diff --git a/.github/CODEOWNERS b/.github/CODEOWNERS
index 879f140855..bde99aec1e 100644
--- a/.github/CODEOWNERS
+++ b/.github/CODEOWNERS
@@ -105,6 +105,10 @@
/tensorflow_addons/layers/tests/esn_test.py @pedrolarben
/tensorflow_addons/layers/snake.py @failure-to-thrive
/tensorflow_addons/layers/tests/snake_test.py @failure-to-thrive
+/tensorflow_addons/layers/stochastic_depth.py @mhstadler @windqaq
+/tensorflow_addons/layers/tests/stochastic_depth_test.py @mhstadler @windqaq
+/tensorflow_addons/layers/noisy_dense.py @leonshams
+/tensorflow_addons/layers/tests/noisy_dense_test.py @leonshams
/tensorflow_addons/losses/contrastive.py @windqaq
/tensorflow_addons/losses/tests/contrastive_test.py @windqaq
@@ -146,6 +150,8 @@
/tensorflow_addons/optimizers/tests/conditional_gradient_test.py @pkan2 @lokhande-vishnu
/tensorflow_addons/optimizers/cyclical_learning_rate.py @raphaelmeudec
/tensorflow_addons/optimizers/tests/cyclical_learning_rate_test.py @raphaelmeudec
+/tensorflow_addons/optimizers/discriminative_layer_training.py @hyang0129
+/tensorflow_addons/optimizers/tests/discriminative_layer_training_test.py @hyang0129
/tensorflow_addons/optimizers/lamb.py @junjiek
/tensorflow_addons/optimizers/tests/lamb_test.py @junjiek
/tensorflow_addons/optimizers/lazy_adam.py @ssaishruthi
diff --git a/.github/workflows/ci_test.yml b/.github/workflows/ci_test.yml
index ac43fdd220..eccafdcf8a 100644
--- a/.github/workflows/ci_test.yml
+++ b/.github/workflows/ci_test.yml
@@ -95,3 +95,32 @@ jobs:
- run: pip install pygithub click
- name: Check that the CODEOWNERS is valid
run: python .github/workflows/notify_codeowners.py .github/CODEOWNERS
+ nbfmt:
+ name: Notebook format
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/setup-python@v1
+ - uses: actions/checkout@v2
+ - name: Install tensorflow-docs
+ run: python3 -m pip install -U git+https://github.com/tensorflow/docs
+ - name: Check notebook formatting
+ run: |
+ # Run on all notebooks to prevent upstream change.
+ echo "Check formatting with nbfmt:"
+ python3 -m tensorflow_docs.tools.nbfmt --test \
+ $(find docs/tutorials/ -type f -name *.ipynb)
+ nblint:
+ name: Notebook lint
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/setup-python@v1
+ - uses: actions/checkout@v2
+ - name: Install tensorflow-docs
+ run: python3 -m pip install -U git+https://github.com/tensorflow/docs
+ - name: Lint notebooks
+ run: |
+ # Run on all notebooks to prevent upstream change.
+ echo "Lint check with nblint:"
+ python3 -m tensorflow_docs.tools.nblint \
+ --arg=repo:tensorflow/addons \
+ $(find docs/tutorials/ -type f -name *.ipynb ! -path "docs/tutorials/_template.ipynb")
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 431d5031bb..b6ba2d6bda 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -325,6 +325,24 @@ bazel test -c opt -k \
//tensorflow_addons/...
```
+#### Testing docstrings
+
+We use [DocTest](https://docs.python.org/3/library/doctest.html) to test code snippets
+in Python docstrings. The snippet must be executable Python code.
+To enable testing, prepend the line with `>>>` (three left-angle brackets).
+Available namespace include `np` for numpy, `tf` for TensorFlow, and `tfa` for TensorFlow Addons.
+See [docs_ref](https://www.tensorflow.org/community/contribute/docs_ref) for more details.
+
+To test docstrings locally, run either
+```bash
+bash tools/run_cpu_tests.sh
+```
+on all files, or
+```bash
+pytest -v -n auto --durations=25 --doctest-modules /path/to/pyfile
+```
+on specific files.
+
## About type hints
Ideally, we would like all the functions and classes constructors exposed in
diff --git a/README.md b/README.md
index c483809120..dbbfe85811 100644
--- a/README.md
+++ b/README.md
@@ -81,7 +81,7 @@ what it was tested against.
| TensorFlow Addons | TensorFlow | Python |
|:----------------------- |:---|:---------- |
| tfa-nightly | 2.2, 2.3 | 3.5, 3.6, 3.7, 3.8 |
-| tensorflow-addons-0.11.1 | 2.2, 2.3 |3.5, 3.6, 3.7, 3.8 |
+| tensorflow-addons-0.11.2 | 2.2, 2.3 |3.5, 3.6, 3.7, 3.8 |
| tensorflow-addons-0.10.0 | 2.2 |3.5, 3.6, 3.7, 3.8 |
| tensorflow-addons-0.9.1 | 2.1, 2.2 |3.5, 3.6, 3.7 |
| tensorflow-addons-0.8.3 | 2.1 |3.5, 3.6, 3.7 |
@@ -107,7 +107,7 @@ is compiled differently. A typical example of this would be `conda`-installed Te
| TensorFlow Addons | TensorFlow | Compiler | cuDNN | CUDA |
|:----------------------- |:---- |:---------|:---------|:---------|
| tfa-nightly | 2.3 | GCC 7.3.1 | 7.6 | 10.1 |
-| tensorflow-addons-0.11.1 | 2.3 | GCC 7.3.1 | 7.6 | 10.1 |
+| tensorflow-addons-0.11.2 | 2.3 | GCC 7.3.1 | 7.6 | 10.1 |
| tensorflow-addons-0.10.0 | 2.2 | GCC 7.3.1 | 7.6 | 10.1 |
| tensorflow-addons-0.9.1 | 2.1 | GCC 7.3.1 | 7.6 | 10.1 |
| tensorflow-addons-0.8.3 | 2.1 | GCC 7.3.1 | 7.6 | 10.1 |
diff --git a/docs/README.md b/docs/README.md
index ce58a5056f..9ce374aaff 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -21,22 +21,11 @@ python -m tensorflow_docs.tools.nbfmt {path to notebook file or directory}
-## 2. Generated API docs
-[tensorflow.org/addons/api_docs/python/tfa](https://tensorflow.org/addons/api_docs/python/tfa)
-`build_docs.py` controls executed this docs generation. To test-run it:
-```bash
-# Install dependencies:
-pip install -r tools/install_deps/doc_requirements.txt
-# Build tool:
-bazel build docs:build_docs
-# Generate API doc:
-# Use current branch
-bazel-bin/docs/build_docs --git_branch=$(git rev-parse --abbrev-ref HEAD)
-# or specified explicitly
-bazel-bin/docs/build_docs --git_branch=master --output_dir=/tmp/tfa_api
-```
+
+
+
diff --git a/docs/tutorials/_template.ipynb b/docs/tutorials/_template.ipynb
index 1f80a64979..07994386fd 100644
--- a/docs/tutorials/_template.ipynb
+++ b/docs/tutorials/_template.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Tce3stUlHN0L"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "tuOe1ymfHZPu"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "qFdPvlXBOdUN"
},
"source": [
@@ -47,7 +43,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MfBg1C5NB3X0"
},
"source": [
@@ -62,7 +57,7 @@
"  View source on GitHub\n",
" \n",
"
View source on GitHub\n",
" \n",
" \n",
- "  Download notebook\n",
+ " Download notebook\n",
" Download notebook\n",
+ " Download notebook\n",
" | \n",
""
]
@@ -70,7 +65,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "r6P32iYYV27b"
},
"source": [
@@ -80,7 +74,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "xHxb-dlhMIzW"
},
"source": [
@@ -92,7 +85,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MUXex9ctTuDB"
},
"source": [
@@ -102,7 +94,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "1Eh-iCRVBm0p"
},
"source": [
@@ -112,7 +103,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "rEk-ibQkDNtF"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -122,8 +115,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "IqR2PQG4ZaZ0"
},
"outputs": [],
@@ -135,7 +126,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "UhNtHfuxCGVy"
},
"source": [
@@ -149,7 +139,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "2V22fKegUtF9"
},
"source": [
@@ -169,7 +158,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "QKp40qS-DGEZ"
},
"source": [
@@ -184,8 +172,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "KtylpxOmceaC"
},
"outputs": [],
@@ -200,7 +186,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "pwdM2pl3RSPb"
},
"source": [
@@ -211,8 +196,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "mMOeXVmbdilM"
},
"outputs": [],
@@ -230,7 +213,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "uabQmjMtRtzs"
},
"source": [
@@ -241,8 +223,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "U82B_tH2d294"
},
"outputs": [],
@@ -254,7 +234,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "TJdqBNBbS78n"
},
"source": [
@@ -271,7 +250,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "78HBT9cQXJko"
},
"source": [
@@ -286,7 +264,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "YrsKXcPRUvK9"
},
"source": [
@@ -307,8 +284,6 @@
"Tce3stUlHN0L"
],
"name": "_template.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/average_optimizers_callback.ipynb b/docs/tutorials/average_optimizers_callback.ipynb
index 7e1c53c642..77e6fee31d 100644
--- a/docs/tutorials/average_optimizers_callback.ipynb
+++ b/docs/tutorials/average_optimizers_callback.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Tce3stUlHN0L"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "tuOe1ymfHZPu"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MfBg1C5NB3X0"
},
"source": [
@@ -62,7 +58,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "xHxb-dlhMIzW"
},
"source": [
@@ -74,7 +69,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "o2UNySlpXkbl"
},
"source": [
@@ -88,7 +82,7 @@
"\n",
"## Model Average Checkpoint \n",
"\n",
- "> `callbacks.ModelCheckpoint` doesn't give you the option to save moving average weights in the middle of traning, which is why Model Average Optimizers required a custom callback. Using the ```update_weights``` parameter, ```ModelAverageCheckpoint``` allows you to:\n",
+ "> `callbacks.ModelCheckpoint` doesn't give you the option to save moving average weights in the middle of training, which is why Model Average Optimizers required a custom callback. Using the ```update_weights``` parameter, ```ModelAverageCheckpoint``` allows you to:\n",
"1. Assign the moving average weights to the model, and save them.\n",
"2. Keep the old non-averaged weights, but the saved model uses the average weights."
]
@@ -96,7 +90,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MUXex9ctTuDB"
},
"source": [
@@ -107,7 +100,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "scrolled": true
+ "id": "sXEOqj5cIgyW"
},
"outputs": [],
"source": [
@@ -118,13 +111,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 35
- },
- "colab_type": "code",
- "id": "IqR2PQG4ZaZ0",
- "outputId": "49c5f5be-4b1a-4298-e218-5c6c0126b4ff"
+ "id": "IqR2PQG4ZaZ0"
},
"outputs": [],
"source": [
@@ -136,8 +123,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "4hnJ2rDpI38-"
},
"outputs": [],
@@ -149,7 +134,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Iox_HZNNYLEB"
},
"source": [
@@ -160,8 +144,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "KtylpxOmceaC"
},
"outputs": [],
@@ -184,7 +166,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "pwdM2pl3RSPb"
},
"source": [
@@ -195,8 +176,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "mMOeXVmbdilM"
},
"outputs": [],
@@ -217,7 +196,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "iEbhI_eajpJe"
},
"source": [
@@ -234,8 +212,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "_Q76K1fNk7Va"
},
"outputs": [],
@@ -249,7 +225,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "nXlMX4p9qHwg"
},
"source": [
@@ -260,8 +235,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "SnvZjt34qEHY"
},
"outputs": [],
@@ -280,7 +253,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "uabQmjMtRtzs"
},
"source": [
@@ -290,7 +262,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "SPmifETHmPix"
},
"source": [
@@ -301,13 +272,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 421
- },
- "colab_type": "code",
- "id": "Xy8W4LYppadJ",
- "outputId": "97bfbf95-d9e7-4c69-99e2-d233e8f54d5a"
+ "id": "Xy8W4LYppadJ"
},
"outputs": [],
"source": [
@@ -322,13 +287,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 72
- },
- "colab_type": "code",
- "id": "uU2iQ6HAZ6-E",
- "outputId": "ec4ae0ad-dd99-4966-d448-270fae1fd0d3"
+ "id": "uU2iQ6HAZ6-E"
},
"outputs": [],
"source": [
@@ -342,7 +301,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "lAvhD4unmc6W"
},
"source": [
@@ -353,13 +311,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 404
- },
- "colab_type": "code",
- "id": "--NIjBp-mhVb",
- "outputId": "51510f00-c0cc-4443-cef3-0b1c263e1600"
+ "id": "--NIjBp-mhVb"
},
"outputs": [],
"source": [
@@ -374,13 +326,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 72
- },
- "colab_type": "code",
- "id": "zRAym9EBmnW9",
- "outputId": "ac7dc6d6-c5c6-456f-af8e-a11a211ef357"
+ "id": "zRAym9EBmnW9"
},
"outputs": [],
"source": [
@@ -394,7 +340,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "K98lbU07m_Bk"
},
"source": [
@@ -405,13 +350,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 329
- },
- "colab_type": "code",
- "id": "Ia7ALKefnXWQ",
- "outputId": "ecf67a66-baf3-43df-ff9c-da14bc6148fa"
+ "id": "Ia7ALKefnXWQ"
},
"outputs": [],
"source": [
@@ -426,13 +365,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 72
- },
- "colab_type": "code",
- "id": "EOT2E9NBoeHI",
- "outputId": "4117451c-1886-4980-b40e-68591912559e"
+ "id": "EOT2E9NBoeHI"
},
"outputs": [],
"source": [
@@ -450,13 +383,10 @@
"Tce3stUlHN0L"
],
"name": "average_optimizers_callback.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
- "language": "python",
"name": "python3"
}
},
diff --git a/docs/tutorials/image_ops.ipynb b/docs/tutorials/image_ops.ipynb
index ccbada7ec0..d43a5bccf9 100644
--- a/docs/tutorials/image_ops.ipynb
+++ b/docs/tutorials/image_ops.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "GWEKvPCCxJke"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "l-m8KQ-nxK5l"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "O8FuVCLYxi_l"
},
"source": [
@@ -62,14 +58,13 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "2a5ksOt-xsOl"
},
"source": [
"## Overview\n",
"This notebook will demonstrate how to use the some image operations in TensorFlow Addons.\n",
"\n",
- "Here is the list of image operations we'll be covering in this example:\n",
+ "Here is the list of image operations you'll be covering in this example:\n",
"\n",
"- `tfa.image.mean_filter2d`\n",
"\n",
@@ -89,7 +84,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "DMbjxr4PyMPF"
},
"source": [
@@ -99,7 +93,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "o_QTX_vHGbj7"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -109,13 +105,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 34
- },
- "colab_type": "code",
- "id": "5hVIKCrhWh4a",
- "outputId": "365ae823-365c-4141-9d84-e4ccfb0c85c7"
+ "id": "5hVIKCrhWh4a"
},
"outputs": [],
"source": [
@@ -128,7 +118,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Q6Z2rsP8yp2v"
},
"source": [
@@ -138,7 +127,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "9gbgJP10z9WO"
},
"source": [
@@ -149,13 +137,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 52
- },
- "colab_type": "code",
- "id": "IgUsVhBQ6dSg",
- "outputId": "20ecbebf-6ed9-4e59-f958-c94b2921ba74"
+ "id": "IgUsVhBQ6dSg"
},
"outputs": [],
"source": [
@@ -165,7 +147,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "uheQOL-y0Fj3"
},
"source": [
@@ -175,7 +156,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MFGirRRZ0Y9k"
},
"source": [
@@ -186,13 +166,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 281
- },
- "colab_type": "code",
- "id": "NRlvNQdm1YI8",
- "outputId": "1922ef25-a9f8-4fb4-8f60-65402a6fd969"
+ "id": "NRlvNQdm1YI8"
},
"outputs": [],
"source": [
@@ -208,7 +182,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "clXQrFVa2nN7"
},
"source": [
@@ -219,13 +192,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 281
- },
- "colab_type": "code",
- "id": "tbaIkUCS2eNv",
- "outputId": "7e2796dd-26d9-4856-fa6e-7b5a084583c5"
+ "id": "tbaIkUCS2eNv"
},
"outputs": [],
"source": [
@@ -238,7 +205,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "UwqfpOm--vV2"
},
"source": [
@@ -248,7 +214,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "jIa5HnomPds3"
},
"source": [
@@ -260,13 +225,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 269
- },
- "colab_type": "code",
- "id": "SutWnbRoHl6i",
- "outputId": "52333d9d-788d-4c46-df94-f24456abb67f"
+ "id": "SutWnbRoHl6i"
},
"outputs": [],
"source": [
@@ -277,7 +236,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Mp6cU7I0-r2h"
},
"source": [
@@ -289,13 +247,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 269
- },
- "colab_type": "code",
- "id": "9kxUES9sM8Jl",
- "outputId": "1340b774-5fbd-4c94-ae26-a35fa3c50546"
+ "id": "9kxUES9sM8Jl"
},
"outputs": [],
"source": [
@@ -306,7 +258,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "WjMdSDKlBcPh"
},
"source": [
@@ -318,13 +269,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 269
- },
- "colab_type": "code",
- "id": "HTh1Qpps8Rg5",
- "outputId": "00dd3893-ffbe-4bdd-de3c-9f037651b36b"
+ "id": "HTh1Qpps8Rg5"
},
"outputs": [],
"source": [
@@ -335,7 +280,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "O79BrK-bC8oh"
},
"source": [
@@ -347,13 +291,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 269
- },
- "colab_type": "code",
- "id": "zZBI-9XvBSuh",
- "outputId": "452460e3-13ee-4eb7-ef4e-dd8a86c897eb"
+ "id": "zZBI-9XvBSuh"
},
"outputs": [],
"source": [
@@ -369,7 +307,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "ruyvVnmCDBgj"
},
"source": [
@@ -381,13 +318,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 269
- },
- "colab_type": "code",
- "id": "vbCdwGtYChnQ",
- "outputId": "430b5cf5-8a0a-497b-fa77-af6792bd5bf7"
+ "id": "vbCdwGtYChnQ"
},
"outputs": [],
"source": [
@@ -401,7 +332,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "fdbCDYJkG8Gv"
},
"source": [
@@ -413,13 +343,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 269
- },
- "colab_type": "code",
- "id": "dG557eQDDtSK",
- "outputId": "641b79fd-e23a-4bb5-d162-eb670b2b88d0"
+ "id": "dG557eQDDtSK"
},
"outputs": [],
"source": [
@@ -435,7 +359,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "FcLMnSKYPcjA"
},
"source": [
@@ -448,13 +371,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 269
- },
- "colab_type": "code",
- "id": "-OMh6oeRQaYQ",
- "outputId": "4f7e9aca-ed78-4e4d-8c06-6833ec899797"
+ "id": "-OMh6oeRQaYQ"
},
"outputs": [],
"source": [
@@ -472,8 +389,6 @@
"colab": {
"collapsed_sections": [],
"name": "image_ops.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/layers_normalizations.ipynb b/docs/tutorials/layers_normalizations.ipynb
index 10d6b29c28..2a770fce4e 100644
--- a/docs/tutorials/layers_normalizations.ipynb
+++ b/docs/tutorials/layers_normalizations.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "wFPyjGqMQ82Q"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "aNZ7aEDyQIYU"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "uMOmzhPEQh7b"
},
"source": [
@@ -62,7 +58,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "cthm5dovQMJl"
},
"source": [
@@ -105,7 +100,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "I2XlcXf5WBHb"
},
"source": [
@@ -115,7 +109,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "kTlbneoEUKrD"
},
"source": [
@@ -125,7 +118,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "_ZQGY_ALnirQ"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -135,8 +130,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "7aGgPZG_WBHg"
},
"outputs": [],
@@ -148,7 +141,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "u82Gz_gOUPDZ"
},
"source": [
@@ -159,8 +151,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "3wso9oidUZZQ"
},
"outputs": [],
@@ -174,7 +164,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "UTQH56j89POZ"
},
"source": [
@@ -193,8 +182,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "aIGjLwYWAm0v"
},
"outputs": [],
@@ -220,7 +207,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "QMwUfJUib3ka"
},
"source": [
@@ -238,8 +224,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "6sLVv-C8f6Kf"
},
"outputs": [],
@@ -269,7 +253,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "qYdnEocRUCll"
},
"source": [
@@ -288,8 +271,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "Fh-Pp_e5UB54"
},
"outputs": [],
@@ -315,7 +296,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "shvGfnB0WpQQ"
},
"source": [
@@ -334,8 +314,6 @@
"colab": {
"collapsed_sections": [],
"name": "layers_normalizations.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/layers_weightnormalization.ipynb b/docs/tutorials/layers_weightnormalization.ipynb
index 0de107e390..f1884cf8e7 100644
--- a/docs/tutorials/layers_weightnormalization.ipynb
+++ b/docs/tutorials/layers_weightnormalization.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Tce3stUlHN0L"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "tuOe1ymfHZPu"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MfBg1C5NB3X0"
},
"source": [
@@ -62,7 +58,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "xHxb-dlhMIzW"
},
"source": [
@@ -74,7 +69,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "KR01t9v_fxbT"
},
"source": [
@@ -84,7 +78,7 @@
"\n",
"Tim Salimans, Diederik P. Kingma (2016)\n",
"\n",
- "> By reparameterizing the weights in this way we improve the conditioning of the optimization problem and we speed up convergence of stochastic gradient descent. Our reparameterization is inspired by batch normalization but does not introduce any dependencies between the examples in a minibatch. This means that our method can also be applied successfully to recurrent models such as LSTMs and to noise-sensitive applications such as deep reinforcement learning or generative models, for which batch normalization is less well suited. Although our method is much simpler, it still provides much of the speed-up of full batch normalization. In addition, the computational overhead of our method is lower, permitting more optimization steps to be taken in the same amount of time.\n",
+ "> By reparameterizing the weights in this way you improve the conditioning of the optimization problem and speed up convergence of stochastic gradient descent. Our reparameterization is inspired by batch normalization but does not introduce any dependencies between the examples in a minibatch. This means that our method can also be applied successfully to recurrent models such as LSTMs and to noise-sensitive applications such as deep reinforcement learning or generative models, for which batch normalization is less well suited. Although our method is much simpler, it still provides much of the speed-up of full batch normalization. In addition, the computational overhead of our method is lower, permitting more optimization steps to be taken in the same amount of time.\n",
"\n",
"> https://arxiv.org/abs/1602.07868 \n",
"\n",
@@ -94,7 +88,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MUXex9ctTuDB"
},
"source": [
@@ -104,7 +97,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "CyWHXw9mQ6mp"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -114,8 +109,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "OywLbs7EXiE_"
},
"outputs": [],
@@ -128,8 +121,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "KQMhhq1qXiFF"
},
"outputs": [],
@@ -142,8 +133,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "ULWHqMAnTVZD"
},
"outputs": [],
@@ -157,7 +146,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "fhM0ieDpSnKh"
},
"source": [
@@ -168,8 +156,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "7XZXnBYgRPSk"
},
"outputs": [],
@@ -191,8 +177,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "UZd6V90eR4Gm"
},
"outputs": [],
@@ -213,7 +197,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "AA5dti8AS2Y7"
},
"source": [
@@ -224,8 +207,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "L8Isjc7W8MEn"
},
"outputs": [],
@@ -245,7 +226,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "cH1CG9E7S34C"
},
"source": [
@@ -256,8 +236,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "EvNKxfaI7vSm"
},
"outputs": [],
@@ -277,8 +255,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "esmMh-5g7wmp"
},
"outputs": [],
@@ -298,8 +274,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "yujf2YRbwX55"
},
"outputs": [],
@@ -325,8 +299,6 @@
"colab": {
"collapsed_sections": [],
"name": "layers_weightnormalization.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/losses_triplet.ipynb b/docs/tutorials/losses_triplet.ipynb
index 857d17353c..fd29dfc898 100644
--- a/docs/tutorials/losses_triplet.ipynb
+++ b/docs/tutorials/losses_triplet.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Tce3stUlHN0L"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "tuOe1ymfHZPu"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MfBg1C5NB3X0"
},
"source": [
@@ -62,7 +58,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "xHxb-dlhMIzW"
},
"source": [
@@ -77,7 +72,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "bQwBbFVAyHJ_"
},
"source": [
@@ -90,24 +84,22 @@
"\n",
"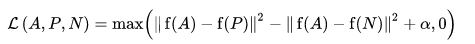\n",
"\n",
- "Where A is our anchor input, P is the positive sample input, N is the negative sample input, and alpha is some margin we use to specify when a triplet has become too \"easy\" and we no longer want to adjust the weights from it."
