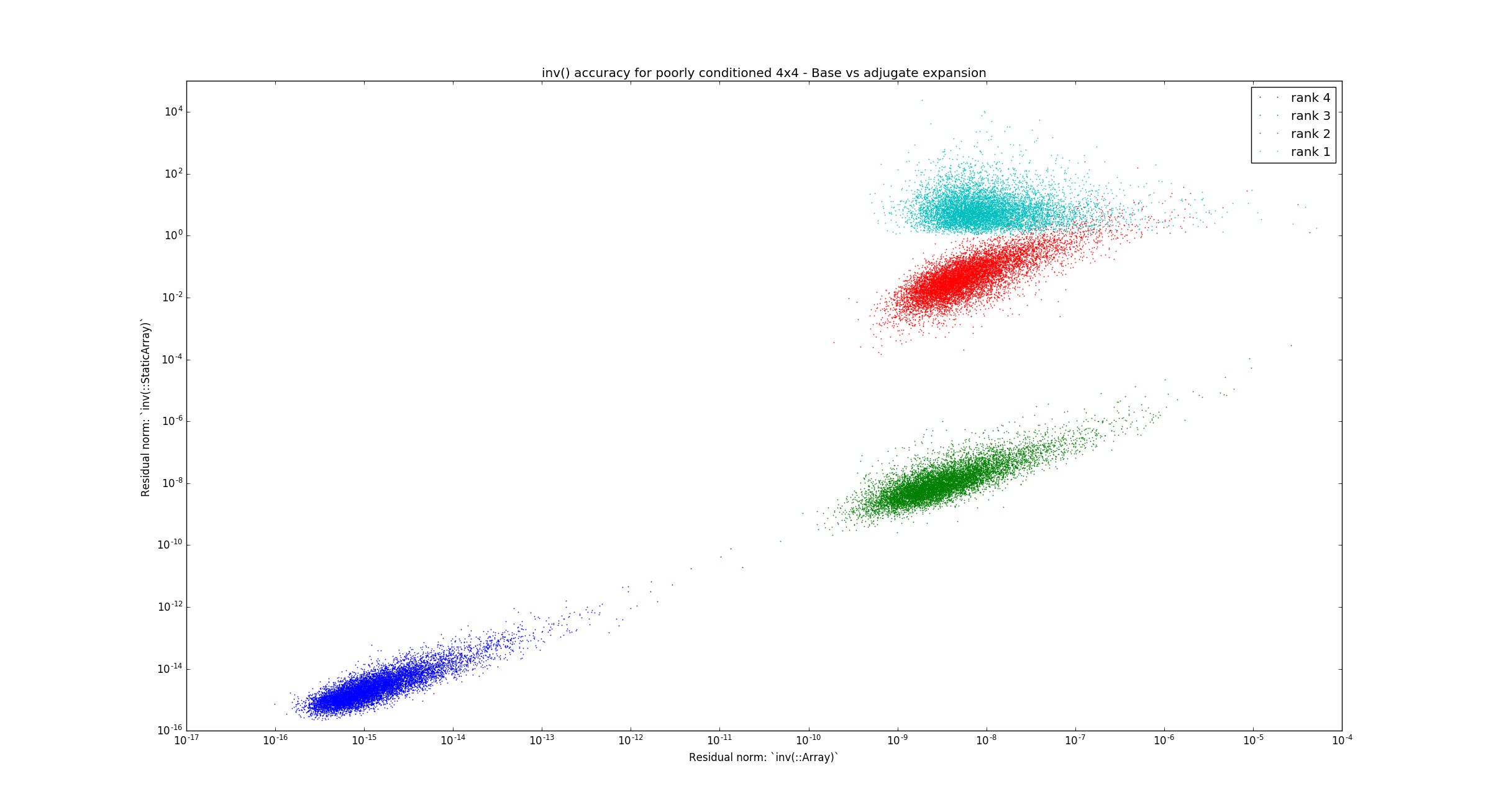
|
Oh, we should really add the test case which kicked all this off - the 4x4 permutation matrix from #250. I'll do this now. |
|
Ok, I added that test case. Let's merge this as soon as CI has passed. |
* Turn off struct broadcast by default. * add doc and rename * Add more unalias test. * Also overload `instantiate` and `_axes` This makes sure `Tuple`'s axes static during struct static broadcast. * Update wording --------- Co-authored-by: Pietro Vertechi <[email protected]>
Added inv and det for 4x4 matrix size , as a stopgap until a more compact representation is found.