+ "Where A is our anchor input, P is the positive sample input, N is the negative sample input, and alpha is some margin you use to specify when a triplet has become too \"easy\" and you no longer want to adjust the weights from it."
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "wPJ5521HZHeL"
},
"source": [
"## SemiHard Online Learning\n",
- "As shown in the paper, the best results are from triplets known as \"Semi-Hard\". These are defined as triplets where the negative is farther from the anchor than the positive, but still produces a positive loss. To efficiently find these triplets we utilize online learning and only train from the Semi-Hard examples in each batch. \n"
+ "As shown in the paper, the best results are from triplets known as \"Semi-Hard\". These are defined as triplets where the negative is farther from the anchor than the positive, but still produces a positive loss. To efficiently find these triplets you utilize online learning and only train from the Semi-Hard examples in each batch. \n"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MUXex9ctTuDB"
},
"source": [
@@ -117,7 +109,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "6Vyo25M2ba1P"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -127,8 +121,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "IqR2PQG4ZaZ0"
},
"outputs": [],
@@ -141,8 +133,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "WH_7-ZYZYblV"
},
"outputs": [],
@@ -155,7 +145,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "0_D7CZqkv_Hj"
},
"source": [
@@ -166,8 +155,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "iXvByj6wcT7d"
},
"outputs": [],
@@ -189,7 +176,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "KR01t9v_fxbT"
},
"source": [
@@ -199,7 +185,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "wvOPPuIKhLJi"
},
"source": [
@@ -210,8 +195,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "djpoAvfWNyL5"
},
"outputs": [],
@@ -233,7 +216,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "HYE-BxhOzFQp"
},
"source": [
@@ -244,8 +226,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "NxfYhtiSzHf-"
},
"outputs": [],
@@ -260,8 +240,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "TGBYNGxgVDrj"
},
"outputs": [],
@@ -276,8 +254,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "1Y--0tK69SXf"
},
"outputs": [],
@@ -290,8 +266,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "dqSuLdVZGNrZ"
},
"outputs": [],
@@ -316,7 +290,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "VAtj_m6Z_Uwe"
},
"source": [
@@ -326,7 +299,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Y4rjlG9rlbVA"
},
"source": [
@@ -342,8 +314,6 @@
"colab": {
"collapsed_sections": [],
"name": "losses_triplet.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/networks_seq2seq_nmt.ipynb b/docs/tutorials/networks_seq2seq_nmt.ipynb
index f935b6d11d..8fe62ab8d0 100644
--- a/docs/tutorials/networks_seq2seq_nmt.ipynb
+++ b/docs/tutorials/networks_seq2seq_nmt.ipynb
@@ -1,14 +1,10 @@
{
"cells": [
{
- "cell_type": "code",
- "execution_count": null,
+ "cell_type": "markdown",
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "f9ySOjrcc0Yp"
+ "id": "5aElYAKlV2Mi"
},
- "outputs": [],
"source": [
"##### Copyright 2020 The TensorFlow Authors."
]
@@ -18,9 +14,7 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
- "id": "bl9GdT7h0Hxk"
+ "id": "wmYJlt6LWVOU"
},
"outputs": [],
"source": [
@@ -40,8 +34,7 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "WhwgQAn50EZp"
+ "id": "L-8q8rRRWcp6"
},
"source": [
"# TensorFlow Addons Networks : Sequence-to-Sequence NMT with Attention Mechanism\n",
@@ -65,749 +58,1033 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "ip0n8178Fuwm"
+ "id": "9n0dcDw1Wszw"
},
"source": [
"## Overview\n",
"This notebook gives a brief introduction into the ***Sequence to Sequence Model Architecture***\n",
- "In this noteboook we broadly cover four essential topics necessary for Neural Machine Translation:\n",
+ "In this noteboook you broadly cover four essential topics necessary for Neural Machine Translation:\n",
"\n",
"\n",
"* **Data cleaning**\n",
"* **Data preparation**\n",
"* **Neural Translation Model with Attention**\n",
- "* **Final Translation**\n",
+ "* **Final Translation with ```tf.addons.seq2seq.BasicDecoder``` and ```tf.addons.seq2seq.BeamSearchDecoder```** \n",
"\n",
- "The basic idea behind such a model though, is only the encoder-decoder architecture. These networks are usually used for a variety of tasks like text-summerization, Machine translation, Image Captioning, etc. This tutorial provideas a hands-on understanding of the concept, explaining the technical jargons wherever necessary. We focus on the task of Neural Machine Translation (NMT) which was the very first testbed for seq2seq models.\n"
+ "The basic idea behind such a model though, is only the encoder-decoder architecture. These networks are usually used for a variety of tasks like text-summerization, Machine translation, Image Captioning, etc. This tutorial provideas a hands-on understanding of the concept, explaining the technical jargons wherever necessary. You focus on the task of Neural Machine Translation (NMT) which was the very first testbed for seq2seq models.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "YNiadLKNLleD"
+ "id": "MpySVYWJhxaV"
},
"source": [
"## Setup"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "_kxfdP4hJUPB"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Collecting tensorflow-addons==0.11.2\n",
+ "\u001b[?25l Downloading https://files.pythonhosted.org/packages/b3/f8/d6fca180c123f2851035c4493690662ebdad0849a9059d56035434bff5c9/tensorflow_addons-0.11.2-cp36-cp36m-manylinux2010_x86_64.whl (1.1MB)\n",
+ "\u001b[K |████████████████████████████████| 1.1MB 4.4MB/s \n",
+ "\u001b[?25hRequirement already satisfied: typeguard>=2.7 in /usr/local/lib/python3.6/dist-packages (from tensorflow-addons==0.11.2) (2.7.1)\n",
+ "Installing collected packages: tensorflow-addons\n",
+ " Found existing installation: tensorflow-addons 0.11.0\n",
+ " Uninstalling tensorflow-addons-0.11.0:\n",
+ " Successfully uninstalled tensorflow-addons-0.11.0\n",
+ "Successfully installed tensorflow-addons-0.11.2\n"
+ ]
+ }
+ ],
+ "source": [
+ "!pip install tensorflow-addons==0.11.2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "tnxXKDjq3jEL"
+ },
+ "outputs": [],
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow_addons as tfa\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "import matplotlib.ticker as ticker\n",
+ "from sklearn.model_selection import train_test_split\n",
+ "\n",
+ "import unicodedata\n",
+ "import re\n",
+ "import numpy as np\n",
+ "import os\n",
+ "import io\n",
+ "import time\n"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "82GcQTsGf414"
+ "id": "Ii_vg-XNXTil"
},
"source": [
- "## Additional Resources:\n",
+ "## Data Cleaning and Data Preparation \n",
"\n",
- "These are a lst of resurces you must install in order to allow you to run this notebook:\n",
+ "You'll use a language dataset provided by http://www.manythings.org/anki/. This dataset contains language translation pairs in the format:\n",
"\n",
+ "---\n",
+ " May I borrow this book? ¿Puedo tomar prestado este libro?\n",
+ "---\n",
"\n",
- "1. [German-English Dataset](http://www.manythings.org/anki/deu-eng.zip)\n",
"\n",
+ "There are a variety of languages available, but you'll use the English-Spanish dataset. After downloading the dataset, here are the steps you'll take to prepare the data:\n",
"\n",
- "The dataset should be downloaded, in order to compile this notebook, the embeddings can be used, as they are pretrained. Though, we carry out our own training here.\n"
+ "\n",
+ "1. Add a start and end token to each sentence.\n",
+ "2. Clean the sentences by removing special characters.\n",
+ "3. Create a Vocabulary with word index (mapping from word → id) and reverse word index (mapping from id → word).\n",
+ "5. Pad each sentence to a maximum length. (Why? you need to fix the maximum length for the inputs to recurrent encoders)"
]
},
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "PvRnGWnvXm6l"
+ },
"outputs": [],
"source": [
- "!pip install -U tensorflow-addons\n",
- "!pip install nltk sklearn"
+ "def download_nmt():\n",
+ " path_to_zip = tf.keras.utils.get_file(\n",
+ " 'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',\n",
+ " extract=True)\n",
+ "\n",
+ " path_to_file = os.path.dirname(path_to_zip)+\"/spa-eng/spa.txt\"\n",
+ " return path_to_file\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NFKB2c_tX4wU"
+ },
+ "source": [
+ "### Define a NMTDataset class with necessary functions to follow Step 1 to Step 4. \n",
+ "The ```call()``` will return:\n",
+ "1. ```train_dataset``` and ```val_dataset``` : ```tf.data.Dataset``` objects\n",
+ "2. ```inp_lang_tokenizer``` and ```targ_lang_tokenizer``` : ```tf.keras.preprocessing.text.Tokenizer``` objects "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "5OIlpST_6ga-"
+ "id": "JMAHz7kJXc5N"
},
"outputs": [],
"source": [
- "#download data\n",
- "print(\"Downloading Dataset:\")\n",
- "!wget --quiet http://www.manythings.org/anki/deu-eng.zip\n",
- "!unzip -o deu-eng.zip"
+ "class NMTDataset:\n",
+ " def __init__(self, problem_type='en-spa'):\n",
+ " self.problem_type = 'en-spa'\n",
+ " self.inp_lang_tokenizer = None\n",
+ " self.targ_lang_tokenizer = None\n",
+ " \n",
+ "\n",
+ " def unicode_to_ascii(self, s):\n",
+ " return ''.join(c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn')\n",
+ "\n",
+ " ## Step 1 and Step 2 \n",
+ " def preprocess_sentence(self, w):\n",
+ " w = self.unicode_to_ascii(w.lower().strip())\n",
+ "\n",
+ " # creating a space between a word and the punctuation following it\n",
+ " # eg: \"he is a boy.\" => \"he is a boy .\"\n",
+ " # Reference:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation\n",
+ " w = re.sub(r\"([?.!,¿])\", r\" \\1 \", w)\n",
+ " w = re.sub(r'[\" \"]+', \" \", w)\n",
+ "\n",
+ " # replacing everything with space except (a-z, A-Z, \".\", \"?\", \"!\", \",\")\n",
+ " w = re.sub(r\"[^a-zA-Z?.!,¿]+\", \" \", w)\n",
+ "\n",
+ " w = w.strip()\n",
+ "\n",
+ " # adding a start and an end token to the sentence\n",
+ " # so that the model know when to start and stop predicting.\n",
+ " w = ' ' + w + ' '\n",
+ " return w\n",
+ " \n",
+ " def create_dataset(self, path, num_examples):\n",
+ " # path : path to spa-eng.txt file\n",
+ " # num_examples : Limit the total number of training example for faster training (set num_examples = len(lines) to use full data)\n",
+ " lines = io.open(path, encoding='UTF-8').read().strip().split('\\n')\n",
+ " word_pairs = [[self.preprocess_sentence(w) for w in l.split('\\t')] for l in lines[:num_examples]]\n",
+ "\n",
+ " return zip(*word_pairs)\n",
+ "\n",
+ " # Step 3 and Step 4\n",
+ " def tokenize(self, lang):\n",
+ " # lang = list of sentences in a language\n",
+ " \n",
+ " # print(len(lang), \"example sentence: {}\".format(lang[0]))\n",
+ " lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='', oov_token='')\n",
+ " lang_tokenizer.fit_on_texts(lang)\n",
+ "\n",
+ " ## tf.keras.preprocessing.text.Tokenizer.texts_to_sequences converts string (w1, w2, w3, ......, wn) \n",
+ " ## to a list of correspoding integer ids of words (id_w1, id_w2, id_w3, ...., id_wn)\n",
+ " tensor = lang_tokenizer.texts_to_sequences(lang) \n",
+ "\n",
+ " ## tf.keras.preprocessing.sequence.pad_sequences takes argument a list of integer id sequences \n",
+ " ## and pads the sequences to match the longest sequences in the given input\n",
+ " tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, padding='post')\n",
+ "\n",
+ " return tensor, lang_tokenizer\n",
+ "\n",
+ " def load_dataset(self, path, num_examples=None):\n",
+ " # creating cleaned input, output pairs\n",
+ " targ_lang, inp_lang = self.create_dataset(path, num_examples)\n",
+ "\n",
+ " input_tensor, inp_lang_tokenizer = self.tokenize(inp_lang)\n",
+ " target_tensor, targ_lang_tokenizer = self.tokenize(targ_lang)\n",
+ "\n",
+ " return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer\n",
+ "\n",
+ " def call(self, num_examples, BUFFER_SIZE, BATCH_SIZE):\n",
+ " file_path = download_nmt()\n",
+ " input_tensor, target_tensor, self.inp_lang_tokenizer, self.targ_lang_tokenizer = self.load_dataset(file_path, num_examples)\n",
+ " \n",
+ " input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)\n",
+ "\n",
+ " train_dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train))\n",
+ " train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)\n",
+ "\n",
+ " val_dataset = tf.data.Dataset.from_tensor_slices((input_tensor_val, target_tensor_val))\n",
+ " val_dataset = val_dataset.batch(BATCH_SIZE, drop_remainder=True)\n",
+ "\n",
+ " return train_dataset, val_dataset, self.inp_lang_tokenizer, self.targ_lang_tokenizer"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 34
- },
- "colab_type": "code",
- "id": "co6-YpBwL-4d",
- "outputId": "6571961c-8f50-4333-9b1d-5eb1a157f4f8"
+ "id": "EIW4NVBmJ25k"
},
"outputs": [],
"source": [
- "import csv\n",
- "import string\n",
- "import re\n",
- "from typing import List, Tuple\n",
- "from pickle import dump\n",
- "from unicodedata import normalize\n",
- "import numpy as np\n",
- "import itertools\n",
- "from pickle import load\n",
- "from tensorflow.keras.utils import to_categorical\n",
- "from tensorflow.keras.utils import plot_model\n",
- "from tensorflow.keras.models import Sequential\n",
- "from tensorflow.keras.layers import LSTM\n",
- "from tensorflow.keras.layers import Dense\n",
- "from tensorflow.keras.layers import Embedding\n",
- "from pickle import load\n",
- "import random\n",
- "import tensorflow as tf\n",
- "from tensorflow.keras.models import load_model\n",
- "from nltk.translate.bleu_score import corpus_bleu\n",
- "from sklearn.model_selection import train_test_split\n",
- "import tensorflow_addons as tfa"
+ "BUFFER_SIZE = 32000\n",
+ "BATCH_SIZE = 64\n",
+ "# Let's limit the #training examples for faster training\n",
+ "num_examples = 30000\n",
+ "\n",
+ "dataset_creator = NMTDataset('en-spa')\n",
+ "train_dataset, val_dataset, inp_lang, targ_lang = dataset_creator.call(num_examples, BUFFER_SIZE, BATCH_SIZE)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "w2lCTy4vKOkB"
+ },
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(TensorShape([64, 16]), TensorShape([64, 11]))"
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {
+ "tags": []
+ },
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "example_input_batch, example_target_batch = next(iter(train_dataset))\n",
+ "example_input_batch.shape, example_target_batch.shape"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "q7gjUT_9XSoj"
+ "id": "rgCLkfv5uO3d"
},
"source": [
- "## Data Cleaning\n",
- "\n",
- "Our data set is a German-English translation dataset. It contains 152,820 pairs of English to German phases, one pair per line with a tab separating the language. These dataset though organized needs cleaning before we can work on it. This will enable us to remove unnecessary bumps that may come in during the training. We also added start-of-sentence `` and end-of-sentence `` so that the model knows when to start and stop predicting."
+ "### Some important parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "6ZIu-TNqKFsd"
+ "id": "TqHsArVZ3jFS"
},
"outputs": [],
"source": [
- "# Start of sentence\n",
- "SOS = \"\"\n",
- "# End of sentence\n",
- "EOS = \"\"\n",
- "# Relevant punctuation\n",
- "PUNCTUATION = set(\"?,!.\")\n",
- "\n",
- "\n",
- "def load_dataset(filename: str) -> str:\n",
- " \"\"\"\n",
- " load dataset into memory\n",
- " \"\"\"\n",
- " with open(filename, mode=\"rt\", encoding=\"utf-8\") as fp:\n",
- " return fp.read()\n",
- "\n",
- "\n",
- "def to_pairs(dataset: str, limit: int = None, shuffle=False) -> List[Tuple[str, str]]:\n",
- " \"\"\"\n",
- " Split dataset into pairs of sentences, discards dataset line info.\n",
- "\n",
- " e.g.\n",
- " input -> 'Go.\\tGeh.\\tCC-BY 2.0 (France) Attribution: tatoeba.org\n",
- " #2877272 (CM) & #8597805 (Roujin)'\n",
- " output -> [('Go.', 'Geh.')]\n",
- "\n",
- " :param dataset: dataset containing examples of translations between\n",
- " two languages\n",
- " the examples are delimited by `\\n` and the contents of the lines are\n",
- " delimited by `\\t`\n",
- " :param limit: number that limit dataset size (optional)\n",
- " :param shuffle: default is True\n",
- " :return: list of pairs\n",
- " \"\"\"\n",
- " assert isinstance(limit, (int, type(None))), TypeError(\n",
- " \"the limit value must be an integer\"\n",
- " )\n",
- " lines = dataset.strip().split(\"\\n\")\n",
- " # Radom dataset\n",
- " if shuffle is True:\n",
- " random.shuffle(lines)\n",
- " number_examples = limit or len(lines) # if None get all\n",
- " pairs = []\n",
- " for line in lines[: abs(number_examples)]:\n",
- " # take only source and target\n",
- " src, trg, _ = line.split(\"\\t\")\n",
- " pairs.append((src, trg))\n",
- "\n",
- " # dataset size check\n",
- " assert len(pairs) == number_examples\n",
- " return pairs\n",
- "\n",
- "\n",
- "def separe_punctuation(token: str) -> str:\n",
- " \"\"\"\n",
- " Separe punctuation if exists\n",
- " \"\"\"\n",
- "\n",
- " if not set(token).intersection(PUNCTUATION):\n",
- " return token\n",
- " for p in PUNCTUATION:\n",
- " token = f\" {p} \".join(token.split(p))\n",
- " return \" \".join(token.split())\n",
- "\n",
- "\n",
- "def preprocess(sentence: str, add_start_end: bool=True) -> str:\n",
- " \"\"\"\n",
- " - convert lowercase\n",
- " - remove numbers\n",
- " - remove special characters\n",
- " - separe punctuation\n",
- " - add start-of-sentence and end-of-sentence \n",
- "\n",
- " :param add_start_end: add SOS (start-of-sentence) and EOS (end-of-sentence)\n",
- " \"\"\"\n",
- " re_print = re.compile(f\"[^{re.escape(string.printable)}]\")\n",
- " # convert lowercase and normalizing unicode characters\n",
- " sentence = (\n",
- " normalize(\"NFD\", sentence.lower()).encode(\"ascii\", \"ignore\").decode(\"UTF-8\")\n",
- " )\n",
- " cleaned_tokens = []\n",
- " # tokenize sentence on white space\n",
- " for token in sentence.split():\n",
- " # removing non-printable chars form each token\n",
- " token = re_print.sub(\"\", token).strip()\n",
- " # ignore tokens with numbers\n",
- " if re.findall(\"[0-9]\", token):\n",
- " continue\n",
- " # add space between words and punctuation eg: \"ok?go!\" => \"ok ? go !\"\n",
- " token = separe_punctuation(token)\n",
- " cleaned_tokens.append(token)\n",
- "\n",
- " # rebuild sentence with space between tokens\n",
- " sentence = \" \".join(cleaned_tokens)\n",
- "\n",
- " # adding a start and an end token to the sentence\n",
- " if add_start_end is True:\n",
- " sentence = f\"{SOS} {sentence} {EOS}\"\n",
- " return sentence\n",
- "\n",
- "\n",
- "def dataset_preprocess(dataset: List[Tuple[str, str]]) -> Tuple[List[str], List[str]]:\n",
- " \"\"\"\n",
- " Returns processed database\n",
- "\n",
- " :param dataset: list of sentence pairs\n",
- " :return: list of paralel data e.g. \n",
- " (['first source sentence', 'second', ...], ['first target sentence', 'second', ...])\n",
- " \"\"\"\n",
- " source_cleaned = []\n",
- " target_cleaned = []\n",
- " for source, target in dataset:\n",
- " source_cleaned.append(preprocess(source))\n",
- " target_cleaned.append(preprocess(target))\n",
- " return source_cleaned, target_cleaned\n"
+ "vocab_inp_size = len(inp_lang.word_index)+1\n",
+ "vocab_tar_size = len(targ_lang.word_index)+1\n",
+ "max_length_input = example_input_batch.shape[1]\n",
+ "max_length_output = example_target_batch.shape[1]\n",
+ "\n",
+ "embedding_dim = 256\n",
+ "units = 1024\n",
+ "steps_per_epoch = num_examples//BATCH_SIZE\n"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "colab_type": "text",
- "id": "5nDIELt9RH-w"
+ "id": "g-yY9c6aIu1h"
},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "max_length_spanish, max_length_english, vocab_size_spanish, vocab_size_english\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "(16, 11, 9415, 4936)"
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {
+ "tags": []
+ },
+ "output_type": "execute_result"
+ }
+ ],
"source": [
- "## Create Dataset\n",
- "\n",
- "- limit number of examples\n",
- "- load dataset into pairs `[('Be nice.', 'Seien Sie nett!'), ('Beat it.', 'Geh weg!'), ...]`\n",
- "- preprocessing dataset"
+ "print(\"max_length_spanish, max_length_english, vocab_size_spanish, vocab_size_english\")\n",
+ "max_length_input, max_length_output, vocab_inp_size, vocab_tar_size"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 119
- },
- "colab_type": "code",
- "id": "GMxdlVU1X8yI",
- "outputId": "f4977f48-dbe9-4323-ec2a-a9b0cf8b1895"
+ "id": "nZ2rI24i3jFg"
},
"outputs": [],
"source": [
- "NUM_EXAMPLES = 10000 # Limit dataset size\n",
+ "##### \n",
+ "\n",
+ "class Encoder(tf.keras.Model):\n",
+ " def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):\n",
+ " super(Encoder, self).__init__()\n",
+ " self.batch_sz = batch_sz\n",
+ " self.enc_units = enc_units\n",
+ " self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)\n",
+ "\n",
+ " ##-------- LSTM layer in Encoder ------- ##\n",
+ " self.lstm_layer = tf.keras.layers.LSTM(self.enc_units,\n",
+ " return_sequences=True,\n",
+ " return_state=True,\n",
+ " recurrent_initializer='glorot_uniform')\n",
+ " \n",
+ "\n",
"\n",
- "# load from .txt\n",
- "filename = 'deu.txt' #change filename if necessary\n",
- "dataset = load_dataset(filename)\n",
- "# get pairs limited into 1000\n",
- "pairs = to_pairs(dataset, limit=NUM_EXAMPLES)\n",
- "print(f\"Dataset size: {len(pairs)}\")\n",
- "raw_data_en, raw_data_ge = dataset_preprocess(pairs)\n",
+ " def call(self, x, hidden):\n",
+ " x = self.embedding(x)\n",
+ " output, h, c = self.lstm_layer(x, initial_state = hidden)\n",
+ " return output, h, c\n",
"\n",
- "# show last 5 pairs\n",
- "for pair in zip(raw_data_en[-5:],raw_data_ge[-5:]):\n",
- " print(pair)"
+ " def initialize_hidden_state(self):\n",
+ " return [tf.zeros((self.batch_sz, self.enc_units)), tf.zeros((self.batch_sz, self.enc_units))] "
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "colab_type": "text",
- "id": "Cfb66QxWYr6A"
+ "id": "60gSVh05Jl6l"
},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Encoder output shape: (batch size, sequence length, units) (64, 16, 1024)\n",
+ "Encoder h vecotr shape: (batch size, units) (64, 1024)\n",
+ "Encoder c vector shape: (batch size, units) (64, 1024)\n"
+ ]
+ }
+ ],
"source": [
- "## Tokenization"
+ "## Test Encoder Stack\n",
+ "\n",
+ "encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)\n",
+ "\n",
+ "\n",
+ "# sample input\n",
+ "sample_hidden = encoder.initialize_hidden_state()\n",
+ "sample_output, sample_h, sample_c = encoder(example_input_batch, sample_hidden)\n",
+ "print ('Encoder output shape: (batch size, sequence length, units) {}'.format(sample_output.shape))\n",
+ "print ('Encoder h vecotr shape: (batch size, units) {}'.format(sample_h.shape))\n",
+ "print ('Encoder c vector shape: (batch size, units) {}'.format(sample_c.shape))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "3oq60MBPSanQ"
+ "id": "yJ_B3mhW3jFk"
},
"outputs": [],
"source": [
- "en_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')\n",
- "en_tokenizer.fit_on_texts(raw_data_en)\n",
+ "class Decoder(tf.keras.Model):\n",
+ " def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz, attention_type='luong'):\n",
+ " super(Decoder, self).__init__()\n",
+ " self.batch_sz = batch_sz\n",
+ " self.dec_units = dec_units\n",
+ " self.attention_type = attention_type\n",
+ " \n",
+ " # Embedding Layer\n",
+ " self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)\n",
+ " \n",
+ " #Final Dense layer on which softmax will be applied\n",
+ " self.fc = tf.keras.layers.Dense(vocab_size)\n",
+ "\n",
+ " # Define the fundamental cell for decoder recurrent structure\n",
+ " self.decoder_rnn_cell = tf.keras.layers.LSTMCell(self.dec_units)\n",
+ " \n",
+ "\n",
+ "\n",
+ " # Sampler\n",
+ " self.sampler = tfa.seq2seq.sampler.TrainingSampler()\n",
+ "\n",
+ " # Create attention mechanism with memory = None\n",
+ " self.attention_mechanism = self.build_attention_mechanism(self.dec_units, \n",
+ " None, self.batch_sz*[max_length_input], self.attention_type)\n",
+ "\n",
+ " # Wrap attention mechanism with the fundamental rnn cell of decoder\n",
+ " self.rnn_cell = self.build_rnn_cell(batch_sz)\n",
+ "\n",
+ " # Define the decoder with respect to fundamental rnn cell\n",
+ " self.decoder = tfa.seq2seq.BasicDecoder(self.rnn_cell, sampler=self.sampler, output_layer=self.fc)\n",
+ "\n",
+ " \n",
+ " def build_rnn_cell(self, batch_sz):\n",
+ " rnn_cell = tfa.seq2seq.AttentionWrapper(self.decoder_rnn_cell, \n",
+ " self.attention_mechanism, attention_layer_size=self.dec_units)\n",
+ " return rnn_cell\n",
+ "\n",
+ " def build_attention_mechanism(self, dec_units, memory, memory_sequence_length, attention_type='luong'):\n",
+ " # ------------- #\n",
+ " # typ: Which sort of attention (Bahdanau, Luong)\n",
+ " # dec_units: final dimension of attention outputs \n",
+ " # memory: encoder hidden states of shape (batch_size, max_length_input, enc_units)\n",
+ " # memory_sequence_length: 1d array of shape (batch_size) with every element set to max_length_input (for masking purpose)\n",
+ "\n",
+ " if(attention_type=='bahdanau'):\n",
+ " return tfa.seq2seq.BahdanauAttention(units=dec_units, memory=memory, memory_sequence_length=memory_sequence_length)\n",
+ " else:\n",
+ " return tfa.seq2seq.LuongAttention(units=dec_units, memory=memory, memory_sequence_length=memory_sequence_length)\n",
+ "\n",
+ " def build_initial_state(self, batch_sz, encoder_state, Dtype):\n",
+ " decoder_initial_state = self.rnn_cell.get_initial_state(batch_size=batch_sz, dtype=Dtype)\n",
+ " decoder_initial_state = decoder_initial_state.clone(cell_state=encoder_state)\n",
+ " return decoder_initial_state\n",
+ "\n",
+ "\n",
+ " def call(self, inputs, initial_state):\n",
+ " x = self.embedding(inputs)\n",
+ " outputs, _, _ = self.decoder(x, initial_state=initial_state, sequence_length=self.batch_sz*[max_length_output-1])\n",
+ " return outputs\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "DaiO0Z6_Ml1c"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Decoder Outputs Shape: (64, 10, 4936)\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Test decoder stack\n",
+ "\n",
+ "decoder = Decoder(vocab_tar_size, embedding_dim, units, BATCH_SIZE, 'luong')\n",
+ "sample_x = tf.random.uniform((BATCH_SIZE, max_length_output))\n",
+ "decoder.attention_mechanism.setup_memory(sample_output)\n",
+ "initial_state = decoder.build_initial_state(BATCH_SIZE, [sample_h, sample_c], tf.float32)\n",
"\n",
- "data_en = en_tokenizer.texts_to_sequences(raw_data_en)\n",
- "data_en = tf.keras.preprocessing.sequence.pad_sequences(data_en,padding='post')\n",
"\n",
- "ge_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')\n",
- "ge_tokenizer.fit_on_texts(raw_data_ge)\n",
+ "sample_decoder_outputs = decoder(sample_x, initial_state)\n",
"\n",
- "data_ge = ge_tokenizer.texts_to_sequences(raw_data_ge)\n",
- "data_ge = tf.keras.preprocessing.sequence.pad_sequences(data_ge,padding='post')"
+ "print(\"Decoder Outputs Shape: \", sample_decoder_outputs.rnn_output.shape)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_ch_71VbIRfK"
+ },
+ "source": [
+ "## Define the optimizer and the loss function"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "XH5oSRNeSc1s"
+ "id": "WmTHr5iV3jFr"
},
"outputs": [],
"source": [
- "def max_len(tensor):\n",
- " #print( np.argmax([len(t) for t in tensor]))\n",
- " return max( len(t) for t in tensor)"
+ "optimizer = tf.keras.optimizers.Adam()\n",
+ "\n",
+ "\n",
+ "def loss_function(real, pred):\n",
+ " # real shape = (BATCH_SIZE, max_length_output)\n",
+ " # pred shape = (BATCH_SIZE, max_length_output, tar_vocab_size )\n",
+ " cross_entropy = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')\n",
+ " loss = cross_entropy(y_true=real, y_pred=pred)\n",
+ " mask = tf.logical_not(tf.math.equal(real,0)) #output 0 for y=0 else output 1\n",
+ " mask = tf.cast(mask, dtype=loss.dtype) \n",
+ " loss = mask* loss\n",
+ " loss = tf.reduce_mean(loss)\n",
+ " return loss "
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "KdM37lNBGXAj"
+ "id": "DMVWzzsfNl4e"
},
"source": [
- "## Model Parameters"
+ "## Checkpoints (Object-based saving)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "EfiBUJM2Et6C"
+ "id": "Zj8bXQTgNwrF"
},
"outputs": [],
"source": [
- "X_train, X_test, Y_train, Y_test = train_test_split(data_en,data_ge,test_size=0.2)\n",
- "BATCH_SIZE = 64\n",
- "BUFFER_SIZE = len(X_train)\n",
- "steps_per_epoch = BUFFER_SIZE//BATCH_SIZE\n",
- "embedding_dims = 256\n",
- "rnn_units = 1024\n",
- "dense_units = 1024\n",
- "Dtype = tf.float32 #used to initialize DecoderCell Zero state"
+ "checkpoint_dir = './training_checkpoints'\n",
+ "checkpoint_prefix = os.path.join(checkpoint_dir, \"ckpt\")\n",
+ "checkpoint = tf.train.Checkpoint(optimizer=optimizer,\n",
+ " encoder=encoder,\n",
+ " decoder=decoder)"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "Ff_jQHLhGqJU"
+ "id": "8Bw95utNiFHa"
},
"source": [
- "## Dataset Prepration"
+ "## One train_step operations"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 51
- },
- "colab_type": "code",
- "id": "b__1hPHVFALO",
- "outputId": "88d35286-184c-44e7-a16b-5559f22e2eb1"
+ "id": "sC9ArXSsVfqn"
},
"outputs": [],
"source": [
- "Tx = max_len(data_en)\n",
- "Ty = max_len(data_ge) \n",
+ "@tf.function\n",
+ "def train_step(inp, targ, enc_hidden):\n",
+ " loss = 0\n",
+ "\n",
+ " with tf.GradientTape() as tape:\n",
+ " enc_output, enc_h, enc_c = encoder(inp, enc_hidden)\n",
+ "\n",
+ "\n",
+ " dec_input = targ[ : , :-1 ] # Ignore token\n",
+ " real = targ[ : , 1: ] # ignore token\n",
"\n",
- "input_vocab_size = len(en_tokenizer.word_index)+1 \n",
- "output_vocab_size = len(ge_tokenizer.word_index)+ 1\n",
- "dataset = tf.data.Dataset.from_tensor_slices((X_train, Y_train)).shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)\n",
- "example_X, example_Y = next(iter(dataset))\n",
- "print(example_X.shape) \n",
- "print(example_Y.shape) "
+ " # Set the AttentionMechanism object with encoder_outputs\n",
+ " decoder.attention_mechanism.setup_memory(enc_output)\n",
+ "\n",
+ " # Create AttentionWrapperState as initial_state for decoder\n",
+ " decoder_initial_state = decoder.build_initial_state(BATCH_SIZE, [enc_h, enc_c], tf.float32)\n",
+ " pred = decoder(dec_input, decoder_initial_state)\n",
+ " logits = pred.rnn_output\n",
+ " loss = loss_function(real, logits)\n",
+ "\n",
+ " variables = encoder.trainable_variables + decoder.trainable_variables\n",
+ " gradients = tape.gradient(loss, variables)\n",
+ " optimizer.apply_gradients(zip(gradients, variables))\n",
+ "\n",
+ " return loss"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "UQRgJcYgapqE"
+ "id": "pey8eb9piMMg"
},
"source": [
- "## Defining NMT Model"
+ "## Train the model"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "sGdakRtjaokF"
+ "id": "ddefjBMa3jF0"
},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Epoch 1 Batch 0 Loss 5.1692\n",
+ "Epoch 1 Batch 100 Loss 2.2288\n",
+ "Epoch 1 Batch 200 Loss 1.9930\n",
+ "Epoch 1 Batch 300 Loss 1.7783\n",
+ "Epoch 1 Loss 1.6975\n",
+ "Time taken for 1 epoch 37.26002788543701 sec\n",
+ "\n",
+ "Epoch 2 Batch 0 Loss 1.6408\n",
+ "Epoch 2 Batch 100 Loss 1.5767\n",
+ "Epoch 2 Batch 200 Loss 1.4054\n",
+ "Epoch 2 Batch 300 Loss 1.3755\n",
+ "Epoch 2 Loss 1.1412\n",
+ "Time taken for 1 epoch 30.0094051361084 sec\n",
+ "\n",
+ "Epoch 3 Batch 0 Loss 1.0296\n",
+ "Epoch 3 Batch 100 Loss 1.0306\n",
+ "Epoch 3 Batch 200 Loss 1.0675\n",
+ "Epoch 3 Batch 300 Loss 0.9574\n",
+ "Epoch 3 Loss 0.8037\n",
+ "Time taken for 1 epoch 28.983767986297607 sec\n",
+ "\n",
+ "Epoch 4 Batch 0 Loss 0.5923\n",
+ "Epoch 4 Batch 100 Loss 0.7533\n",
+ "Epoch 4 Batch 200 Loss 0.7397\n",
+ "Epoch 4 Batch 300 Loss 0.6779\n",
+ "Epoch 4 Loss 0.5419\n",
+ "Time taken for 1 epoch 29.649972200393677 sec\n",
+ "\n",
+ "Epoch 5 Batch 0 Loss 0.4320\n",
+ "Epoch 5 Batch 100 Loss 0.4349\n",
+ "Epoch 5 Batch 200 Loss 0.4686\n",
+ "Epoch 5 Batch 300 Loss 0.4748\n",
+ "Epoch 5 Loss 0.3827\n",
+ "Time taken for 1 epoch 29.06334638595581 sec\n",
+ "\n",
+ "Epoch 6 Batch 0 Loss 0.3422\n",
+ "Epoch 6 Batch 100 Loss 0.3052\n",
+ "Epoch 6 Batch 200 Loss 0.3288\n",
+ "Epoch 6 Batch 300 Loss 0.3216\n",
+ "Epoch 6 Loss 0.2814\n",
+ "Time taken for 1 epoch 29.57170796394348 sec\n",
+ "\n",
+ "Epoch 7 Batch 0 Loss 0.2129\n",
+ "Epoch 7 Batch 100 Loss 0.2382\n",
+ "Epoch 7 Batch 200 Loss 0.2406\n",
+ "Epoch 7 Batch 300 Loss 0.2792\n",
+ "Epoch 7 Loss 0.2162\n",
+ "Time taken for 1 epoch 28.95500087738037 sec\n",
+ "\n",
+ "Epoch 8 Batch 0 Loss 0.2073\n",
+ "Epoch 8 Batch 100 Loss 0.2095\n",
+ "Epoch 8 Batch 200 Loss 0.1962\n",
+ "Epoch 8 Batch 300 Loss 0.1879\n",
+ "Epoch 8 Loss 0.1794\n",
+ "Time taken for 1 epoch 29.70877432823181 sec\n",
+ "\n",
+ "Epoch 9 Batch 0 Loss 0.1517\n",
+ "Epoch 9 Batch 100 Loss 0.2231\n",
+ "Epoch 9 Batch 200 Loss 0.2203\n",
+ "Epoch 9 Batch 300 Loss 0.2282\n",
+ "Epoch 9 Loss 0.1496\n",
+ "Time taken for 1 epoch 29.20821261405945 sec\n",
+ "\n",
+ "Epoch 10 Batch 0 Loss 0.1204\n",
+ "Epoch 10 Batch 100 Loss 0.1370\n",
+ "Epoch 10 Batch 200 Loss 0.1778\n",
+ "Epoch 10 Batch 300 Loss 0.2069\n",
+ "Epoch 10 Loss 0.1316\n",
+ "Time taken for 1 epoch 29.576894283294678 sec\n",
+ "\n"
+ ]
+ }
+ ],
"source": [
- "#ENCODER\n",
- "class EncoderNetwork(tf.keras.Model):\n",
- " def __init__(self,input_vocab_size,embedding_dims, rnn_units ):\n",
- " super().__init__()\n",
- " self.encoder_embedding = tf.keras.layers.Embedding(input_dim=input_vocab_size,\n",
- " output_dim=embedding_dims)\n",
- " self.encoder_rnnlayer = tf.keras.layers.LSTM(rnn_units,return_sequences=True, \n",
- " return_state=True )\n",
- " \n",
- "#DECODER\n",
- "class DecoderNetwork(tf.keras.Model):\n",
- " def __init__(self,output_vocab_size, embedding_dims, rnn_units):\n",
- " super().__init__()\n",
- " self.decoder_embedding = tf.keras.layers.Embedding(input_dim=output_vocab_size,\n",
- " output_dim=embedding_dims) \n",
- " self.dense_layer = tf.keras.layers.Dense(output_vocab_size)\n",
- " self.decoder_rnncell = tf.keras.layers.LSTMCell(rnn_units)\n",
- " # Sampler\n",
- " self.sampler = tfa.seq2seq.sampler.TrainingSampler()\n",
- " # Create attention mechanism with memory = None\n",
- " self.attention_mechanism = self.build_attention_mechanism(dense_units,None,BATCH_SIZE*[Tx])\n",
- " self.rnn_cell = self.build_rnn_cell(BATCH_SIZE)\n",
- " self.decoder = tfa.seq2seq.BasicDecoder(self.rnn_cell, sampler= self.sampler,\n",
- " output_layer=self.dense_layer)\n",
- "\n",
- " def build_attention_mechanism(self, units,memory, memory_sequence_length):\n",
- " return tfa.seq2seq.LuongAttention(units, memory = memory, \n",
- " memory_sequence_length=memory_sequence_length)\n",
- " #return tfa.seq2seq.BahdanauAttention(units, memory = memory, memory_sequence_length=memory_sequence_length)\n",
- "\n",
- " # wrap decodernn cell \n",
- " def build_rnn_cell(self, batch_size ):\n",
- " rnn_cell = tfa.seq2seq.AttentionWrapper(self.decoder_rnncell, self.attention_mechanism,\n",
- " attention_layer_size=dense_units)\n",
- " return rnn_cell\n",
- " \n",
- " def build_decoder_initial_state(self, batch_size, encoder_state,Dtype):\n",
- " decoder_initial_state = self.rnn_cell.get_initial_state(batch_size = batch_size, \n",
- " dtype = Dtype)\n",
- " decoder_initial_state = decoder_initial_state.clone(cell_state=encoder_state) \n",
- " return decoder_initial_state\n",
+ "EPOCHS = 10\n",
"\n",
- "encoderNetwork = EncoderNetwork(input_vocab_size,embedding_dims, rnn_units)\n",
- "decoderNetwork = DecoderNetwork(output_vocab_size,embedding_dims, rnn_units)\n",
- "optimizer = tf.keras.optimizers.Adam()\n"
+ "for epoch in range(EPOCHS):\n",
+ " start = time.time()\n",
+ "\n",
+ " enc_hidden = encoder.initialize_hidden_state()\n",
+ " total_loss = 0\n",
+ " # print(enc_hidden[0].shape, enc_hidden[1].shape)\n",
+ "\n",
+ " for (batch, (inp, targ)) in enumerate(train_dataset.take(steps_per_epoch)):\n",
+ " batch_loss = train_step(inp, targ, enc_hidden)\n",
+ " total_loss += batch_loss\n",
+ "\n",
+ " if batch % 100 == 0:\n",
+ " print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,\n",
+ " batch,\n",
+ " batch_loss.numpy()))\n",
+ " # saving (checkpoint) the model every 2 epochs\n",
+ " if (epoch + 1) % 2 == 0:\n",
+ " checkpoint.save(file_prefix = checkpoint_prefix)\n",
+ "\n",
+ " print('Epoch {} Loss {:.4f}'.format(epoch + 1,\n",
+ " total_loss / steps_per_epoch))\n",
+ " print('Time taken for 1 epoch {} sec\\n'.format(time.time() - start))"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "NPwcfddTa0oB"
+ "id": "mU3Ce8M6I3rz"
},
"source": [
- "## Initializing Training functions"
+ "## Use tf-addons BasicDecoder for decoding\n"
]
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 98,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "x1BEqVyra2jW"
+ "id": "EbQpyYs13jF_"
},
"outputs": [],
"source": [
- "def loss_function(y_pred, y):\n",
- " \n",
- " #shape of y [batch_size, ty]\n",
- " #shape of y_pred [batch_size, Ty, output_vocab_size] \n",
- " sparsecategoricalcrossentropy = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True,\n",
- " reduction='none')\n",
- " loss = sparsecategoricalcrossentropy(y_true=y, y_pred=y_pred)\n",
- " mask = tf.logical_not(tf.math.equal(y,0)) #output 0 for y=0 else output 1\n",
- " mask = tf.cast(mask, dtype=loss.dtype)\n",
- " loss = mask* loss\n",
- " loss = tf.reduce_mean(loss)\n",
- " return loss\n",
- "\n",
- "def train_step(input_batch, output_batch,encoder_initial_cell_state):\n",
- " #initialize loss = 0\n",
- " loss = 0\n",
- " with tf.GradientTape() as tape:\n",
- " encoder_emb_inp = encoderNetwork.encoder_embedding(input_batch)\n",
- " a, a_tx, c_tx = encoderNetwork.encoder_rnnlayer(encoder_emb_inp, \n",
- " initial_state =encoder_initial_cell_state)\n",
- "\n",
- " #[last step activations,last memory_state] of encoder passed as input to decoder Network\n",
- " \n",
- " \n",
- " # Prepare correct Decoder input & output sequence data\n",
- " decoder_input = output_batch[:,:-1] # ignore \n",
- " #compare logits with timestepped +1 version of decoder_input\n",
- " decoder_output = output_batch[:,1:] #ignore \n",
+ "def evaluate_sentence(sentence):\n",
+ " sentence = dataset_creator.preprocess_sentence(sentence)\n",
"\n",
+ " inputs = [inp_lang.word_index[i] for i in sentence.split(' ')]\n",
+ " inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs],\n",
+ " maxlen=max_length_input,\n",
+ " padding='post')\n",
+ " inputs = tf.convert_to_tensor(inputs)\n",
+ " inference_batch_size = inputs.shape[0]\n",
+ " result = ''\n",
"\n",
- " # Decoder Embeddings\n",
- " decoder_emb_inp = decoderNetwork.decoder_embedding(decoder_input)\n",
+ " enc_start_state = [tf.zeros((inference_batch_size, units)), tf.zeros((inference_batch_size,units))]\n",
+ " enc_out, enc_h, enc_c = encoder(inputs, enc_start_state)\n",
"\n",
- " #Setting up decoder memory from encoder output and Zero State for AttentionWrapperState\n",
- " decoderNetwork.attention_mechanism.setup_memory(a)\n",
- " decoder_initial_state = decoderNetwork.build_decoder_initial_state(BATCH_SIZE,\n",
- " encoder_state=[a_tx, c_tx],\n",
- " Dtype=tf.float32)\n",
- " \n",
- " #BasicDecoderOutput \n",
- " outputs, _, _ = decoderNetwork.decoder(decoder_emb_inp,initial_state=decoder_initial_state,\n",
- " sequence_length=BATCH_SIZE*[Ty-1])\n",
+ " dec_h = enc_h\n",
+ " dec_c = enc_c\n",
+ "\n",
+ " start_tokens = tf.fill([inference_batch_size], targ_lang.word_index[''])\n",
+ " end_token = targ_lang.word_index['']\n",
+ "\n",
+ " greedy_sampler = tfa.seq2seq.GreedyEmbeddingSampler()\n",
+ "\n",
+ " # Instantiate BasicDecoder object\n",
+ " decoder_instance = tfa.seq2seq.BasicDecoder(cell=decoder.rnn_cell, sampler=greedy_sampler, output_layer=decoder.fc)\n",
+ " # Setup Memory in decoder stack\n",
+ " decoder.attention_mechanism.setup_memory(enc_out)\n",
+ "\n",
+ " # set decoder_initial_state\n",
+ " decoder_initial_state = decoder.build_initial_state(inference_batch_size, [enc_h, enc_c], tf.float32)\n",
"\n",
- " logits = outputs.rnn_output\n",
- " #Calculate loss\n",
"\n",
- " loss = loss_function(logits, decoder_output)\n",
+ " ### Since the BasicDecoder wraps around Decoder's rnn cell only, you have to ensure that the inputs to BasicDecoder \n",
+ " ### decoding step is output of embedding layer. tfa.seq2seq.GreedyEmbeddingSampler() takes care of this. \n",
+ " ### You only need to get the weights of embedding layer, which can be done by decoder.embedding.variables[0] and pass this callabble to BasicDecoder's call() function\n",
"\n",
- " #Returns the list of all layer variables / weights.\n",
- " variables = encoderNetwork.trainable_variables + decoderNetwork.trainable_variables \n",
- " # differentiate loss wrt variables\n",
- " gradients = tape.gradient(loss, variables)\n",
+ " decoder_embedding_matrix = decoder.embedding.variables[0]\n",
+ " \n",
+ " outputs, _, _ = decoder_instance(decoder_embedding_matrix, start_tokens = start_tokens, end_token= end_token, initial_state=decoder_initial_state)\n",
+ " return outputs.sample_id.numpy()\n",
"\n",
- " #grads_and_vars – List of(gradient, variable) pairs.\n",
- " grads_and_vars = zip(gradients,variables)\n",
- " optimizer.apply_gradients(grads_and_vars)\n",
- " return loss"
+ "def translate(sentence):\n",
+ " result = evaluate_sentence(sentence)\n",
+ " print(result)\n",
+ " result = targ_lang.sequences_to_texts(result)\n",
+ " print('Input: %s' % (sentence))\n",
+ " print('Predicted translation: {}'.format(result))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "n250XbnjOaqP"
+ },
+ "source": [
+ "## Restore the latest checkpoint and test"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "71Lkdx6GFb3A"
+ "id": "UJpT9D5_OgP6"
},
- "outputs": [],
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 20,
+ "metadata": {
+ "tags": []
+ },
+ "output_type": "execute_result"
+ }
+ ],
"source": [
- "#RNN LSTM hidden and memory state initializer\n",
- "def initialize_initial_state():\n",
- " return [tf.zeros((BATCH_SIZE, rnn_units)), tf.zeros((BATCH_SIZE, rnn_units))]"
+ "# restoring the latest checkpoint in checkpoint_dir\n",
+ "checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": 99,
"metadata": {
- "colab_type": "text",
- "id": "v5uzLcu2bNX3"
+ "id": "WYmYhNN_faR5"
},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[ 11 12 49 224 40 4 3]]\n",
+ "Input: hace mucho frio aqui.\n",
+ "Predicted translation: ['it s very pretty here . ']\n"
+ ]
+ }
+ ],
"source": [
- "## Training"
+ "translate(u'hace mucho frio aqui.')"
]
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 100,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000
- },
- "colab_type": "code",
- "id": "PvfD2SknWrt6",
- "outputId": "0a427bb7-8184-4076-97ca-f638116ca52b"
+ "id": "zSx2iM36EZQZ"
},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[ 20 9 22 190 4 3]]\n",
+ "Input: esta es mi vida.\n",
+ "Predicted translation: ['this is my life . ']\n"
+ ]
+ }
+ ],
"source": [
- "epochs = 15\n",
- "for i in range(1, epochs+1):\n",
- "\n",
- " encoder_initial_cell_state = initialize_initial_state()\n",
- " total_loss = 0.0\n",
- "\n",
- " for ( batch , (input_batch, output_batch)) in enumerate(dataset.take(steps_per_epoch)):\n",
- " batch_loss = train_step(input_batch, output_batch, encoder_initial_cell_state)\n",
- " total_loss += batch_loss\n",
- " if (batch+1)%5 == 0:\n",
- " print(\"total loss: {} epoch {} batch {} \".format(batch_loss.numpy(), i, batch+1))"
+ "translate(u'esta es mi vida.')"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "colab_type": "text",
- "id": "nDyK-EGqbN5r"
+ "id": "A3LLCx3ZE0Ls"
},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[25 7 90 8 3]]\n",
+ "Input: ¿todavia estan en casa?\n",
+ "Predicted translation: ['are you home ? ']\n"
+ ]
+ }
+ ],
"source": [
- "## Evaluation"
+ "translate(u'¿todavia estan en casa?')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 326
- },
- "colab_type": "code",
- "id": "y98sfom7SuGy",
- "outputId": "00d94338-e841-4bd6-f9e3-509ef1f1a08b"
+ "id": "DUQVLVqUE1YW"
},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[126 16 892 11 75 4 3]]\n",
+ "Input: trata de averiguarlo.\n",
+ "Predicted translation: ['try to figure it out . ']\n"
+ ]
+ }
+ ],
"source": [
- "#In this section we evaluate our model on a raw_input converted to german, for this the entire sentence has to be passed\n",
- "#through the length of the model, for this we use greedsampler to run through the decoder\n",
- "#and the final embedding matrix trained on the data is used to generate embeddings\n",
- "input_raw='how are you'\n",
- "\n",
- "# We have a transcript file containing English-German pairs\n",
- "# Preprocess X\n",
- "input_raw = preprocess(input_raw, add_start_end=False)\n",
- "input_lines = [f'{SOS} {input_raw}']\n",
- "input_sequences = [[en_tokenizer.word_index[w] for w in line.split()] for line in input_lines]\n",
- "input_sequences = tf.keras.preprocessing.sequence.pad_sequences(input_sequences,\n",
- " maxlen=Tx, padding='post')\n",
- "inp = tf.convert_to_tensor(input_sequences)\n",
- "#print(inp.shape)\n",
- "inference_batch_size = input_sequences.shape[0]\n",
- "encoder_initial_cell_state = [tf.zeros((inference_batch_size, rnn_units)),\n",
- " tf.zeros((inference_batch_size, rnn_units))]\n",
- "encoder_emb_inp = encoderNetwork.encoder_embedding(inp)\n",
- "a, a_tx, c_tx = encoderNetwork.encoder_rnnlayer(encoder_emb_inp,\n",
- " initial_state =encoder_initial_cell_state)\n",
- "print('a_tx :', a_tx.shape)\n",
- "print('c_tx :', c_tx.shape)\n",
- "\n",
- "start_tokens = tf.fill([inference_batch_size],ge_tokenizer.word_index[SOS])\n",
- "\n",
- "end_token = ge_tokenizer.word_index[EOS]\n",
- "\n",
- "greedy_sampler = tfa.seq2seq.GreedyEmbeddingSampler()\n",
- "\n",
- "decoder_input = tf.expand_dims([ge_tokenizer.word_index[SOS]]* inference_batch_size,1)\n",
- "decoder_emb_inp = decoderNetwork.decoder_embedding(decoder_input)\n",
- "\n",
- "decoder_instance = tfa.seq2seq.BasicDecoder(cell = decoderNetwork.rnn_cell, sampler = greedy_sampler,\n",
- " output_layer=decoderNetwork.dense_layer)\n",
- "decoderNetwork.attention_mechanism.setup_memory(a)\n",
- "#pass [ last step activations , encoder memory_state ] as input to decoder for LSTM\n",
- "print(f\"decoder_initial_state = [a_tx, c_tx] : {np.array([a_tx, c_tx]).shape}\")\n",
- "decoder_initial_state = decoderNetwork.build_decoder_initial_state(inference_batch_size,\n",
- " encoder_state=[a_tx, c_tx],\n",
- " Dtype=tf.float32)\n",
- "print(f\"\"\"\n",
- "Compared to simple encoder-decoder without attention, the decoder_initial_state\n",
- "is an AttentionWrapperState object containing s_prev tensors and context and alignment vector\n",
- "\n",
- "decoder initial state shape: {np.array(decoder_initial_state).shape}\n",
- "decoder_initial_state tensor\n",
- "{decoder_initial_state}\n",
- "\"\"\")\n",
- "\n",
- "# Since we do not know the target sequence lengths in advance, we use maximum_iterations to limit the translation lengths.\n",
- "# One heuristic is to decode up to two times the source sentence lengths.\n",
- "maximum_iterations = tf.round(tf.reduce_max(Tx) * 2)\n",
- "\n",
- "#initialize inference decoder\n",
- "decoder_embedding_matrix = decoderNetwork.decoder_embedding.variables[0] \n",
- "(first_finished, first_inputs,first_state) = decoder_instance.initialize(decoder_embedding_matrix,\n",
- " start_tokens = start_tokens,\n",
- " end_token=end_token,\n",
- " initial_state = decoder_initial_state)\n",
- "#print( first_finished.shape)\n",
- "print(f\"first_inputs returns the same decoder_input i.e. embedding of {SOS} : {first_inputs.shape}\")\n",
- "print(f\"start_index_emb_avg {tf.reduce_sum(tf.reduce_mean(first_inputs, axis=0))}\") # mean along the batch\n",
- "\n",
- "inputs = first_inputs\n",
- "state = first_state \n",
- "predictions = np.empty((inference_batch_size,0), dtype = np.int32) \n",
- "for j in range(maximum_iterations):\n",
- " outputs, next_state, next_inputs, finished = decoder_instance.step(j,inputs,state)\n",
- " inputs = next_inputs\n",
- " state = next_state\n",
- " outputs = np.expand_dims(outputs.sample_id,axis = -1)\n",
- " predictions = np.append(predictions, outputs, axis = -1)"
+ "# wrong translation\n",
+ "translate(u'trata de averiguarlo.')"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
- "id": "iodjSItQds1t"
+ "id": "IRUuNDeY0HiC"
},
"source": [
- "## Final Translation"
+ "## Use tf-addons BeamSearchDecoder \n"
]
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 89,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 102
- },
- "colab_type": "code",
- "id": "K6aWFB5IWlH2",
- "outputId": "2179c9a3-cb27-447a-ac94-0e5ab2920aff"
+ "id": "AJ-RTQ0hsJNL"
+ },
+ "outputs": [],
+ "source": [
+ "def beam_evaluate_sentence(sentence, beam_width=3):\n",
+ " sentence = dataset_creator.preprocess_sentence(sentence)\n",
+ "\n",
+ " inputs = [inp_lang.word_index[i] for i in sentence.split(' ')]\n",
+ " inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs],\n",
+ " maxlen=max_length_input,\n",
+ " padding='post')\n",
+ " inputs = tf.convert_to_tensor(inputs)\n",
+ " inference_batch_size = inputs.shape[0]\n",
+ " result = ''\n",
+ "\n",
+ " enc_start_state = [tf.zeros((inference_batch_size, units)), tf.zeros((inference_batch_size,units))]\n",
+ " enc_out, enc_h, enc_c = encoder(inputs, enc_start_state)\n",
+ "\n",
+ " dec_h = enc_h\n",
+ " dec_c = enc_c\n",
+ "\n",
+ " start_tokens = tf.fill([inference_batch_size], targ_lang.word_index[''])\n",
+ " end_token = targ_lang.word_index['']\n",
+ "\n",
+ " # From official documentation\n",
+ " # NOTE If you are using the BeamSearchDecoder with a cell wrapped in AttentionWrapper, then you must ensure that:\n",
+ " # The encoder output has been tiled to beam_width via tfa.seq2seq.tile_batch (NOT tf.tile).\n",
+ " # The batch_size argument passed to the get_initial_state method of this wrapper is equal to true_batch_size * beam_width.\n",
+ " # The initial state created with get_initial_state above contains a cell_state value containing properly tiled final state from the encoder.\n",
+ "\n",
+ " enc_out = tfa.seq2seq.tile_batch(enc_out, multiplier=beam_width)\n",
+ " decoder.attention_mechanism.setup_memory(enc_out)\n",
+ " print(\"beam_with * [batch_size, max_length_input, rnn_units] : 3 * [1, 16, 1024]] :\", enc_out.shape)\n",
+ "\n",
+ " # set decoder_inital_state which is an AttentionWrapperState considering beam_width\n",
+ " hidden_state = tfa.seq2seq.tile_batch([enc_h, enc_c], multiplier=beam_width)\n",
+ " decoder_initial_state = decoder.rnn_cell.get_initial_state(batch_size=beam_width*inference_batch_size, dtype=tf.float32)\n",
+ " decoder_initial_state = decoder_initial_state.clone(cell_state=hidden_state)\n",
+ "\n",
+ " # Instantiate BeamSearchDecoder\n",
+ " decoder_instance = tfa.seq2seq.BeamSearchDecoder(decoder.rnn_cell,beam_width=beam_width, output_layer=decoder.fc)\n",
+ " decoder_embedding_matrix = decoder.embedding.variables[0]\n",
+ "\n",
+ " # The BeamSearchDecoder object's call() function takes care of everything.\n",
+ " outputs, final_state, sequence_lengths = decoder_instance(decoder_embedding_matrix, start_tokens=start_tokens, end_token=end_token, initial_state=decoder_initial_state)\n",
+ " # outputs is tfa.seq2seq.FinalBeamSearchDecoderOutput object. \n",
+ " # The final beam predictions are stored in outputs.predicted_id\n",
+ " # outputs.beam_search_decoder_output is a tfa.seq2seq.BeamSearchDecoderOutput object which keep tracks of beam_scores and parent_ids while performing a beam decoding step\n",
+ " # final_state = tfa.seq2seq.BeamSearchDecoderState object.\n",
+ " # Sequence Length = [inference_batch_size, beam_width] details the maximum length of the beams that are generated\n",
+ "\n",
+ " \n",
+ " # outputs.predicted_id.shape = (inference_batch_size, time_step_outputs, beam_width)\n",
+ " # outputs.beam_search_decoder_output.scores.shape = (inference_batch_size, time_step_outputs, beam_width)\n",
+ " # Convert the shape of outputs and beam_scores to (inference_batch_size, beam_width, time_step_outputs)\n",
+ " final_outputs = tf.transpose(outputs.predicted_ids, perm=(0,2,1))\n",
+ " beam_scores = tf.transpose(outputs.beam_search_decoder_output.scores, perm=(0,2,1))\n",
+ " \n",
+ " return final_outputs.numpy(), beam_scores.numpy()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 90,
+ "metadata": {
+ "id": "g_LvXGvX8X-O"
},
"outputs": [],
"source": [
- "#prediction based on our sentence earlier\n",
- "print(\"English Sentence:\")\n",
- "print(input_raw)\n",
- "print(\"\\nGerman Translation:\")\n",
- "for i in range(len(predictions)):\n",
- " line = predictions[i,:]\n",
- " seq = list(itertools.takewhile( lambda index: index !=2, line))\n",
- " print(\" \".join( [ge_tokenizer.index_word[w] for w in seq]))"
+ "def beam_translate(sentence):\n",
+ " result, beam_scores = beam_evaluate_sentence(sentence)\n",
+ " print(result.shape, beam_scores.shape)\n",
+ " for beam, score in zip(result, beam_scores):\n",
+ " print(beam.shape, score.shape)\n",
+ " output = targ_lang.sequences_to_texts(beam)\n",
+ " output = [a[:a.index('')] for a in output]\n",
+ " beam_score = [a.sum() for a in score]\n",
+ " print('Input: %s' % (sentence))\n",
+ " for i in range(len(output)):\n",
+ " print('{} Predicted translation: {} {}'.format(i+1, output[i], beam_score[i]))\n"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": 91,
+ "metadata": {
+ "id": "TODnXBleDzzO"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "beam_with * [batch_size, max_length_input, rnn_units] : 3 * [1, 16, 1024]] : (3, 16, 1024)\n",
+ "(1, 3, 7) (1, 3, 7)\n",
+ "(3, 7) (3, 7)\n",
+ "Input: hace mucho frio aqui.\n",
+ "1 Predicted translation: it s very pretty here . -4.117094039916992\n",
+ "2 Predicted translation: it s very cold here . -14.85302734375\n",
+ "3 Predicted translation: it s very pretty news . -25.59416389465332\n"
+ ]
+ }
+ ],
+ "source": [
+ "beam_translate(u'hace mucho frio aqui.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
- "colab_type": "text",
- "id": "g6Av-oPWvRc4"
+ "id": "_BezQwENFY3L"
},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "beam_with * [batch_size, max_length_input, rnn_units] : 3 * [1, 16, 1024]] : (3, 16, 1024)\n",
+ "(1, 3, 7) (1, 3, 7)\n",
+ "(3, 7) (3, 7)\n",
+ "Input: ¿todavia estan en casa?\n",
+ "1 Predicted translation: are you still home ? -4.036754131317139\n",
+ "2 Predicted translation: are you still at home ? -15.306867599487305\n",
+ "3 Predicted translation: are you still go home ? -20.533388137817383\n"
+ ]
+ }
+ ],
"source": [
- "### The accuracy can be improved by implementing:\n",
- "* Beam Search or Lexicon Search\n",
- "* Bi-directional encoder-decoder model "
+ "beam_translate(u'¿todavia estan en casa?')"
]
}
],
@@ -816,13 +1093,10 @@
"colab": {
"collapsed_sections": [],
"name": "networks_seq2seq_nmt.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
- "language": "python",
"name": "python3"
}
},
diff --git a/docs/tutorials/optimizers_conditionalgradient.ipynb b/docs/tutorials/optimizers_conditionalgradient.ipynb
index b825a0903e..8ac4c1f6d8 100644
--- a/docs/tutorials/optimizers_conditionalgradient.ipynb
+++ b/docs/tutorials/optimizers_conditionalgradient.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "pGUYKbJNWNgj"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "1PzPJglSWgnW"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "b5P4BEg1XYd5"
},
"source": [
@@ -63,7 +59,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Faj8luWnYNSG"
},
"source": [
@@ -74,20 +69,18 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MrDjqjY6YRYM"
},
"source": [
"# ConditionalGradient\n",
"\n",
"\n",
- "> Constraining the parameters of a neural network has been shown to be beneficial in training because of the underlying regularization effects. Often, parameters are constrained via a soft penalty (which never guarantees the constraint satisfaction) or via a projection operation (which is computationally expensive). Conditional gradient (CG) optimizer, on the other hand, enforces the constraints strictly without the need for an expensive projection step. It works by minimizing a linear approximation of the objective within the constraint set. In this notebook, we demonstrate the appliction of Frobenius norm constraint via the CG optimizer on the MNIST dataset. CG is now available as a tensorflow API. More details of the optimizer are available at https://arxiv.org/pdf/1803.06453.pdf\n"
+ "> Constraining the parameters of a neural network has been shown to be beneficial in training because of the underlying regularization effects. Often, parameters are constrained via a soft penalty (which never guarantees the constraint satisfaction) or via a projection operation (which is computationally expensive). Conditional gradient (CG) optimizer, on the other hand, enforces the constraints strictly without the need for an expensive projection step. It works by minimizing a linear approximation of the objective within the constraint set. In this notebook, you demonstrate the appliction of Frobenius norm constraint via the CG optimizer on the MNIST dataset. CG is now available as a tensorflow API. More details of the optimizer are available at https://arxiv.org/pdf/1803.06453.pdf\n"
]
},
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "dooBaYGLYYnn"
},
"source": [
@@ -97,7 +90,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "2sCyoNXlgGbk"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -107,13 +102,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 34
- },
- "colab_type": "code",
- "id": "qYo0FkL4O7io",
- "outputId": "7c40f5df-075a-4d9f-910e-7dff84c46b1f"
+ "id": "qYo0FkL4O7io"
},
"outputs": [],
"source": [
@@ -126,8 +115,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "kR0PnjrIirpJ"
},
"outputs": [],
@@ -140,7 +127,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "-x0WBp-IYz7x"
},
"source": [
@@ -151,8 +137,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "4KzMDUT0i1QE"
},
"outputs": [],
@@ -167,7 +151,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "XGADNG3-Y7aa"
},
"source": [
@@ -178,13 +161,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 52
- },
- "colab_type": "code",
- "id": "d6a-kbM_i1b2",
- "outputId": "248bd642-2d06-4da5-acbe-b1bf59d335b0"
+ "id": "d6a-kbM_i1b2"
},
"outputs": [],
"source": [
@@ -201,7 +178,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "sOlB-WqjZp1Y"
},
"source": [
@@ -212,8 +188,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "8LCmRXUgZqyV"
},
"outputs": [],
@@ -236,8 +210,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "udSvzKm4Z5Zr"
},
"outputs": [],
@@ -251,7 +223,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "qfhE1DfwZC1i"
},
"source": [
@@ -264,13 +235,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 382
- },
- "colab_type": "code",
- "id": "6-AMaOYEi1kK",
- "outputId": "28534147-5ccd-48cf-f8b5-a6afdcf7612a"
+ "id": "6-AMaOYEi1kK"
},
"outputs": [],
"source": [
@@ -293,7 +258,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "8OJp4So9bYYR"
},
"source": [
@@ -304,8 +268,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "SuizUueqn449"
},
"outputs": [],
@@ -321,8 +283,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "V8QC3xCwbfNl"
},
"outputs": [],
@@ -337,13 +297,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 382
- },
- "colab_type": "code",
- "id": "9BNi4yXGcDlg",
- "outputId": "be21bdc7-c693-4663-fa5a-f036fc4b6140"
+ "id": "9BNi4yXGcDlg"
},
"outputs": [],
"source": [
@@ -365,7 +319,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "1Myw0FVcd_Z9"
},
"source": [
@@ -375,24 +328,17 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "0tJYQBRt-ZUl"
},
"source": [
- "The current implementation of CG optimizer is based on Frobenius Norm, with considering Frobenius Norm as regularizer in the target function. Therefore, we compare CG’s regularized effect with SGD optimizer, which has not imposed Frobenius Norm regularizer."
+ "The current implementation of CG optimizer is based on Frobenius Norm, with considering Frobenius Norm as regularizer in the target function. Therefore, you compare CG’s regularized effect with SGD optimizer, which has not imposed Frobenius Norm regularizer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 296
- },
- "colab_type": "code",
- "id": "Ewf17MW1cJVI",
- "outputId": "481d5d00-5642-458d-aa86-225d7faf07ff"
+ "id": "Ewf17MW1cJVI"
},
"outputs": [],
"source": [
@@ -412,7 +358,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "JGtutiXuoZyx"
},
"source": [
@@ -423,13 +368,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 296
- },
- "colab_type": "code",
- "id": "s-SNIr10o2va",
- "outputId": "1226fcbd-b71a-442b-811c-7155edbe623d"
+ "id": "s-SNIr10o2va"
},
"outputs": [],
"source": [
@@ -448,8 +387,6 @@
"colab": {
"collapsed_sections": [],
"name": "optimizers_conditionalgradient.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/optimizers_lazyadam.ipynb b/docs/tutorials/optimizers_lazyadam.ipynb
index 1d688abb5e..90d0de2370 100644
--- a/docs/tutorials/optimizers_lazyadam.ipynb
+++ b/docs/tutorials/optimizers_lazyadam.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Tce3stUlHN0L"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "tuOe1ymfHZPu"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MfBg1C5NB3X0"
},
"source": [
@@ -62,7 +58,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "xHxb-dlhMIzW"
},
"source": [
@@ -74,7 +69,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "bQwBbFVAyHJ_"
},
"source": [
@@ -95,7 +89,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MUXex9ctTuDB"
},
"source": [
@@ -105,7 +98,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "cHAOyeOVx-k3"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -115,8 +110,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "42ztALK4ZdyZ"
},
"outputs": [],
@@ -129,8 +122,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "ys65MwOLKnXq"
},
"outputs": [],
@@ -143,7 +134,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "KR01t9v_fxbT"
},
"source": [
@@ -154,8 +144,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "djpoAvfWNyL5"
},
"outputs": [],
@@ -170,7 +158,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "0_D7CZqkv_Hj"
},
"source": [
@@ -181,8 +168,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "U0bS3SyowBoB"
},
"outputs": [],
@@ -200,7 +185,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "HYE-BxhOzFQp"
},
"source": [
@@ -213,8 +197,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "NxfYhtiSzHf-"
},
"outputs": [],
@@ -237,8 +219,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "1Y--0tK69SXf"
},
"outputs": [],
@@ -255,8 +235,6 @@
"colab": {
"collapsed_sections": [],
"name": "optimizers_lazyadam.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/time_stopping.ipynb b/docs/tutorials/time_stopping.ipynb
index dae8d40bd4..bbcc83d673 100644
--- a/docs/tutorials/time_stopping.ipynb
+++ b/docs/tutorials/time_stopping.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "mz0tl581YjZ0"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "hi0OrWAIYjZ4"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "gyGdPCvQYjaI"
},
"source": [
@@ -47,7 +43,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "Z5csJXPVYjaM"
},
"source": [
@@ -70,7 +65,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "BJhody3KYjaP"
},
"source": [
@@ -81,7 +75,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "SaZsCaGbYjaU"
},
"source": [
@@ -91,7 +84,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "VgJGPL3ts_1i"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -101,8 +96,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "fm_dHPvEYjar"
},
"outputs": [],
@@ -117,7 +110,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "vg0y1DrQYja4"
},
"source": [
@@ -128,13 +120,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 52
- },
- "colab_type": "code",
- "id": "HydkzZTuYja8",
- "outputId": "bacf85d9-1b6a-42a3-98ff-e3926f54a3f2"
+ "id": "HydkzZTuYja8"
},
"outputs": [],
"source": [
@@ -147,7 +133,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "uX02I1kxYjbL"
},
"source": [
@@ -158,8 +143,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "Tlk0MyEfYjbN"
},
"outputs": [],
@@ -179,7 +162,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "b5Xcyt0qYjbX"
},
"source": [
@@ -190,14 +172,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 139
- },
- "colab_type": "code",
- "id": "W82_IZ6iYjbZ",
- "outputId": "3518f04b-38d1-4974-cbf9-42ff8a9b581e",
- "scrolled": true
+ "id": "W82_IZ6iYjbZ"
},
"outputs": [],
"source": [
@@ -218,8 +193,6 @@
"metadata": {
"colab": {
"name": "time_stopping.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/docs/tutorials/tqdm_progress_bar.ipynb b/docs/tutorials/tqdm_progress_bar.ipynb
index 9debbf6510..7a3927d7ed 100644
--- a/docs/tutorials/tqdm_progress_bar.ipynb
+++ b/docs/tutorials/tqdm_progress_bar.ipynb
@@ -3,7 +3,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "MyujzrAv2Vpk"
},
"source": [
@@ -15,8 +14,6 @@
"execution_count": null,
"metadata": {
"cellView": "form",
- "colab": {},
- "colab_type": "code",
"id": "rTUqXTqa2Vpm"
},
"outputs": [],
@@ -37,7 +34,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "rNnfCHh82Vpq"
},
"source": [
@@ -47,7 +43,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "4qrDJoTw2Vps"
},
"source": [
@@ -70,7 +65,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "bVS_PkvX2Vpt"
},
"source": [
@@ -81,7 +75,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "sRldODz32Vpu"
},
"source": [
@@ -91,7 +84,9 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "id": "H0yZwcvcR4Gc"
+ },
"outputs": [],
"source": [
"!pip install -U tensorflow-addons"
@@ -101,8 +96,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "etYr-Suo4KYj"
},
"outputs": [],
@@ -121,8 +114,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "SfXA0mI13pSE"
},
"outputs": [],
@@ -144,7 +135,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "2RGuwIwe2Vp7"
},
"source": [
@@ -155,8 +145,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "qKfrsOSP2Vp8"
},
"outputs": [],
@@ -170,7 +158,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "ORtL0s4X2VqB"
},
"source": [
@@ -181,8 +168,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "z8uAGGV32VqC"
},
"outputs": [],
@@ -202,7 +187,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "YWOnH1ga2VqF"
},
"source": [
@@ -213,10 +197,7 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
- "id": "Vl_oj_OW2VqG",
- "scrolled": true
+ "id": "Vl_oj_OW2VqG"
},
"outputs": [],
"source": [
@@ -237,7 +218,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "uFvBfwJN2VqK"
},
"source": [
@@ -249,8 +229,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "colab": {},
- "colab_type": "code",
"id": "Np3dD8bhe10E"
},
"outputs": [],
@@ -262,7 +240,6 @@
{
"cell_type": "markdown",
"metadata": {
- "colab_type": "text",
"id": "36WRBMo7e10I"
},
"source": [
@@ -274,8 +251,6 @@
"metadata": {
"colab": {
"name": "tqdm_progress_bar.ipynb",
- "private_outputs": true,
- "provenance": [],
"toc_visible": true
},
"kernelspec": {
diff --git a/tensorflow_addons/image/filters.py b/tensorflow_addons/image/filters.py
index 6e3da3e1ba..92046f50ec 100644
--- a/tensorflow_addons/image/filters.py
+++ b/tensorflow_addons/image/filters.py
@@ -211,8 +211,7 @@ def _get_gaussian_kernel(sigma, filter_shape):
sigma = tf.convert_to_tensor(sigma)
x = tf.range(-filter_shape // 2 + 1, filter_shape // 2 + 1)
x = tf.cast(x ** 2, sigma.dtype)
- x = tf.exp(-x / (2.0 * (sigma ** 2)))
- x = x / tf.math.reduce_sum(x)
+ x = tf.nn.softmax(-x / (2.0 * (sigma ** 2)))
return x
@@ -291,18 +290,16 @@ def gaussian_filter2d(
sigma = tf.cast(sigma, image.dtype)
gaussian_kernel_x = _get_gaussian_kernel(sigma[1], filter_shape[1])
- gaussian_kernel_x = tf.reshape(gaussian_kernel_x, [1, filter_shape[1]])
+ gaussian_kernel_x = gaussian_kernel_x[tf.newaxis, :]
gaussian_kernel_y = _get_gaussian_kernel(sigma[0], filter_shape[0])
- gaussian_kernel_y = tf.reshape(gaussian_kernel_y, [filter_shape[0], 1])
+ gaussian_kernel_y = gaussian_kernel_y[:, tf.newaxis]
gaussian_kernel_2d = _get_gaussian_kernel_2d(
gaussian_kernel_y, gaussian_kernel_x
)
- gaussian_kernel_2d = tf.repeat(gaussian_kernel_2d, channels)
- gaussian_kernel_2d = tf.reshape(
- gaussian_kernel_2d, [filter_shape[0], filter_shape[1], channels, 1]
- )
+ gaussian_kernel_2d = gaussian_kernel_2d[:, :, tf.newaxis, tf.newaxis]
+ gaussian_kernel_2d = tf.tile(gaussian_kernel_2d, [1, 1, channels, 1])
image = _pad(image, filter_shape, mode=padding, constant_values=constant_values)
diff --git a/tensorflow_addons/image/tests/transform_ops_test.py b/tensorflow_addons/image/tests/transform_ops_test.py
index 094024bb2f..e208aa314b 100644
--- a/tensorflow_addons/image/tests/transform_ops_test.py
+++ b/tensorflow_addons/image/tests/transform_ops_test.py
@@ -68,6 +68,62 @@ def test_extreme_projective_transform(dtype):
)
+@pytest.mark.with_device(["cpu", "gpu"])
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+@pytest.mark.parametrize("dtype", _DTYPES)
+def test_transform_constant_fill_mode(dtype):
+ image = tf.constant(
+ [[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]], dtype=dtype
+ )
+ expected = np.asarray(
+ [[0, 0, 1, 2], [0, 4, 5, 6], [0, 8, 9, 10], [0, 12, 13, 14]],
+ dtype=dtype.as_numpy_dtype,
+ )
+ # Translate right by 1 (the transformation matrix is always inverted,
+ # hence the -1).
+ translation = tf.constant([1, 0, -1, 0, 1, 0, 0, 0], dtype=tf.float32)
+ image_transformed = transform_ops.transform(
+ image, translation, fill_mode="constant"
+ )
+ np.testing.assert_equal(image_transformed.numpy(), expected)
+
+
+@pytest.mark.with_device(["cpu", "gpu"])
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+@pytest.mark.parametrize("dtype", _DTYPES)
+def test_transform_reflect_fill_mode(dtype):
+ image = tf.constant(
+ [[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]], dtype=dtype
+ )
+ expected = np.asarray(
+ [[0, 0, 1, 2], [4, 4, 5, 6], [8, 8, 9, 10], [12, 12, 13, 14]],
+ dtype=dtype.as_numpy_dtype,
+ )
+ # Translate right by 1 (the transformation matrix is always inverted,
+ # hence the -1).
+ translation = tf.constant([1, 0, -1, 0, 1, 0, 0, 0], dtype=tf.float32)
+ image_transformed = transform_ops.transform(image, translation, fill_mode="reflect")
+ np.testing.assert_equal(image_transformed.numpy(), expected)
+
+
+@pytest.mark.with_device(["cpu", "gpu"])
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+@pytest.mark.parametrize("dtype", _DTYPES)
+def test_transform_wrap_fill_mode(dtype):
+ image = tf.constant(
+ [[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]], dtype=dtype
+ )
+ expected = np.asarray(
+ [[3, 0, 1, 2], [7, 4, 5, 6], [11, 8, 9, 10], [15, 12, 13, 14]],
+ dtype=dtype.as_numpy_dtype,
+ )
+ # Translate right by 1 (the transformation matrix is always inverted,
+ # hence the -1).
+ translation = tf.constant([1, 0, -1, 0, 1, 0, 0, 0], dtype=tf.float32)
+ image_transformed = transform_ops.transform(image, translation, fill_mode="wrap")
+ np.testing.assert_equal(image_transformed.numpy(), expected)
+
+
@pytest.mark.usefixtures("maybe_run_functions_eagerly")
def test_transform_static_output_shape():
image = tf.constant([[1.0, 2.0], [3.0, 4.0]])
diff --git a/tensorflow_addons/image/transform_ops.py b/tensorflow_addons/image/transform_ops.py
index c9bbf4804d..d789ec7fbb 100644
--- a/tensorflow_addons/image/transform_ops.py
+++ b/tensorflow_addons/image/transform_ops.py
@@ -36,6 +36,7 @@ def transform(
images: TensorLike,
transforms: TensorLike,
interpolation: str = "NEAREST",
+ fill_mode: str = "CONSTANT",
output_shape: Optional[list] = None,
name: Optional[str] = None,
) -> tf.Tensor:
@@ -55,6 +56,15 @@ def transform(
gradients are not backpropagated into transformation parameters.
interpolation: Interpolation mode.
Supported values: "NEAREST", "BILINEAR".
+ fill_mode: Points outside the boundaries of the input are filled according
+ to the given mode (one of `{'constant', 'reflect', 'wrap'}`).
+ - *reflect*: `(d c b a | a b c d | d c b a)`
+ The input is extended by reflecting about the edge of the last pixel.
+ - *constant*: `(k k k k | a b c d | k k k k)`
+ The input is extended by filling all values beyond the edge with the
+ same constant value k = 0.
+ - *wrap*: `(a b c d | a b c d | a b c d)`
+ The input is extended by wrapping around to the opposite edge.
output_shape: Output dimesion after the transform, [height, width].
If None, output is the same size as input image.
@@ -105,11 +115,13 @@ def transform(
% len(transforms.get_shape())
)
+ # TODO(WindQAQ): Support "nearest" `fill_mode` and `fill_value` in TF2.4.
output = tf.raw_ops.ImageProjectiveTransformV2(
images=images,
transforms=transforms,
output_shape=output_shape,
interpolation=interpolation.upper(),
+ fill_mode=fill_mode.upper(),
)
return img_utils.from_4D_image(output, original_ndims)
@@ -268,6 +280,7 @@ def rotate(
images: TensorLike,
angles: TensorLike,
interpolation: str = "NEAREST",
+ fill_mode: str = "CONSTANT",
name: Optional[str] = None,
) -> tf.Tensor:
"""Rotate image(s) counterclockwise by the passed angle(s) in radians.
@@ -282,6 +295,15 @@ def rotate(
batch.
interpolation: Interpolation mode. Supported values: "NEAREST",
"BILINEAR".
+ fill_mode: Points outside the boundaries of the input are filled according
+ to the given mode (one of `{'constant', 'reflect', 'wrap'}`).
+ - *reflect*: `(d c b a | a b c d | d c b a)`
+ The input is extended by reflecting about the edge of the last pixel.
+ - *constant*: `(k k k k | a b c d | k k k k)`
+ The input is extended by filling all values beyond the edge with the
+ same constant value k = 0.
+ - *wrap*: `(a b c d | a b c d | a b c d)`
+ The input is extended by wrapping around to the opposite edge.
name: The name of the op.
Returns:
@@ -304,6 +326,7 @@ def rotate(
images,
angles_to_projective_transforms(angles, image_height, image_width),
interpolation=interpolation,
+ fill_mode=fill_mode,
)
return img_utils.from_4D_image(output, original_ndims)
diff --git a/tensorflow_addons/image/translate_ops.py b/tensorflow_addons/image/translate_ops.py
index e51eafefbc..e0f4516bc0 100644
--- a/tensorflow_addons/image/translate_ops.py
+++ b/tensorflow_addons/image/translate_ops.py
@@ -75,26 +75,36 @@ def translate(
images: TensorLike,
translations: TensorLike,
interpolation: str = "NEAREST",
+ fill_mode: str = "CONSTANT",
name: Optional[str] = None,
) -> tf.Tensor:
"""Translate image(s) by the passed vectors(s).
Args:
images: A tensor of shape
- `(num_images, num_rows, num_columns, num_channels)` (NHWC),
- `(num_rows, num_columns, num_channels)` (HWC), or
- `(num_rows, num_columns)` (HW). The rank must be statically known (the
- shape is not `TensorShape(None)`).
+ `(num_images, num_rows, num_columns, num_channels)` (NHWC),
+ `(num_rows, num_columns, num_channels)` (HWC), or
+ `(num_rows, num_columns)` (HW). The rank must be statically known (the
+ shape is not `TensorShape(None)`).
translations: A vector representing `[dx, dy]` or (if `images` has rank 4)
- a matrix of length num_images, with a `[dx, dy]` vector for each image
- in the batch.
+ a matrix of length num_images, with a `[dx, dy]` vector for each image
+ in the batch.
interpolation: Interpolation mode. Supported values: "NEAREST",
- "BILINEAR".
+ "BILINEAR".
+ fill_mode: Points outside the boundaries of the input are filled according
+ to the given mode (one of `{'constant', 'reflect', 'wrap'}`).
+ - *reflect*: `(d c b a | a b c d | d c b a)`
+ The input is extended by reflecting about the edge of the last pixel.
+ - *constant*: `(k k k k | a b c d | k k k k)`
+ The input is extended by filling all values beyond the edge with the
+ same constant value k = 0.
+ - *wrap*: `(a b c d | a b c d | a b c d)`
+ The input is extended by wrapping around to the opposite edge.
name: The name of the op.
Returns:
Image(s) with the same type and shape as `images`, translated by the
- given vector(s). Empty space due to the translation will be filled with
- zeros.
+ given vector(s). Empty space due to the translation will be filled with
+ zeros.
Raises:
TypeError: If `images` is an invalid type.
"""
@@ -103,6 +113,7 @@ def translate(
images,
translations_to_projective_transforms(translations),
interpolation=interpolation,
+ fill_mode=fill_mode,
)
diff --git a/tensorflow_addons/layers/__init__.py b/tensorflow_addons/layers/__init__.py
index 594d025a9f..7c89f95a06 100644
--- a/tensorflow_addons/layers/__init__.py
+++ b/tensorflow_addons/layers/__init__.py
@@ -38,3 +38,5 @@
from tensorflow_addons.layers.tlu import TLU
from tensorflow_addons.layers.wrappers import WeightNormalization
from tensorflow_addons.layers.esn import ESN
+from tensorflow_addons.layers.stochastic_depth import StochasticDepth
+from tensorflow_addons.layers.noisy_dense import NoisyDense
diff --git a/tensorflow_addons/layers/noisy_dense.py b/tensorflow_addons/layers/noisy_dense.py
new file mode 100644
index 0000000000..647b28db7d
--- /dev/null
+++ b/tensorflow_addons/layers/noisy_dense.py
@@ -0,0 +1,264 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import tensorflow as tf
+from tensorflow.keras import (
+ activations,
+ initializers,
+ regularizers,
+ constraints,
+)
+from tensorflow.keras import backend as K
+from tensorflow.keras.layers import InputSpec
+from typeguard import typechecked
+
+from tensorflow_addons.utils import types
+
+
+def _scale_noise(x):
+ return tf.sign(x) * tf.sqrt(tf.abs(x))
+
+
+@tf.keras.utils.register_keras_serializable(package="Addons")
+class NoisyDense(tf.keras.layers.Dense):
+ r"""Noisy dense layer that injects random noise to the weights of dense layer.
+
+ Noisy dense layers are fully connected layers whose weights and biases are
+ augmented by factorised Gaussian noise. The factorised Gaussian noise is
+ controlled through gradient descent by a second weights layer.
+
+ A `NoisyDense` layer implements the operation:
+ $$
+ \mathrm{NoisyDense}(x) =
+ \mathrm{activation}(\mathrm{dot}(x, \mu + (\sigma \cdot \epsilon))
+ + \mathrm{bias})
+ $$
+ where $\mu$ is the standard weights layer, $\epsilon$ is the factorised
+ Gaussian noise, and $\sigma$ is a second weights layer which controls
+ $\epsilon$.
+
+ Note: bias only added if `use_bias` is `True`.
+
+ Example:
+
+ >>> # Create a `Sequential` model and add a NoisyDense
+ >>> # layer as the first layer.
+ >>> model = tf.keras.models.Sequential()
+ >>> model.add(tf.keras.Input(shape=(16,)))
+ >>> model.add(NoisyDense(32, activation='relu'))
+ >>> # Now the model will take as input arrays of shape (None, 16)
+ >>> # and output arrays of shape (None, 32).
+ >>> # Note that after the first layer, you don't need to specify
+ >>> # the size of the input anymore:
+ >>> model.add(NoisyDense(32))
+ >>> model.output_shape
+ (None, 32)
+
+ Arguments:
+ units: Positive integer, dimensionality of the output space.
+ sigma: A float between 0-1 used as a standard deviation figure and is
+ applied to the gaussian noise layer (`sigma_kernel` and `sigma_bias`).
+ activation: Activation function to use.
+ If you don't specify anything, no activation is applied
+ (ie. "linear" activation: `a(x) = x`).
+ use_bias: Boolean, whether the layer uses a bias vector.
+ kernel_regularizer: Regularizer function applied to
+ the `kernel` weights matrix.
+ bias_regularizer: Regularizer function applied to the bias vector.
+ activity_regularizer: Regularizer function applied to
+ the output of the layer (its "activation").
+ kernel_constraint: Constraint function applied to
+ the `kernel` weights matrix.
+ bias_constraint: Constraint function applied to the bias vector.
+
+ Input shape:
+ N-D tensor with shape: `(batch_size, ..., input_dim)`.
+ The most common situation would be
+ a 2D input with shape `(batch_size, input_dim)`.
+
+ Output shape:
+ N-D tensor with shape: `(batch_size, ..., units)`.
+ For instance, for a 2D input with shape `(batch_size, input_dim)`,
+ the output would have shape `(batch_size, units)`.
+
+ References:
+ - [Noisy Networks for Explanation](https://arxiv.org/pdf/1706.10295.pdf)
+ """
+
+ @typechecked
+ def __init__(
+ self,
+ units: int,
+ sigma: float = 0.5,
+ activation: types.Activation = None,
+ use_bias: bool = True,
+ kernel_regularizer: types.Regularizer = None,
+ bias_regularizer: types.Regularizer = None,
+ activity_regularizer: types.Regularizer = None,
+ kernel_constraint: types.Constraint = None,
+ bias_constraint: types.Constraint = None,
+ **kwargs
+ ):
+ super().__init__(
+ units=units,
+ activation=activation,
+ use_bias=use_bias,
+ kernel_regularizer=kernel_regularizer,
+ bias_regularizer=bias_regularizer,
+ activity_regularizer=activity_regularizer,
+ kernel_constraint=kernel_constraint,
+ bias_constraint=bias_constraint,
+ **kwargs,
+ )
+ delattr(self, "kernel_initializer")
+ delattr(self, "bias_initializer")
+ self.sigma = sigma
+
+ def build(self, input_shape):
+ # Make sure dtype is correct
+ dtype = tf.dtypes.as_dtype(self.dtype or K.floatx())
+ if not (dtype.is_floating or dtype.is_complex):
+ raise TypeError(
+ "Unable to build `Dense` layer with non-floating point "
+ "dtype %s" % (dtype,)
+ )
+
+ input_shape = tf.TensorShape(input_shape)
+ self.last_dim = tf.compat.dimension_value(input_shape[-1])
+ sqrt_dim = self.last_dim ** (1 / 2)
+ if self.last_dim is None:
+ raise ValueError(
+ "The last dimension of the inputs to `Dense` "
+ "should be defined. Found `None`."
+ )
+ self.input_spec = InputSpec(min_ndim=2, axes={-1: self.last_dim})
+
+ sigma_init = initializers.Constant(value=self.sigma / sqrt_dim)
+ mu_init = initializers.RandomUniform(minval=-1 / sqrt_dim, maxval=1 / sqrt_dim)
+
+ # Learnable parameters
+ self.sigma_kernel = self.add_weight(
+ "sigma_kernel",
+ shape=[self.last_dim, self.units],
+ initializer=sigma_init,
+ regularizer=self.kernel_regularizer,
+ constraint=self.kernel_constraint,
+ dtype=self.dtype,
+ trainable=True,
+ )
+
+ self.mu_kernel = self.add_weight(
+ "mu_kernel",
+ shape=[self.last_dim, self.units],
+ initializer=mu_init,
+ regularizer=self.kernel_regularizer,
+ constraint=self.kernel_constraint,
+ dtype=self.dtype,
+ trainable=True,
+ )
+
+ if self.use_bias:
+ self.sigma_bias = self.add_weight(
+ "sigma_bias",
+ shape=[
+ self.units,
+ ],
+ initializer=sigma_init,
+ regularizer=self.bias_regularizer,
+ constraint=self.bias_constraint,
+ dtype=self.dtype,
+ trainable=True,
+ )
+
+ self.mu_bias = self.add_weight(
+ "mu_bias",
+ shape=[
+ self.units,
+ ],
+ initializer=mu_init,
+ regularizer=self.bias_regularizer,
+ constraint=self.bias_constraint,
+ dtype=self.dtype,
+ trainable=True,
+ )
+ else:
+ self.sigma_bias = None
+ self.mu_bias = None
+ self._reset_noise()
+ self.built = True
+
+ @property
+ def kernel(self):
+ return self.mu_kernel + (self.sigma_kernel * self.eps_kernel)
+
+ @property
+ def bias(self):
+ if self.use_bias:
+ return self.mu_bias + (self.sigma_bias * self.eps_bias)
+
+ def _reset_noise(self):
+ """Create the factorised Gaussian noise."""
+
+ dtype = self._compute_dtype_object
+
+ # Generate random noise
+ eps_i = tf.random.normal([self.last_dim, self.units], dtype=dtype)
+ eps_j = tf.random.normal(
+ [
+ self.units,
+ ],
+ dtype=dtype,
+ )
+
+ # Scale the random noise
+ self.eps_kernel = _scale_noise(eps_i) * _scale_noise(eps_j)
+ self.eps_bias = _scale_noise(eps_j)
+
+ def _remove_noise(self):
+ """Remove the factorised Gaussian noise."""
+
+ dtype = self._compute_dtype_object
+ self.eps_kernel = tf.zeros([self.last_dim, self.units], dtype=dtype)
+ self.eps_bias = tf.zeros([self.units], dtype=dtype)
+
+ def call(self, inputs, reset_noise=True, remove_noise=False):
+ # Generate fixed parameters added as the noise
+ if remove_noise:
+ self._remove_noise()
+ elif reset_noise:
+ self._reset_noise()
+
+ # TODO(WindQAQ): Replace this with `dense()` once public.
+ return super().call(inputs)
+
+ def get_config(self):
+ # TODO(WindQAQ): Get rid of this hacky way.
+ config = super(tf.keras.layers.Dense, self).get_config()
+ config.update(
+ {
+ "units": self.units,
+ "sigma": self.sigma,
+ "activation": activations.serialize(self.activation),
+ "use_bias": self.use_bias,
+ "kernel_regularizer": regularizers.serialize(self.kernel_regularizer),
+ "bias_regularizer": regularizers.serialize(self.bias_regularizer),
+ "activity_regularizer": regularizers.serialize(
+ self.activity_regularizer
+ ),
+ "kernel_constraint": constraints.serialize(self.kernel_constraint),
+ "bias_constraint": constraints.serialize(self.bias_constraint),
+ }
+ )
+ return config
diff --git a/tensorflow_addons/layers/normalizations.py b/tensorflow_addons/layers/normalizations.py
index 8fe2910058..8a1d6c9b3b 100644
--- a/tensorflow_addons/layers/normalizations.py
+++ b/tensorflow_addons/layers/normalizations.py
@@ -125,7 +125,11 @@ def call(self, inputs):
normalized_inputs = self._apply_normalization(reshaped_inputs, input_shape)
- outputs = tf.reshape(normalized_inputs, tensor_input_shape)
+ is_instance_norm = (input_shape[self.axis] // self.groups) == 1
+ if not is_instance_norm:
+ outputs = tf.reshape(normalized_inputs, tensor_input_shape)
+ else:
+ outputs = normalized_inputs
return outputs
@@ -156,17 +160,25 @@ def compute_output_shape(self, input_shape):
def _reshape_into_groups(self, inputs, input_shape, tensor_input_shape):
group_shape = [tensor_input_shape[i] for i in range(len(input_shape))]
- group_shape[self.axis] = input_shape[self.axis] // self.groups
- group_shape.insert(self.axis, self.groups)
- group_shape = tf.stack(group_shape)
- reshaped_inputs = tf.reshape(inputs, group_shape)
- return reshaped_inputs, group_shape
+ is_instance_norm = (input_shape[self.axis] // self.groups) == 1
+ if not is_instance_norm:
+ group_shape[self.axis] = input_shape[self.axis] // self.groups
+ group_shape.insert(self.axis, self.groups)
+ group_shape = tf.stack(group_shape)
+ reshaped_inputs = tf.reshape(inputs, group_shape)
+ return reshaped_inputs, group_shape
+ else:
+ return inputs, group_shape
def _apply_normalization(self, reshaped_inputs, input_shape):
group_shape = tf.keras.backend.int_shape(reshaped_inputs)
group_reduction_axes = list(range(1, len(group_shape)))
- axis = -2 if self.axis == -1 else self.axis - 1
+ is_instance_norm = (input_shape[self.axis] // self.groups) == 1
+ if not is_instance_norm:
+ axis = -2 if self.axis == -1 else self.axis - 1
+ else:
+ axis = -1 if self.axis == -1 else self.axis - 1
group_reduction_axes.pop(axis)
mean, variance = tf.nn.moments(
@@ -274,8 +286,12 @@ def _add_beta_weight(self, input_shape):
def _create_broadcast_shape(self, input_shape):
broadcast_shape = [1] * len(input_shape)
- broadcast_shape[self.axis] = input_shape[self.axis] // self.groups
- broadcast_shape.insert(self.axis, self.groups)
+ is_instance_norm = (input_shape[self.axis] // self.groups) == 1
+ if not is_instance_norm:
+ broadcast_shape[self.axis] = input_shape[self.axis] // self.groups
+ broadcast_shape.insert(self.axis, self.groups)
+ else:
+ broadcast_shape[self.axis] = self.groups
return broadcast_shape
diff --git a/tensorflow_addons/layers/stochastic_depth.py b/tensorflow_addons/layers/stochastic_depth.py
new file mode 100644
index 0000000000..3cf0df4f8c
--- /dev/null
+++ b/tensorflow_addons/layers/stochastic_depth.py
@@ -0,0 +1,88 @@
+import tensorflow as tf
+from typeguard import typechecked
+
+
+@tf.keras.utils.register_keras_serializable(package="Addons")
+class StochasticDepth(tf.keras.layers.Layer):
+ """Stochastic Depth layer.
+
+ Implements Stochastic Depth as described in
+ [Deep Networks with Stochastic Depth](https://arxiv.org/abs/1603.09382), to randomly drop residual branches
+ in residual architectures.
+
+ Usage:
+ Residual architectures with fixed depth, use residual branches that are merged back into the main network
+ by adding the residual branch back to the input:
+
+ >>> input = np.ones((1, 3, 3, 1), dtype = np.float32)
+ >>> residual = tf.keras.layers.Conv2D(1, 1)(input)
+ >>> output = tf.keras.layers.Add()([input, residual])
+ >>> output.shape
+ TensorShape([1, 3, 3, 1])
+
+ StochasticDepth acts as a drop-in replacement for the addition:
+
+ >>> input = np.ones((1, 3, 3, 1), dtype = np.float32)
+ >>> residual = tf.keras.layers.Conv2D(1, 1)(input)
+ >>> output = tfa.layers.StochasticDepth()([input, residual])
+ >>> output.shape
+ TensorShape([1, 3, 3, 1])
+
+ At train time, StochasticDepth returns:
+
+ $$
+ x[0] + b_l * x[1],
+ $$
+
+ where $b_l$ is a random Bernoulli variable with probability $P(b_l = 1) = p_l$
+
+ At test time, StochasticDepth rescales the activations of the residual branch based on the survival probability ($p_l$):
+
+ $$
+ x[0] + p_l * x[1]
+ $$
+
+ Arguments:
+ survival_probability: float, the probability of the residual branch being kept.
+
+ Call Arguments:
+ inputs: List of `[shortcut, residual]` where `shortcut`, and `residual` are tensors of equal shape.
+
+ Output shape:
+ Equal to the shape of inputs `shortcut`, and `residual`
+ """
+
+ @typechecked
+ def __init__(self, survival_probability: float = 0.5, **kwargs):
+ super().__init__(**kwargs)
+
+ self.survival_probability = survival_probability
+
+ def call(self, x, training=None):
+ if not isinstance(x, list) or len(x) != 2:
+ raise ValueError("input must be a list of length 2.")
+
+ shortcut, residual = x
+
+ # Random bernoulli variable indicating whether the branch should be kept or not or not
+ b_l = tf.keras.backend.random_bernoulli([], p=self.survival_probability)
+
+ def _call_train():
+ return shortcut + b_l * residual
+
+ def _call_test():
+ return shortcut + self.survival_probability * residual
+
+ return tf.keras.backend.in_train_phase(
+ _call_train, _call_test, training=training
+ )
+
+ def compute_output_shape(self, input_shape):
+ return input_shape[0]
+
+ def get_config(self):
+ base_config = super().get_config()
+
+ config = {"survival_probability": self.survival_probability}
+
+ return {**base_config, **config}
diff --git a/tensorflow_addons/layers/tests/noisy_dense_test.py b/tensorflow_addons/layers/tests/noisy_dense_test.py
new file mode 100644
index 0000000000..9f76307518
--- /dev/null
+++ b/tensorflow_addons/layers/tests/noisy_dense_test.py
@@ -0,0 +1,141 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests NoisyDense layer."""
+
+
+import pytest
+import numpy as np
+
+import tensorflow as tf
+from tensorflow import keras
+from tensorflow.keras.mixed_precision.experimental import Policy
+
+from tensorflow_addons.utils import test_utils
+from tensorflow_addons.layers.noisy_dense import NoisyDense
+
+
+@pytest.mark.parametrize(
+ "input_shape", [(3, 2), (3, 4, 2), (None, None, 2), (3, 4, 5, 2)]
+)
+def test_noisy_dense(input_shape):
+ test_utils.layer_test(NoisyDense, kwargs={"units": 3}, input_shape=input_shape)
+
+
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+@pytest.mark.parametrize("dtype", ["float16", "float32", "float64"])
+def test_noisy_dense_dtype(dtype):
+ inputs = tf.convert_to_tensor(
+ np.random.randint(low=0, high=7, size=(2, 2)), dtype=dtype
+ )
+ layer = NoisyDense(5, dtype=dtype, name="noisy_dense_" + dtype)
+ outputs = layer(inputs)
+ np.testing.assert_array_equal(outputs.dtype, dtype)
+
+
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+def test_noisy_dense_with_policy():
+ inputs = tf.convert_to_tensor(np.random.randint(low=0, high=7, size=(2, 2)))
+ layer = NoisyDense(5, dtype=Policy("mixed_float16"), name="noisy_dense_policy")
+ outputs = layer(inputs)
+ output_signature = layer.compute_output_signature(
+ tf.TensorSpec(dtype="float16", shape=(2, 2))
+ )
+ np.testing.assert_array_equal(output_signature.dtype, tf.dtypes.float16)
+ np.testing.assert_array_equal(output_signature.shape, (2, 5))
+ np.testing.assert_array_equal(outputs.dtype, "float16")
+ np.testing.assert_array_equal(layer.mu_kernel.dtype, "float32")
+ np.testing.assert_array_equal(layer.sigma_kernel.dtype, "float32")
+
+
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+def test_noisy_dense_regularization():
+ layer = NoisyDense(
+ 3,
+ kernel_regularizer=keras.regularizers.l1(0.01),
+ bias_regularizer="l1",
+ activity_regularizer="l2",
+ name="noisy_dense_reg",
+ )
+ layer(keras.backend.variable(np.ones((2, 4))))
+ np.testing.assert_array_equal(5, len(layer.losses))
+
+
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+def test_noisy_dense_constraints():
+ k_constraint = keras.constraints.max_norm(0.01)
+ b_constraint = keras.constraints.max_norm(0.01)
+ layer = NoisyDense(
+ 3,
+ kernel_constraint=k_constraint,
+ bias_constraint=b_constraint,
+ name="noisy_dense_constriants",
+ )
+ layer(keras.backend.variable(np.ones((2, 4))))
+ np.testing.assert_array_equal(layer.mu_kernel.constraint, k_constraint)
+ np.testing.assert_array_equal(layer.sigma_kernel.constraint, k_constraint)
+ np.testing.assert_array_equal(layer.mu_bias.constraint, b_constraint)
+ np.testing.assert_array_equal(layer.sigma_bias.constraint, b_constraint)
+
+
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+def test_noisy_dense_automatic_reset_noise():
+ inputs = tf.convert_to_tensor(np.random.randint(low=0, high=7, size=(2, 2)))
+ layer = NoisyDense(5, name="noise_dense_auto_reset_noise")
+ layer(inputs)
+ initial_eps_kernel = layer.eps_kernel
+ initial_eps_bias = layer.eps_bias
+ layer(inputs)
+ new_eps_kernel = layer.eps_kernel
+ new_eps_bias = layer.eps_bias
+ np.testing.assert_raises(
+ AssertionError,
+ np.testing.assert_array_equal,
+ initial_eps_kernel,
+ new_eps_kernel,
+ )
+ np.testing.assert_raises(
+ AssertionError,
+ np.testing.assert_array_equal,
+ initial_eps_bias,
+ new_eps_bias,
+ )
+
+
+@pytest.mark.usefixtures("maybe_run_functions_eagerly")
+def test_noisy_dense_remove_noise():
+ inputs = tf.convert_to_tensor(np.random.randint(low=0, high=7, size=(2, 2)))
+ layer = NoisyDense(5, name="noise_dense_manual_reset_noise")
+ layer(inputs)
+ initial_eps_kernel = layer.eps_kernel
+ initial_eps_bias = layer.eps_bias
+ layer(inputs, reset_noise=False, remove_noise=True)
+ new_eps_kernel = layer.eps_kernel
+ new_eps_bias = layer.eps_bias
+ kernel_zeros = tf.zeros(initial_eps_kernel.shape, dtype=initial_eps_kernel.dtype)
+ bias_zeros = tf.zeros(initial_eps_bias.shape, dtype=initial_eps_kernel.dtype)
+ np.testing.assert_raises(
+ AssertionError,
+ np.testing.assert_array_equal,
+ initial_eps_kernel,
+ new_eps_kernel,
+ )
+ np.testing.assert_raises(
+ AssertionError,
+ np.testing.assert_array_equal,
+ initial_eps_bias,
+ new_eps_bias,
+ )
+ np.testing.assert_array_equal(kernel_zeros, new_eps_kernel)
+ np.testing.assert_array_equal(bias_zeros, new_eps_bias)
diff --git a/tensorflow_addons/layers/tests/normalizations_test.py b/tensorflow_addons/layers/tests/normalizations_test.py
index 617dc27ab6..a15817eca8 100644
--- a/tensorflow_addons/layers/tests/normalizations_test.py
+++ b/tensorflow_addons/layers/tests/normalizations_test.py
@@ -80,7 +80,7 @@ def run_reshape_test(axis, group, input_shape, expected_shape):
run_reshape_test(1, 2, input_shape, expected_shape)
input_shape = (10, 10, 10)
- expected_shape = [10, 10, 1, 10]
+ expected_shape = [10, 10, 10]
run_reshape_test(1, -1, input_shape, expected_shape)
input_shape = (10, 10, 10)
@@ -122,17 +122,26 @@ def _test_specific_layer(inputs, axis, groups, center, scale):
outputs = model.predict(inputs, steps=1)
assert not np.isnan(outputs).any()
+ is_instance_norm = False
# Create shapes
if groups == -1:
groups = input_shape[axis]
+ if (input_shape[axis] // groups) == 1:
+ is_instance_norm = True
np_inputs = inputs
reshaped_dims = list(np_inputs.shape)
- reshaped_dims[axis] = reshaped_dims[axis] // groups
- reshaped_dims.insert(axis, groups)
- reshaped_inputs = np.reshape(np_inputs, tuple(reshaped_dims))
+ if not is_instance_norm:
+ reshaped_dims[axis] = reshaped_dims[axis] // groups
+ reshaped_dims.insert(axis, groups)
+ reshaped_inputs = np.reshape(np_inputs, tuple(reshaped_dims))
+ else:
+ reshaped_inputs = np_inputs
group_reduction_axes = list(range(1, len(reshaped_dims)))
- axis = -2 if axis == -1 else axis - 1
+ if not is_instance_norm:
+ axis = -2 if axis == -1 else axis - 1
+ else:
+ axis = -1 if axis == -1 else axis - 1
group_reduction_axes.pop(axis)
# Calculate mean and variance
diff --git a/tensorflow_addons/layers/tests/stochastic_depth_test.py b/tensorflow_addons/layers/tests/stochastic_depth_test.py
new file mode 100644
index 0000000000..1122016f57
--- /dev/null
+++ b/tensorflow_addons/layers/tests/stochastic_depth_test.py
@@ -0,0 +1,58 @@
+import pytest
+import numpy as np
+import tensorflow as tf
+
+from tensorflow_addons.layers.stochastic_depth import StochasticDepth
+from tensorflow_addons.utils import test_utils
+
+_KEEP_SEED = 1111
+_DROP_SEED = 2222
+
+
+@pytest.mark.parametrize("seed", [_KEEP_SEED, _DROP_SEED])
+@pytest.mark.parametrize("training", [True, False])
+def stochastic_depth_test(seed, training):
+ np.random.seed(seed)
+ tf.random.set_seed(seed)
+
+ survival_probability = 0.5
+
+ shortcut = np.asarray([[0.2, 0.1, 0.4]]).astype(np.float32)
+ residual = np.asarray([[0.2, 0.4, 0.5]]).astype(np.float32)
+
+ if training:
+ if seed == _KEEP_SEED:
+ # shortcut + residual
+ expected_output = np.asarray([[0.4, 0.5, 0.9]]).astype(np.float32)
+ elif seed == _DROP_SEED:
+ # shortcut
+ expected_output = np.asarray([[0.2, 0.1, 0.4]]).astype(np.float32)
+ else:
+ # shortcut + p_l * residual
+ expected_output = np.asarray([[0.3, 0.3, 0.65]]).astype(np.float32)
+
+ test_utils.layer_test(
+ StochasticDepth,
+ kwargs={"survival_probability": survival_probability},
+ input_data=[shortcut, residual],
+ expected_output=expected_output,
+ )
+
+
+@pytest.mark.usefixtures("run_with_mixed_precision_policy")
+def test_with_mixed_precision_policy():
+ policy = tf.keras.mixed_precision.experimental.global_policy()
+
+ shortcut = np.asarray([[0.2, 0.1, 0.4]])
+ residual = np.asarray([[0.2, 0.4, 0.5]])
+
+ output = StochasticDepth()([shortcut, residual])
+
+ assert output.dtype == policy.compute_dtype
+
+
+def test_serialization():
+ stoch_depth = StochasticDepth(survival_probability=0.5)
+ serialized_stoch_depth = tf.keras.layers.serialize(stoch_depth)
+ new_layer = tf.keras.layers.deserialize(serialized_stoch_depth)
+ assert stoch_depth.get_config() == new_layer.get_config()
diff --git a/tensorflow_addons/losses/contrastive.py b/tensorflow_addons/losses/contrastive.py
index c6a9e9f826..7f26d51ee9 100644
--- a/tensorflow_addons/losses/contrastive.py
+++ b/tensorflow_addons/losses/contrastive.py
@@ -15,10 +15,10 @@
"""Implements contrastive loss."""
import tensorflow as tf
+from typeguard import typechecked
from tensorflow_addons.utils.keras_utils import LossFunctionWrapper
from tensorflow_addons.utils.types import TensorLike, Number
-from typeguard import typechecked
@tf.keras.utils.register_keras_serializable(package="Addons")
@@ -36,10 +36,19 @@ def contrastive_loss(
`a` and `b` with shape `[batch_size, hidden_size]` can be computed
as follows:
- ```python
- # y_pred = \sqrt (\sum_i (a[:, i] - b[:, i])^2)
- y_pred = tf.linalg.norm(a - b, axis=1)
- ```
+ >>> a = tf.constant([[1, 2],
+ ... [3, 4],
+ ... [5, 6]], dtype=tf.float16)
+ >>> b = tf.constant([[5, 9],
+ ... [3, 6],
+ ... [1, 8]], dtype=tf.float16)
+ >>> y_pred = tf.linalg.norm(a - b, axis=1)
+ >>> y_pred
+
+
+ <... Note: constants a & b have been used purely for
+ example purposes and have no significant value ...>
See: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
@@ -79,10 +88,17 @@ class ContrastiveLoss(LossFunctionWrapper):
`a` and `b` with shape `[batch_size, hidden_size]` can be computed
as follows:
- ```python
- # y_pred = \sqrt (\sum_i (a[:, i] - b[:, i])^2)
- y_pred = tf.linalg.norm(a - b, axis=1)
- ```
+ >>> a = tf.constant([[1, 2],
+ ... [3, 4],[5, 6]], dtype=tf.float16)
+ >>> b = tf.constant([[5, 9],
+ ... [3, 6],[1, 8]], dtype=tf.float16)
+ >>> y_pred = tf.linalg.norm(a - b, axis=1)
+ >>> y_pred
+
+
+ <... Note: constants a & b have been used purely for
+ example purposes and have no significant value ...>
Args:
margin: `Float`, margin term in the loss definition.
diff --git a/tensorflow_addons/losses/focal_loss.py b/tensorflow_addons/losses/focal_loss.py
index 8f29951277..cf74dc7ccf 100644
--- a/tensorflow_addons/losses/focal_loss.py
+++ b/tensorflow_addons/losses/focal_loss.py
@@ -16,10 +16,10 @@
import tensorflow as tf
import tensorflow.keras.backend as K
+from typeguard import typechecked
from tensorflow_addons.utils.keras_utils import LossFunctionWrapper
from tensorflow_addons.utils.types import FloatTensorLike, TensorLike
-from typeguard import typechecked
@tf.keras.utils.register_keras_serializable(package="Addons")
@@ -37,22 +37,17 @@ class SigmoidFocalCrossEntropy(LossFunctionWrapper):
Usage:
- ```python
- fl = tfa.losses.SigmoidFocalCrossEntropy()
- loss = fl(
- y_true = [[1.0], [1.0], [0.0]],
- y_pred = [[0.97], [0.91], [0.03]])
- print('Loss: ', loss.numpy()) # Loss: [6.8532745e-06,
- 1.9097870e-04,
- 2.0559824e-05]
- ```
+ >>> fl = tfa.losses.SigmoidFocalCrossEntropy()
+ >>> loss = fl(
+ ... y_true = [[1.0], [1.0], [0.0]],y_pred = [[0.97], [0.91], [0.03]])
+ >>> loss
+
Usage with `tf.keras` API:
- ```python
- model = tf.keras.Model(inputs, outputs)
- model.compile('sgd', loss=tfa.losses.SigmoidFocalCrossEntropy())
- ```
+ >>> model = tf.keras.Model()
+ >>> model.compile('sgd', loss=tfa.losses.SigmoidFocalCrossEntropy())
Args:
alpha: balancing factor, default value is 0.25.
diff --git a/tensorflow_addons/losses/giou_loss.py b/tensorflow_addons/losses/giou_loss.py
index e789fcacb1..b6e2ad6568 100644
--- a/tensorflow_addons/losses/giou_loss.py
+++ b/tensorflow_addons/losses/giou_loss.py
@@ -14,11 +14,13 @@
# ==============================================================================
"""Implements GIoU loss."""
+from typing import Optional
+
import tensorflow as tf
+from typeguard import typechecked
+
from tensorflow_addons.utils.keras_utils import LossFunctionWrapper
from tensorflow_addons.utils.types import TensorLike
-from typing import Optional
-from typeguard import typechecked
@tf.keras.utils.register_keras_serializable(package="Addons")
@@ -33,20 +35,17 @@ class GIoULoss(LossFunctionWrapper):
Usage:
- ```python
- gl = tfa.losses.GIoULoss()
- boxes1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]])
- boxes2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0]])
- loss = gl(boxes1, boxes2)
- print('Loss: ', loss.numpy()) # Loss: [1.07500000298023224, 1.9333333373069763]
- ```
+ >>> gl = tfa.losses.GIoULoss()
+ >>> boxes1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]])
+ >>> boxes2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0]])
+ >>> loss = gl(boxes1, boxes2)
+ >>> loss
+
Usage with `tf.keras` API:
- ```python
- model = tf.keras.Model(inputs, outputs)
- model.compile('sgd', loss=tfa.losses.GIoULoss())
- ```
+ >>> model = tf.keras.Model()
+ >>> model.compile('sgd', loss=tfa.losses.GIoULoss())
Args:
mode: one of ['giou', 'iou'], decided to calculate GIoU or IoU loss.
diff --git a/tensorflow_addons/losses/kappa_loss.py b/tensorflow_addons/losses/kappa_loss.py
index c041cb8b01..717267d2e3 100644
--- a/tensorflow_addons/losses/kappa_loss.py
+++ b/tensorflow_addons/losses/kappa_loss.py
@@ -37,24 +37,24 @@ class WeightedKappaLoss(tf.keras.losses.Loss):
Usage:
- ```python
- kappa_loss = WeightedKappaLoss(num_classes=4)
- y_true = tf.constant([[0, 0, 1, 0], [0, 1, 0, 0],
- [1, 0, 0, 0], [0, 0, 0, 1]])
- y_pred = tf.constant([[0.1, 0.2, 0.6, 0.1], [0.1, 0.5, 0.3, 0.1],
- [0.8, 0.05, 0.05, 0.1], [0.01, 0.09, 0.1, 0.8]])
- loss = kappa_loss(y_true, y_pred)
- print('Loss: ', loss.numpy()) # Loss: -1.1611923
- ```
+ >>> kappa_loss = tfa.losses.WeightedKappaLoss(num_classes=4)
+ >>> y_true = tf.constant([[0, 0, 1, 0], [0, 1, 0, 0],
+ ... [1, 0, 0, 0], [0, 0, 0, 1]])
+ >>> y_pred = tf.constant([[0.1, 0.2, 0.6, 0.1], [0.1, 0.5, 0.3, 0.1],
+ ... [0.8, 0.05, 0.05, 0.1], [0.01, 0.09, 0.1, 0.8]])
+ >>> loss = kappa_loss(y_true, y_pred)
+ >>> loss
+
Usage with `tf.keras` API:
- ```python
- # outputs should be softmax results
- # if you want to weight the samples, just multiply the outputs
- # by the sample weight.
- model = tf.keras.Model(inputs, outputs)
- model.compile('sgd', loss=tfa.losses.WeightedKappa(num_classes=4))
- ```
+
+ >>> model = tf.keras.Model()
+ >>> model.compile('sgd', loss=tfa.losses.WeightedKappaLoss(num_classes=4))
+
+ <... outputs should be softmax results
+ if you want to weight the samples, just multiply the outputs
+ by the sample weight ...>
+
"""
@typechecked
diff --git a/tensorflow_addons/losses/npairs.py b/tensorflow_addons/losses/npairs.py
index 1693123505..c7acc64992 100644
--- a/tensorflow_addons/losses/npairs.py
+++ b/tensorflow_addons/losses/npairs.py
@@ -15,9 +15,9 @@
"""Implements npairs loss."""
import tensorflow as tf
+from typeguard import typechecked
from tensorflow_addons.utils.types import TensorLike
-from typeguard import typechecked
@tf.keras.utils.register_keras_serializable(package="Addons")
@@ -33,10 +33,21 @@ def npairs_loss(y_true: TensorLike, y_pred: TensorLike) -> tf.Tensor:
The similarity matrix `y_pred` between two embedding matrices `a` and `b`
with shape `[batch_size, hidden_size]` can be computed as follows:
- ```python
- # y_pred = a * b^T
- y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
- ```
+ >>> a = tf.constant([[1, 2],
+ ... [3, 4],
+ ... [5, 6]], dtype=tf.float16)
+ >>> b = tf.constant([[5, 9],
+ ... [3, 6],
+ ... [1, 8]], dtype=tf.float16)
+ >>> y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
+ >>> y_pred
+
+
+ <... Note: constants a & b have been used purely for
+ example purposes and have no significant value ...>
See: http://www.nec-labs.com/uploads/images/Department-Images/MediaAnalytics/papers/nips16_npairmetriclearning.pdf
@@ -89,10 +100,21 @@ def npairs_multilabel_loss(y_true: TensorLike, y_pred: TensorLike) -> tf.Tensor:
The similarity matrix `y_pred` between two embedding matrices `a` and `b`
with shape `[batch_size, hidden_size]` can be computed as follows:
- ```python
- # y_pred = a * b^T
- y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
- ```
+ >>> a = tf.constant([[1, 2],
+ ... [3, 4],
+ ... [5, 6]], dtype=tf.float16)
+ >>> b = tf.constant([[5, 9],
+ ... [3, 6],
+ ... [1, 8]], dtype=tf.float16)
+ >>> y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
+ >>> y_pred
+
+
+ <... Note: constants a & b have been used purely for
+ example purposes and have no significant value ...>
See: http://www.nec-labs.com/uploads/images/Department-Images/MediaAnalytics/papers/nips16_npairmetriclearning.pdf
@@ -139,10 +161,21 @@ class NpairsLoss(tf.keras.losses.Loss):
The similarity matrix `y_pred` between two embedding matrices `a` and `b`
with shape `[batch_size, hidden_size]` can be computed as follows:
- ```python
- # y_pred = a * b^T
- y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
- ```
+ >>> a = tf.constant([[1, 2],
+ ... [3, 4],
+ ... [5, 6]], dtype=tf.float16)
+ >>> b = tf.constant([[5, 9],
+ ... [3, 6],
+ ... [1, 8]], dtype=tf.float16)
+ >>> y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
+ >>> y_pred
+
+
+ <... Note: constants a & b have been used purely for
+ example purposes and have no significant value ...>
See: http://www.nec-labs.com/uploads/images/Department-Images/MediaAnalytics/papers/nips16_npairmetriclearning.pdf
@@ -184,10 +217,21 @@ class NpairsMultilabelLoss(tf.keras.losses.Loss):
The similarity matrix `y_pred` between two embedding matrices `a` and `b`
with shape `[batch_size, hidden_size]` can be computed as follows:
- ```python
- # y_pred = a * b^T
- y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
- ```
+ >>> a = tf.constant([[1, 2],
+ ... [3, 4],
+ ... [5, 6]], dtype=tf.float16)
+ >>> b = tf.constant([[5, 9],
+ ... [3, 6],
+ ... [1, 8]], dtype=tf.float16)
+ >>> y_pred = tf.matmul(a, b, transpose_a=False, transpose_b=True)
+ >>> y_pred
+
+
+ <... Note: constants a & b have been used purely for
+ example purposes and have no significant value ...>
See: http://www.nec-labs.com/uploads/images/Department-Images/MediaAnalytics/papers/nips16_npairmetriclearning.pdf
diff --git a/tensorflow_addons/losses/quantiles.py b/tensorflow_addons/losses/quantiles.py
index 2aad531294..513ffd2398 100644
--- a/tensorflow_addons/losses/quantiles.py
+++ b/tensorflow_addons/losses/quantiles.py
@@ -35,14 +35,11 @@ def pinball_loss(
See: https://en.wikipedia.org/wiki/Quantile_regression
Usage:
- ```python
- loss = pinball_loss([0., 0., 1., 1.], [1., 1., 1., 0.], tau=.1)
- # loss = max(0.1 * (y_true - y_pred), (0.1 - 1) * (y_true - y_pred))
- # = (0.9 + 0.9 + 0 + 0.1) / 4
-
- print('Loss: ', loss.numpy()) # Loss: 0.475
- ```
+ >>> loss = tfa.losses.pinball_loss([0., 0., 1., 1.],
+ ... [1., 1., 1., 0.], tau=.1)
+ >>> loss
+
Args:
y_true: Ground truth values. shape = `[batch_size, d0, .. dN]`
@@ -84,22 +81,16 @@ class PinballLoss(LossFunctionWrapper):
See: https://en.wikipedia.org/wiki/Quantile_regression
Usage:
- ```python
- pinball = tfa.losses.PinballLoss(tau=.1)
- loss = pinball([0., 0., 1., 1.], [1., 1., 1., 0.])
-
- # loss = max(0.1 * (y_true - y_pred), (0.1 - 1) * (y_true - y_pred))
- # = (0.9 + 0.9 + 0 + 0.1) / 4
- print('Loss: ', loss.numpy()) # Loss: 0.475
- ```
+ >>> pinball = tfa.losses.PinballLoss(tau=.1)
+ >>> loss = pinball([0., 0., 1., 1.], [1., 1., 1., 0.])
+ >>> loss
+
Usage with the `tf.keras` API:
- ```python
- model = tf.keras.Model(inputs, outputs)
- model.compile('sgd', loss=tfa.losses.PinballLoss(tau=.1))
- ```
+ >>> model = tf.keras.Model()
+ >>> model.compile('sgd', loss=tfa.losses.PinballLoss(tau=.1))
Args:
tau: (Optional) Float in [0, 1] or a tensor taking values in [0, 1] and
diff --git a/tensorflow_addons/metrics/cohens_kappa.py b/tensorflow_addons/metrics/cohens_kappa.py
index cb473530b7..19f61e61a0 100644
--- a/tensorflow_addons/metrics/cohens_kappa.py
+++ b/tensorflow_addons/metrics/cohens_kappa.py
@@ -38,28 +38,43 @@ class CohenKappa(Metric):
Usage:
- ```python
- actuals = np.array([4, 4, 3, 4, 2, 4, 1, 1], dtype=np.int32)
- preds = np.array([4, 4, 3, 4, 4, 2, 1, 1], dtype=np.int32)
- weights = np.array([1, 1, 2, 5, 10, 2, 3, 3], dtype=np.int32)
-
- m = tfa.metrics.CohenKappa(num_classes=5, sparse_labels=True)
- m.update_state(actuals, preds)
- print('Final result: ', m.result().numpy()) # Result: 0.61904764
-
- # To use this with weights, sample_weight argument can be used.
- m = tfa.metrics.CohenKappa(num_classes=5, sparse_labels=True)
- m.update_state(actuals, preds, sample_weight=weights)
- print('Final result: ', m.result().numpy()) # Result: 0.37209308
- ```
+ >>> actuals = np.array([4, 4, 3, 4, 2, 4, 1, 1], dtype=np.int32)
+ >>> preds = np.array([4, 4, 3, 4, 4, 2, 1, 1], dtype=np.int32)
+ >>> weights = np.array([1, 1, 2, 5, 10, 2, 3, 3], dtype=np.int32)
+
+ >>> metric = tfa.metrics.CohenKappa(num_classes=5, sparse_labels=True)
+ >>> metric.update_state(y_true = actuals, y_pred = preds)
+
+ >>> result = metric(y_true = actuals, y_pred = preds)
+ >>> print('Final result: ', result.numpy())
+ Final result: 0.61904764
+
+ >>> # To use this with weights, sample_weight argument can be used.
+ >>> metric = tfa.metrics.CohenKappa(num_classes=5, sparse_labels=True)
+ >>> metric.update_state(y_true = actuals, y_pred = preds, sample_weight=weights)
+
+ >>> result = metric(y_true = actuals, y_pred = preds)
+ >>> print('Final result: ', result.numpy())
+ Final result: 0.42080373
Usage with tf.keras API:
- ```python
- model = tf.keras.models.Model(inputs, outputs)
- model.add_metric(tfa.metrics.CohenKappa(num_classes=5)(outputs))
- model.compile('sgd', loss='mse')
- ```
+ >>> inputs = tf.keras.Input(shape=(10,))
+ >>> x = tf.keras.layers.Dense(10)(inputs)
+ >>> outputs = tf.keras.layers.Dense(1)(x)
+ >>> model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
+ >>> model.compile('sgd', loss='mse', metrics=[tfa.metrics.CohenKappa(num_classes=3, sparse_labels=True)])
+
"""
@typechecked
diff --git a/tensorflow_addons/metrics/geometric_mean.py b/tensorflow_addons/metrics/geometric_mean.py
index bce8e15509..a123a9f224 100644
--- a/tensorflow_addons/metrics/geometric_mean.py
+++ b/tensorflow_addons/metrics/geometric_mean.py
@@ -35,9 +35,9 @@ class GeometricMean(Metric):
Usage:
- >>> m = tfa.metrics.GeometricMean()
- >>> m.update_state([1, 3, 5, 7, 9])
- >>> m.result().numpy()
+ >>> metric = tfa.metrics.GeometricMean()
+ >>> metric.update_state([1, 3, 5, 7, 9])
+ >>> metric.result().numpy()
3.9362833
"""
diff --git a/tensorflow_addons/metrics/hamming.py b/tensorflow_addons/metrics/hamming.py
index 9702b030ea..a0390f379f 100644
--- a/tensorflow_addons/metrics/hamming.py
+++ b/tensorflow_addons/metrics/hamming.py
@@ -38,14 +38,14 @@ def hamming_distance(actuals: TensorLike, predictions: TensorLike) -> tf.Tensor:
Usage:
- ```python
- actuals = tf.constant([1, 1, 0, 0, 1, 0, 1, 0, 0, 1],
- dtype=tf.int32)
- predictions = tf.constant([1, 0, 0, 0, 1, 0, 0, 1, 0, 1],
- dtype=tf.int32)
- result = hamming_distance(actuals, predictions)
- print('Hamming distance: ', result.numpy())
- ```
+ >>> actuals = tf.constant([1, 1, 0, 0, 1, 0, 1, 0, 0, 1],
+ ... dtype=tf.int32)
+ >>> predictions = tf.constant([1, 0, 0, 0, 1, 0, 0, 1, 0, 1],
+ ... dtype=tf.int32)
+ >>> metric = hamming_distance(actuals, predictions)
+ >>> print('Hamming distance: ', metric.numpy())
+ Hamming distance: 0.3
+
"""
result = tf.not_equal(actuals, predictions)
not_eq = tf.reduce_sum(tf.cast(result, tf.float32))
@@ -84,31 +84,30 @@ def hamming_loss_fn(
Usage:
- ```python
- # multi-class hamming loss
- hl = HammingLoss(mode='multiclass', threshold=0.6)
- actuals = tf.constant([[1, 0, 0, 0],[0, 0, 1, 0],
- [0, 0, 0, 1],[0, 1, 0, 0]],
- dtype=tf.float32)
- predictions = tf.constant([[0.8, 0.1, 0.1, 0],
- [0.2, 0, 0.8, 0],
- [0.05, 0.05, 0.1, 0.8],
- [1, 0, 0, 0]],
- dtype=tf.float32)
- hl.update_state(actuals, predictions)
- print('Hamming loss: ', hl.result().numpy()) # 0.25
-
- # multi-label hamming loss
- hl = HammingLoss(mode='multilabel', threshold=0.8)
- actuals = tf.constant([[1, 0, 1, 0],[0, 1, 0, 1],
- [0, 0, 0,1]], dtype=tf.int32)
- predictions = tf.constant([[0.82, 0.5, 0.90, 0],
- [0, 1, 0.4, 0.98],
- [0.89, 0.79, 0, 0.3]],
- dtype=tf.float32)
- hl.update_state(actuals, predictions)
- print('Hamming loss: ', hl.result().numpy()) # 0.16666667
- ```
+ >>> # multi-class hamming loss
+ >>> hl = HammingLoss(mode='multiclass', threshold=0.6)
+ >>> actuals = tf.constant([[1, 0, 0, 0],[0, 0, 1, 0],
+ ... [0, 0, 0, 1],[0, 1, 0, 0]], dtype=tf.float32)
+ >>> predictions = tf.constant([[0.8, 0.1, 0.1, 0],
+ ... [0.2, 0, 0.8, 0],[0.05, 0.05, 0.1, 0.8],[1, 0, 0, 0]],
+ ... dtype=tf.float32)
+
+ >>> hl.update_state(actuals, predictions)
+
+ >>> # uncomment the line below to see the result
+ >>> print('Hamming loss: ', hl.result().numpy())
+ Hamming loss: 0.25
+ >>> # multi-label hamming loss
+ >>> hl = HammingLoss(mode='multilabel', threshold=0.8)
+ >>> actuals = tf.constant([[1, 0, 1, 0],[0, 1, 0, 1],
+ ... [0, 0, 0,1]], dtype=tf.int32)
+ >>> predictions = tf.constant([[0.82, 0.5, 0.90, 0],
+ ... [0, 1, 0.4, 0.98],[0.89, 0.79, 0, 0.3]],dtype=tf.float32)
+
+ >>> hl.update_state(actuals, predictions)
+
+ >>> print('Hamming loss: ', hl.result().numpy())
+ Hamming loss: 0.16666667
"""
if mode not in ["multiclass", "multilabel"]:
raise TypeError("mode must be either multiclass or multilabel]")
diff --git a/tensorflow_addons/metrics/matthews_correlation_coefficient.py b/tensorflow_addons/metrics/matthews_correlation_coefficient.py
index e6afa53f61..68cc2ff9e9 100644
--- a/tensorflow_addons/metrics/matthews_correlation_coefficient.py
+++ b/tensorflow_addons/metrics/matthews_correlation_coefficient.py
@@ -42,18 +42,18 @@ class MatthewsCorrelationCoefficient(tf.keras.metrics.Metric):
((TP + FP) * (TP + FN) * (TN + FP ) * (TN + FN))^(1/2)
Usage:
- ```python
- actuals = tf.constant([[1.0], [1.0], [1.0], [0.0]],
- dtype=tf.float32)
- preds = tf.constant([[1.0], [0.0], [1.0], [1.0]],
- dtype=tf.float32)
- # Matthews correlation coefficient
- mcc = MatthewsCorrelationCoefficient(num_classes=1)
- mcc.update_state(actuals, preds)
- print('Matthews correlation coefficient is:',
- mcc.result().numpy())
- # Matthews correlation coefficient is : -0.33333334
- ```
+
+ >>> actuals = tf.constant([[1.0], [1.0], [1.0], [0.0]],
+ ... dtype=tf.float32)
+ >>> preds = tf.constant([[1.0], [0.0], [1.0], [1.0]],
+ ... dtype=tf.float32)
+ >>> # Matthews correlation coefficient
+ >>> metric = tfa.metrics.MatthewsCorrelationCoefficient(num_classes=1)
+ >>> metric.update_state(y_true = actuals, y_pred = preds)
+ >>> result = metric(y_true = actuals, y_pred = preds)
+ >>> print('Matthews correlation coefficient is :', result.numpy())
+ Matthews correlation coefficient is : [-0.33333334]
+
"""
@typechecked
diff --git a/tensorflow_addons/metrics/multilabel_confusion_matrix.py b/tensorflow_addons/metrics/multilabel_confusion_matrix.py
index d13a355b33..4a79b341ed 100644
--- a/tensorflow_addons/metrics/multilabel_confusion_matrix.py
+++ b/tensorflow_addons/metrics/multilabel_confusion_matrix.py
@@ -46,30 +46,42 @@ class MultiLabelConfusionMatrix(Metric):
- false negatives for class i in M(1,0)
- true positives for class i in M(1,1)
- ```python
- # multilabel confusion matrix
- y_true = tf.constant([[1, 0, 1], [0, 1, 0]],
- dtype=tf.int32)
- y_pred = tf.constant([[1, 0, 0],[0, 1, 1]],
- dtype=tf.int32)
- output = MultiLabelConfusionMatrix(num_classes=3)
- output.update_state(y_true, y_pred)
- print('Confusion matrix:', output.result().numpy())
-
- # Confusion matrix: [[[1 0] [0 1]] [[1 0] [0 1]]
- [[0 1] [1 0]]]
-
- # if multiclass input is provided
- y_true = tf.constant([[1, 0, 0], [0, 1, 0]],
- dtype=tf.int32)
- y_pred = tf.constant([[1, 0, 0],[0, 0, 1]],
- dtype=tf.int32)
- output = MultiLabelConfusionMatrix(num_classes=3)
- output.update_state(y_true, y_pred)
- print('Confusion matrix:', output.result().numpy())
-
- # Confusion matrix: [[[1 0] [0 1]] [[1 0] [1 0]] [[1 1] [0 0]]]
- ```
+ >>> # multilabel confusion matrix
+ >>> y_true = tf.constant([[1, 0, 1], [0, 1, 0]],
+ ... dtype=tf.int32)
+ >>> y_pred = tf.constant([[1, 0, 0],[0, 1, 1]],
+ ... dtype=tf.int32)
+ >>> metric = tfa.metrics.MultiLabelConfusionMatrix(num_classes=3)
+ >>> metric.update_state(y_true, y_pred)
+ >>> result = metric(y_true, y_pred)
+ >>> result.numpy() #doctest: -DONT_ACCEPT_BLANKLINE
+ array([[[2., 0.],
+ [0., 2.]],
+
+ [[2., 0.],
+ [0., 2.]],
+
+ [[0., 2.],
+ [2., 0.]]], dtype=float32)
+
+ >>> # if multiclass input is provided
+ >>> y_true = tf.constant([[1, 0, 0], [0, 1, 0]],
+ ... dtype=tf.int32)
+ >>> y_pred = tf.constant([[1, 0, 0],[0, 0, 1]],
+ ... dtype=tf.int32)
+ >>> metric = tfa.metrics.MultiLabelConfusionMatrix(num_classes=3)
+ >>> metric.update_state(y_true, y_pred)
+ >>> result = metric(y_true, y_pred)
+ >>> print('Confusion matrix:', result.numpy()) #doctest: -DONT_ACCEPT_BLANKLINE
+ Confusion matrix: [[[2. 0.]
+ [0. 2.]]
+
+ [[2. 0.]
+ [2. 0.]]
+
+ [[2. 2.]
+ [0. 0.]]]
+
"""
@typechecked
diff --git a/tensorflow_addons/metrics/r_square.py b/tensorflow_addons/metrics/r_square.py
index 04c3866dbc..5e98869c96 100644
--- a/tensorflow_addons/metrics/r_square.py
+++ b/tensorflow_addons/metrics/r_square.py
@@ -44,29 +44,31 @@ def _reduce_average(
class RSquare(Metric):
"""Compute R^2 score.
- This is also called the [coefficient of determination
- ](https://en.wikipedia.org/wiki/Coefficient_of_determination).
- It tells how close are data to the fitted regression line.
+ This is also called the [coefficient of determination
+ ](https://en.wikipedia.org/wiki/Coefficient_of_determination).
+ It tells how close are data to the fitted regression line.
- - Highest score can be 1.0 and it indicates that the predictors
+ - Highest score can be 1.0 and it indicates that the predictors
perfectly accounts for variation in the target.
- - Score 0.0 indicates that the predictors do not
+ - Score 0.0 indicates that the predictors do not
account for variation in the target.
- - It can also be negative if the model is worse.
-
- The sample weighting for this metric implementation mimics the
- behaviour of the [scikit-learn implementation
- ](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.r2_score.html)
- of the same metric.
-
- Usage:
- ```python
- actuals = tf.constant([1, 4, 3], dtype=tf.float32)
- preds = tf.constant([2, 4, 4], dtype=tf.float32)
- result = tf.keras.metrics.RSquare()
- result.update_state(actuals, preds)
- print('R^2 score is: ', r1.result().numpy()) # 0.57142866
- ```
+ - It can also be negative if the model is worse.
+
+ The sample weighting for this metric implementation mimics the
+ behaviour of the [scikit-learn implementation
+ ](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.r2_score.html)
+ of the same metric.
+
+ Usage:
+
+ >>> actuals = tf.constant([1, 4, 3], dtype=tf.float32)
+ >>> preds = tf.constant([2, 4, 4], dtype=tf.float32)
+ >>> metric = tfa.metrics.r_square.RSquare()
+ >>> metric.update_state(y_true = actuals, y_pred = preds)
+ >>> result = metric(y_true = actuals, y_pred = preds)
+ >>> print('R^2 score is: ', result.numpy())
+ R^2 score is: 0.57142854
+
"""
@typechecked
diff --git a/tensorflow_addons/optimizers/__init__.py b/tensorflow_addons/optimizers/__init__.py
index e3a6b996dc..a565533632 100644
--- a/tensorflow_addons/optimizers/__init__.py
+++ b/tensorflow_addons/optimizers/__init__.py
@@ -26,6 +26,9 @@
from tensorflow_addons.optimizers.cyclical_learning_rate import (
ExponentialCyclicalLearningRate,
)
+from tensorflow_addons.optimizers.discriminative_layer_training import (
+ MultiOptimizer,
+)
from tensorflow_addons.optimizers.lamb import LAMB
from tensorflow_addons.optimizers.lazy_adam import LazyAdam
from tensorflow_addons.optimizers.lookahead import Lookahead
diff --git a/tensorflow_addons/optimizers/discriminative_layer_training.py b/tensorflow_addons/optimizers/discriminative_layer_training.py
new file mode 100644
index 0000000000..494c29d365
--- /dev/null
+++ b/tensorflow_addons/optimizers/discriminative_layer_training.py
@@ -0,0 +1,166 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Discriminative Layer Training Optimizer for TensorFlow."""
+
+from typing import Union
+
+import tensorflow as tf
+from typeguard import typechecked
+
+
+@tf.keras.utils.register_keras_serializable(package="Addons")
+class MultiOptimizer(tf.keras.optimizers.Optimizer):
+ """Multi Optimizer Wrapper for Discriminative Layer Training.
+
+ Creates a wrapper around a set of instantiated optimizer layer pairs. Generally useful for transfer learning
+ of deep networks.
+
+ Each optimizer will optimize only the weights associated with its paired layer. This can be used
+ to implement discriminative layer training by assigning different learning rates to each optimizer
+ layer pair. (Optimizer, list(Layers)) pairs are also supported. Please note that the layers must be
+ instantiated before instantiating the optimizer.
+
+ Args:
+ optimizers_and_layers: a list of tuples of an optimizer and a layer or model. Each tuple should contain
+ exactly 1 instantiated optimizer and 1 object that subclasses tf.keras.Model or tf.keras.Layer. Nested
+ layers and models will be automatically discovered. Alternatively, in place of a single layer, you can pass
+ a list of layers.
+ optimizer_specs: specialized list for serialization. Should be left as None for almost all cases. If you are
+ loading a serialized version of this optimizer, please use tf.keras.models.load_model after saving a
+ model compiled with this optimizer.
+
+ Usage:
+
+ ```python
+ model = get_model()
+
+ opt1 = tf.keras.optimizers.Adam(learning_rate=1e-4)
+ opt2 = tf.keras.optimizers.Adam(learning_rate=1e-2)
+
+ opt_layer_pairs = [(opt1, model.layers[0]), (opt2, model.layers[1:])]
+
+ loss = tf.keras.losses.MSE
+ optimizer = tfa.optimizers.MultiOpt(opt_layer_pairs)
+
+ model.compile(optimizer=optimizer, loss = loss)
+
+ model.fit(x,y)
+ '''
+
+ Reference:
+
+ [Universal Language Model Fine-tuning for Text Classification](https://arxiv.org/abs/1801.06146)
+ [Collaborative Layer-wise Discriminative Learning in Deep Neural Networks](https://arxiv.org/abs/1607.05440)
+
+ Notes:
+
+ Currently, MultiOpt does not support callbacks that modify optimizers. However, you can instantiate
+ optimizer layer pairs with tf.keras.optimizers.schedules.LearningRateSchedule instead of a static learning
+ rate.
+
+ This code should function on CPU, GPU, and TPU. Apply the with strategy.scope() context as you
+ would with any other optimizer.
+
+ """
+
+ @typechecked
+ def __init__(
+ self,
+ optimizers_and_layers: Union[list, None] = None,
+ optimizer_specs: Union[list, None] = None,
+ name: str = "MultiOptimzer",
+ **kwargs
+ ):
+
+ super(MultiOptimizer, self).__init__(name, **kwargs)
+
+ if optimizer_specs is None and optimizers_and_layers is not None:
+ self.optimizer_specs = [
+ self.create_optimizer_spec(opt, layer)
+ for opt, layer in optimizers_and_layers
+ ]
+
+ elif optimizer_specs is not None and optimizers_and_layers is None:
+ self.optimizer_specs = [
+ self.maybe_initialize_optimizer_spec(spec) for spec in optimizer_specs
+ ]
+
+ else:
+ raise RuntimeError(
+ "You must specify either an list of optimizers and layers or a list of optimizer_specs"
+ )
+
+ def apply_gradients(self, grads_and_vars, name=None, **kwargs):
+ """Wrapped apply_gradient method.
+
+ Returns a list of tf ops to be executed.
+ Name of variable is used rather than var.ref() to enable serialization and deserialization.
+ """
+
+ for spec in self.optimizer_specs:
+ spec["gv"] = []
+
+ for grad, var in tuple(grads_and_vars):
+ for spec in self.optimizer_specs:
+ for name in spec["weights"]:
+ if var.name == name:
+ spec["gv"].append((grad, var))
+
+ return tf.group(
+ [
+ spec["optimizer"].apply_gradients(spec["gv"], **kwargs)
+ for spec in self.optimizer_specs
+ ]
+ )
+
+ def get_config(self):
+ config = super(MultiOptimizer, self).get_config()
+ config.update({"optimizer_specs": self.optimizer_specs})
+ return config
+
+ @classmethod
+ def create_optimizer_spec(cls, optimizer_instance, layer):
+
+ assert isinstance(
+ optimizer_instance, tf.keras.optimizers.Optimizer
+ ), "Object passed is not an instance of tf.keras.optimizers.Optimizer"
+
+ assert isinstance(layer, tf.keras.layers.Layer) or isinstance(
+ layer, tf.keras.Model
+ ), "Object passed is not an instance of tf.keras.layers.Layer nor tf.keras.Model"
+
+ if type(layer) == list:
+ weights = [var.name for sublayer in layer for var in sublayer.weights]
+ else:
+ weights = [var.name for var in layer.weights]
+
+ return {
+ "optimizer": optimizer_instance,
+ "weights": weights,
+ }
+
+ @classmethod
+ def maybe_initialize_optimizer_spec(cls, optimizer_spec):
+ if type(optimizer_spec["optimizer"]) == dict:
+ optimizer_spec["optimizer"] = tf.keras.optimizers.deserialize(
+ optimizer_spec["optimizer"]
+ )
+
+ return optimizer_spec
+
+ def __repr__(self):
+ return "Multi Optimizer with %i optimizer layer pairs" % len(
+ self.optimizer_specs
+ )
diff --git a/tensorflow_addons/optimizers/tests/discriminative_layer_training_test.py b/tensorflow_addons/optimizers/tests/discriminative_layer_training_test.py
new file mode 100644
index 0000000000..08a096b840
--- /dev/null
+++ b/tensorflow_addons/optimizers/tests/discriminative_layer_training_test.py
@@ -0,0 +1,113 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for Discriminative Layer Training Optimizer for TensorFlow."""
+
+import pytest
+import numpy as np
+import tensorflow as tf
+
+from tensorflow_addons.optimizers.discriminative_layer_training import MultiOptimizer
+from tensorflow_addons.utils import test_utils
+
+
+def _dtypes_to_test(use_gpu):
+ # Based on issue #347 in the following link,
+ # "https://github.com/tensorflow/addons/issues/347"
+ # tf.half is not registered for 'ResourceScatterUpdate' OpKernel
+ # for 'GPU' devices.
+ # So we have to remove tf.half when testing with gpu.
+ # The function "_DtypesToTest" is from
+ # "https://github.com/tensorflow/tensorflow/blob/5d4a6cee737a1dc6c20172a1dc1
+ # 5df10def2df72/tensorflow/python/kernel_tests/conv_ops_3d_test.py#L53-L62"
+ # TODO(WindQAQ): Clean up this in TF2.4
+
+ if use_gpu:
+ return [tf.float32, tf.float64]
+ else:
+ return [tf.half, tf.float32, tf.float64]
+
+
+@pytest.mark.with_device(["cpu", "gpu"])
+@pytest.mark.parametrize("dtype", [tf.float16, tf.float32, tf.float64])
+@pytest.mark.parametrize("serialize", [True, False])
+def test_fit_layer_optimizer(dtype, device, serialize):
+ # Test ensures that each optimizer is only optimizing its own layer with its learning rate
+
+ if "gpu" in device and dtype == tf.float16:
+ pytest.xfail("See https://github.com/tensorflow/addons/issues/347")
+
+ model = tf.keras.Sequential(
+ [tf.keras.Input(shape=[1]), tf.keras.layers.Dense(1), tf.keras.layers.Dense(1)]
+ )
+
+ x = np.array(np.ones([100]))
+ y = np.array(np.ones([100]))
+
+ weights_before_train = (
+ model.layers[0].weights[0].numpy(),
+ model.layers[1].weights[0].numpy(),
+ )
+
+ opt1 = tf.keras.optimizers.Adam(learning_rate=1e-3)
+ opt2 = tf.keras.optimizers.SGD(learning_rate=0)
+
+ opt_layer_pairs = [(opt1, model.layers[0]), (opt2, model.layers[1])]
+
+ loss = tf.keras.losses.MSE
+ optimizer = MultiOptimizer(opt_layer_pairs)
+
+ model.compile(optimizer=optimizer, loss=loss)
+
+ # serialize whole model including optimizer, clear the session, then reload the whole model.
+ if serialize:
+ model.save("test", save_format="tf")
+ tf.keras.backend.clear_session()
+ model = tf.keras.models.load_model("test")
+
+ model.fit(x, y, batch_size=8, epochs=10)
+
+ weights_after_train = (
+ model.layers[0].weights[0].numpy(),
+ model.layers[1].weights[0].numpy(),
+ )
+
+ with np.testing.assert_raises(AssertionError):
+ # expect weights to be different for layer 1
+ test_utils.assert_allclose_according_to_type(
+ weights_before_train[0], weights_after_train[0]
+ )
+
+ # expect weights to be same for layer 2
+ test_utils.assert_allclose_according_to_type(
+ weights_before_train[1], weights_after_train[1]
+ )
+
+
+def test_serialization():
+
+ model = tf.keras.Sequential(
+ [tf.keras.Input(shape=[1]), tf.keras.layers.Dense(1), tf.keras.layers.Dense(1)]
+ )
+
+ opt1 = tf.keras.optimizers.Adam(learning_rate=1e-3)
+ opt2 = tf.keras.optimizers.SGD(learning_rate=0)
+
+ opt_layer_pairs = [(opt1, model.layers[0]), (opt2, model.layers[1])]
+
+ optimizer = MultiOptimizer(opt_layer_pairs)
+ config = tf.keras.optimizers.serialize(optimizer)
+
+ new_optimizer = tf.keras.optimizers.deserialize(config)
+ assert new_optimizer.get_config() == optimizer.get_config()
diff --git a/tensorflow_addons/rnn/esn_cell.py b/tensorflow_addons/rnn/esn_cell.py
index d36be9f369..e85f638f43 100644
--- a/tensorflow_addons/rnn/esn_cell.py
+++ b/tensorflow_addons/rnn/esn_cell.py
@@ -32,6 +32,18 @@ class ESNCell(keras.layers.AbstractRNNCell):
"The "echo state" approach to analysing and training recurrent neural networks".
GMD Report148, German National Research Center for Information Technology, 2001.
https://www.researchgate.net/publication/215385037
+
+ Example:
+
+ >>> inputs = np.random.random([30,23,9]).astype(np.float32)
+ >>> ESNCell = tfa.rnn.ESNCell(4)
+ >>> rnn = tf.keras.layers.RNN(ESNCell, return_sequences=True, return_state=True)
+ >>> outputs, memory_state = rnn(inputs)
+ >>> outputs.shape
+ TensorShape([30, 23, 4])
+ >>> memory_state.shape
+ TensorShape([30, 4])
+
Arguments:
units: Positive integer, dimensionality in the reservoir.
connectivity: Float between 0 and 1.
diff --git a/tensorflow_addons/rnn/layer_norm_lstm_cell.py b/tensorflow_addons/rnn/layer_norm_lstm_cell.py
index 3a3a359663..adff626673 100644
--- a/tensorflow_addons/rnn/layer_norm_lstm_cell.py
+++ b/tensorflow_addons/rnn/layer_norm_lstm_cell.py
@@ -46,6 +46,19 @@ class LayerNormLSTMCell(keras.layers.LSTMCell):
"Recurrent Dropout without Memory Loss"
Stanislau Semeniuta, Aliaksei Severyn, Erhardt Barth.
+
+ Example:
+
+ >>> inputs = np.random.random([30,23,9]).astype(np.float32)
+ >>> lnLSTMCell = tfa.rnn.LayerNormLSTMCell(4)
+ >>> rnn = tf.keras.layers.RNN(lnLSTMCell, return_sequences=True, return_state=True)
+ >>> outputs, memory_state, carry_state = rnn(inputs)
+ >>> outputs.shape
+ TensorShape([30, 23, 4])
+ >>> memory_state.shape
+ TensorShape([30, 4])
+ >>> carry_state.shape
+ TensorShape([30, 4])
"""
@typechecked
diff --git a/tensorflow_addons/rnn/layer_norm_simple_rnn_cell.py b/tensorflow_addons/rnn/layer_norm_simple_rnn_cell.py
index f9562c6329..cc5c2b6d70 100644
--- a/tensorflow_addons/rnn/layer_norm_simple_rnn_cell.py
+++ b/tensorflow_addons/rnn/layer_norm_simple_rnn_cell.py
@@ -37,6 +37,17 @@ class LayerNormSimpleRNNCell(keras.layers.SimpleRNNCell):
"Layer Normalization." ArXiv:1607.06450 [Cs, Stat],
July 21, 2016. http://arxiv.org/abs/1607.06450
+ Example:
+
+ >>> inputs = np.random.random([30,23,9]).astype(np.float32)
+ >>> lnsRNNCell = tfa.rnn.LayerNormSimpleRNNCell(4)
+ >>> rnn = tf.keras.layers.RNN(lnsRNNCell, return_sequences=True, return_state=True)
+ >>> outputs, memory_state = rnn(inputs)
+ >>> outputs.shape
+ TensorShape([30, 23, 4])
+ >>> memory_state.shape
+ TensorShape([30, 4])
+
Arguments:
units: Positive integer, dimensionality of the output space.
activation: Activation function to use.
@@ -89,25 +100,19 @@ class LayerNormSimpleRNNCell(keras.layers.SimpleRNNCell):
Examples:
- ```python
- import numpy as np
- import tensorflow.keras as keras
- import tensorflow_addons as tfa
-
- inputs = np.random.random([32, 10, 8]).astype(np.float32)
- rnn = keras.layers.RNN(tfa.rnn.LayerNormSimpleRNNCell(4))
-
- output = rnn(inputs) # The output has shape `[32, 4]`.
-
- rnn = keras.layers.RNN(
- tfa.rnn.LayerNormSimpleRNNCell(4),
- return_sequences=True,
- return_state=True)
+ >>> inputs = np.random.random([32, 10, 8]).astype(np.float32)
+ >>> rnn = tf.keras.layers.RNN(tfa.rnn.LayerNormSimpleRNNCell(4))
+ >>> output = rnn(inputs) # The output has shape `[32, 4]`.
+ >>> rnn = tf.keras.layers.RNN(
+ ... tfa.rnn.LayerNormSimpleRNNCell(4),
+ ... return_sequences=True,
+ ... return_state=True)
+ >>> whole_sequence_output, final_state = rnn(inputs)
+ >>> whole_sequence_output
+
+ >>> final_state
+
- # whole_sequence_output has shape `[32, 10, 4]`.
- # final_state has shape `[32, 4]`.
- whole_sequence_output, final_state = rnn(inputs)
- ```
"""
@typechecked
diff --git a/tensorflow_addons/rnn/nas_cell.py b/tensorflow_addons/rnn/nas_cell.py
index 05054a0233..6b6686ba4b 100644
--- a/tensorflow_addons/rnn/nas_cell.py
+++ b/tensorflow_addons/rnn/nas_cell.py
@@ -38,6 +38,19 @@ class NASCell(keras.layers.AbstractRNNCell):
"Neural Architecture Search with Reinforcement Learning" Proc. ICLR 2017.
The class uses an optional projection layer.
+
+ Example:
+
+ >>> inputs = np.random.random([30,23,9]).astype(np.float32)
+ >>> NASCell = tfa.rnn.NASCell(4)
+ >>> rnn = tf.keras.layers.RNN(NASCell, return_sequences=True, return_state=True)
+ >>> outputs, memory_state, carry_state = rnn(inputs)
+ >>> outputs.shape
+ TensorShape([30, 23, 4])
+ >>> memory_state.shape
+ TensorShape([30, 4])
+ >>> carry_state.shape
+ TensorShape([30, 4])
"""
# NAS cell's architecture base.
diff --git a/tensorflow_addons/rnn/peephole_lstm_cell.py b/tensorflow_addons/rnn/peephole_lstm_cell.py
index 1f791d53d8..658db084f4 100644
--- a/tensorflow_addons/rnn/peephole_lstm_cell.py
+++ b/tensorflow_addons/rnn/peephole_lstm_cell.py
@@ -39,14 +39,16 @@ class PeepholeLSTMCell(tf.keras.layers.LSTMCell):
Example:
- ```python
- # Create 2 PeepholeLSTMCells
- peephole_lstm_cells = [PeepholeLSTMCell(size) for size in [128, 256]]
- # Create a layer composed sequentially of the peephole LSTM cells.
- layer = RNN(peephole_lstm_cells)
- input = keras.Input((timesteps, input_dim))
- output = layer(input)
- ```
+ >>> inputs = np.random.random([30,23,9]).astype(np.float32)
+ >>> LSTMCell = tfa.rnn.PeepholeLSTMCell(4)
+ >>> rnn = tf.keras.layers.RNN(LSTMCell, return_sequences=True, return_state=True)
+ >>> outputs, memory_state, carry_state = rnn(inputs)
+ >>> outputs.shape
+ TensorShape([30, 23, 4])
+ >>> memory_state.shape
+ TensorShape([30, 4])
+ >>> carry_state.shape
+ TensorShape([30, 4])
"""
def build(self, input_shape):
diff --git a/tensorflow_addons/text/__init__.py b/tensorflow_addons/text/__init__.py
index d9c8383dc5..dfb6379ec9 100644
--- a/tensorflow_addons/text/__init__.py
+++ b/tensorflow_addons/text/__init__.py
@@ -16,9 +16,11 @@
# Conditional Random Field
from tensorflow_addons.text.crf import crf_binary_score
+from tensorflow_addons.text.crf import crf_constrained_decode
from tensorflow_addons.text.crf import crf_decode
from tensorflow_addons.text.crf import crf_decode_backward
from tensorflow_addons.text.crf import crf_decode_forward
+from tensorflow_addons.text.crf import crf_filtered_inputs
from tensorflow_addons.text.crf import crf_forward
from tensorflow_addons.text.crf import crf_log_likelihood
from tensorflow_addons.text.crf import crf_log_norm
diff --git a/tensorflow_addons/text/crf.py b/tensorflow_addons/text/crf.py
index 2707895e7d..8bc9901128 100644
--- a/tensorflow_addons/text/crf.py
+++ b/tensorflow_addons/text/crf.py
@@ -24,6 +24,32 @@
# https://github.com/tensorflow/tensorflow/issues/29075 is resolved
+def crf_filtered_inputs(inputs: TensorLike, tag_bitmap: TensorLike) -> tf.Tensor:
+ """Constrains the inputs to filter out certain tags at each time step.
+
+ tag_bitmap limits the allowed tags at each input time step.
+ This is useful when an observed output at a given time step needs to be
+ constrained to a selected set of tags.
+
+ Args:
+ inputs: A [batch_size, max_seq_len, num_tags] tensor of unary potentials
+ to use as input to the CRF layer.
+ tag_bitmap: A [batch_size, max_seq_len, num_tags] boolean tensor
+ representing all active tags at each index for which to calculate the
+ unnormalized score.
+ Returns:
+ filtered_inputs: A [batch_size] vector of unnormalized sequence scores.
+ """
+
+ # set scores of filtered out inputs to be -inf.
+ filtered_inputs = tf.where(
+ tag_bitmap,
+ inputs,
+ tf.fill(tf.shape(inputs), tf.cast(float("-inf"), inputs.dtype)),
+ )
+ return filtered_inputs
+
+
def crf_sequence_score(
inputs: TensorLike,
tag_indices: TensorLike,
@@ -107,11 +133,7 @@ def crf_multitag_sequence_score(
"""
tag_bitmap = tf.cast(tag_bitmap, dtype=tf.bool)
sequence_lengths = tf.cast(sequence_lengths, dtype=tf.int32)
- filtered_inputs = tf.where(
- tag_bitmap,
- inputs,
- tf.fill(tf.shape(inputs), tf.cast(float("-inf"), inputs.dtype)),
- )
+ filtered_inputs = crf_filtered_inputs(inputs, tag_bitmap)
# If max_seq_len is 1, we skip the score calculation and simply gather the
# unary potentials of all active tags.
@@ -559,3 +581,32 @@ def _multi_seq_fn():
return tf.cond(
tf.equal(tf.shape(potentials)[1], 1), _single_seq_fn, _multi_seq_fn
)
+
+
+def crf_constrained_decode(
+ potentials: TensorLike,
+ tag_bitmap: TensorLike,
+ transition_params: TensorLike,
+ sequence_length: TensorLike,
+) -> tf.Tensor:
+ """Decode the highest scoring sequence of tags under constraints.
+
+ This is a function for tensor.
+
+ Args:
+ potentials: A [batch_size, max_seq_len, num_tags] tensor of
+ unary potentials.
+ tag_bitmap: A [batch_size, max_seq_len, num_tags] boolean tensor
+ representing all active tags at each index for which to calculate the
+ unnormalized score.
+ transition_params: A [num_tags, num_tags] matrix of
+ binary potentials.
+ sequence_length: A [batch_size] vector of true sequence lengths.
+ Returns:
+ decode_tags: A [batch_size, max_seq_len] matrix, with dtype `tf.int32`.
+ Contains the highest scoring tag indices.
+ best_score: A [batch_size] vector, containing the score of `decode_tags`.
+ """
+
+ filtered_potentials = crf_filtered_inputs(potentials, tag_bitmap)
+ return crf_decode(filtered_potentials, transition_params, sequence_length)
diff --git a/tensorflow_addons/text/tests/crf_test.py b/tensorflow_addons/text/tests/crf_test.py
index fc92a54a1f..d199d1971c 100644
--- a/tensorflow_addons/text/tests/crf_test.py
+++ b/tensorflow_addons/text/tests/crf_test.py
@@ -35,6 +35,82 @@ def calculate_sequence_score(inputs, transition_params, tag_indices, sequence_le
return expected_unary_score + expected_binary_score
+def brute_force_decode(sequence_lengths, inputs, transition_params):
+ num_words = inputs.shape[0]
+ num_tags = inputs.shape[1]
+
+ all_sequence_scores = []
+ all_sequences = []
+
+ tag_indices_iterator = itertools.product(range(num_tags), repeat=sequence_lengths)
+ inputs = tf.expand_dims(inputs, 0)
+ sequence_lengths = tf.expand_dims(sequence_lengths, 0)
+ transition_params = tf.constant(transition_params)
+
+ # Compare the dynamic program with brute force computation.
+ for tag_indices in tag_indices_iterator:
+ tag_indices = list(tag_indices)
+ tag_indices.extend([0] * (num_words - sequence_lengths))
+ all_sequences.append(tag_indices)
+ sequence_score = text.crf_sequence_score(
+ inputs=inputs,
+ tag_indices=tf.expand_dims(tag_indices, 0),
+ sequence_lengths=sequence_lengths,
+ transition_params=transition_params,
+ )
+ sequence_score = tf.squeeze(sequence_score, [0])
+ all_sequence_scores.append(sequence_score)
+
+ expected_max_sequence_index = np.argmax(all_sequence_scores)
+ expected_max_sequence = all_sequences[expected_max_sequence_index]
+ expected_max_score = all_sequence_scores[expected_max_sequence_index]
+ return expected_max_sequence, expected_max_score
+
+
+@pytest.mark.parametrize("dtype", [np.float16, np.float32])
+def test_crf_filtered_inputs(dtype):
+ # Test both the length-1 and regular cases.
+ sequence_lengths_list = [np.array(3, dtype=np.int32), np.array(1, dtype=np.int32)]
+ inputs_list = [
+ np.array([[4, 5, -3], [3, -1, 3], [-1, 2, 1], [0, 0, 0]], dtype=dtype),
+ np.array([[4, 5, -3]], dtype=dtype),
+ ]
+ tag_bitmap_list = [
+ np.array(
+ [
+ [True, False, False],
+ [False, True, True],
+ [False, True, True],
+ [False, True, True],
+ ],
+ dtype=np.bool,
+ ),
+ np.array([[False, True, True]], dtype=np.bool),
+ ]
+ neg_inf = float("-inf")
+ expected_filtered_inputs_list = [
+ np.array(
+ [[4, neg_inf, neg_inf], [neg_inf, -1, 3], [neg_inf, 2, 1], [neg_inf, 0, 0]],
+ dtype=dtype,
+ ),
+ np.array([[neg_inf, 5, -3]], dtype=dtype),
+ ]
+ for sequence_lengths, inputs, tag_bitmap, expected_filtered_inputs in zip(
+ sequence_lengths_list,
+ inputs_list,
+ tag_bitmap_list,
+ expected_filtered_inputs_list,
+ ):
+ filtered_inputs = text.crf_filtered_inputs(
+ inputs=tf.expand_dims(inputs, 0), tag_bitmap=tf.expand_dims(tag_bitmap, 0)
+ )
+ filtered_inputs = tf.squeeze(filtered_inputs, [0])
+
+ test_utils.assert_allclose_according_to_type(
+ filtered_inputs, expected_filtered_inputs
+ )
+
+
@pytest.mark.parametrize("dtype", [np.float16, np.float32])
def test_crf_sequence_score(dtype):
transition_params = np.array([[-3, 5, -2], [3, 4, 1], [1, 2, 1]], dtype=dtype)
@@ -309,29 +385,9 @@ def test_crf_decode(dtype):
for sequence_lengths, inputs, tag_indices in zip(
sequence_lengths_list, inputs_list, tag_indices_list
):
- num_words = inputs.shape[0]
- num_tags = inputs.shape[1]
-
- all_sequence_scores = []
- all_sequences = []
-
- # Compare the dynamic program with brute force computation.
- for tag_indices in itertools.product(range(num_tags), repeat=sequence_lengths):
- tag_indices = list(tag_indices)
- tag_indices.extend([0] * (num_words - sequence_lengths))
- all_sequences.append(tag_indices)
- sequence_score = text.crf_sequence_score(
- inputs=tf.expand_dims(inputs, 0),
- tag_indices=tf.expand_dims(tag_indices, 0),
- sequence_lengths=tf.expand_dims(sequence_lengths, 0),
- transition_params=tf.constant(transition_params),
- )
- sequence_score = tf.squeeze(sequence_score, [0])
- all_sequence_scores.append(sequence_score)
-
- expected_max_sequence_index = np.argmax(all_sequence_scores)
- expected_max_sequence = all_sequences[expected_max_sequence_index]
- expected_max_score = all_sequence_scores[expected_max_sequence_index]
+ expected_max_sequence, expected_max_score = brute_force_decode(
+ sequence_lengths, inputs, transition_params
+ )
actual_max_sequence, actual_max_score = text.crf_decode(
tf.expand_dims(inputs, 0),
@@ -350,6 +406,61 @@ def test_crf_decode(dtype):
)
+@pytest.mark.parametrize("dtype", [np.float16, np.float32])
+def test_crf_constrained_decode(dtype):
+ transition_params = np.array([[-3, 5, -2], [3, 4, 1], [1, 2, 1]], dtype=dtype)
+ # Test both the length-1 and regular cases.
+ sequence_lengths_list = [np.array(3, dtype=np.int32), np.array(1, dtype=np.int32)]
+ inputs_list = [
+ np.array([[4, 5, -3], [3, -1, 3], [-1, 2, 1], [0, 0, 0]], dtype=dtype),
+ np.array([[4, 5, -3]], dtype=dtype),
+ ]
+ tag_bitmap_list = [
+ np.array(
+ [
+ [True, False, False],
+ [False, True, True],
+ [False, True, True],
+ [False, True, True],
+ ],
+ dtype=np.bool,
+ ),
+ np.array([[False, True, True]], dtype=np.bool),
+ ]
+ for sequence_lengths, inputs, tag_bitmap in zip(
+ sequence_lengths_list, inputs_list, tag_bitmap_list
+ ):
+ filtered_inputs = text.crf_filtered_inputs(
+ inputs=tf.expand_dims(inputs, 0), tag_bitmap=tf.expand_dims(tag_bitmap, 0)
+ )
+
+ expected_max_sequence, expected_max_score = text.crf_decode(
+ filtered_inputs,
+ tf.constant(transition_params),
+ tf.expand_dims(sequence_lengths, 0),
+ )
+
+ expected_max_sequence = tf.squeeze(expected_max_sequence, [0])
+ expected_max_score = tf.squeeze(expected_max_score, [0])
+
+ actual_max_sequence, actual_max_score = text.crf_constrained_decode(
+ tf.expand_dims(inputs, 0),
+ tf.expand_dims(tag_bitmap, 0),
+ tf.constant(transition_params),
+ tf.expand_dims(sequence_lengths, 0),
+ )
+
+ actual_max_sequence = tf.squeeze(actual_max_sequence, [0])
+ actual_max_score = tf.squeeze(actual_max_score, [0])
+
+ test_utils.assert_allclose_according_to_type(
+ actual_max_score, expected_max_score, 1e-6, 1e-6
+ )
+ assert list(actual_max_sequence[:sequence_lengths]) == list(
+ expected_max_sequence[:sequence_lengths]
+ )
+
+
def test_crf_decode_zero_seq_length():
"""Test that crf_decode works when sequence_length contains one or more
zeros."""
diff --git a/tools/docker/sanity_check.Dockerfile b/tools/docker/sanity_check.Dockerfile
index 68393a9705..9300da5a6d 100644
--- a/tools/docker/sanity_check.Dockerfile
+++ b/tools/docker/sanity_check.Dockerfile
@@ -94,7 +94,7 @@ RUN apt-get update && apt-get install -y rsync
COPY ./ /addons
WORKDIR /addons
RUN pip install --no-deps -e .
-RUN python docs/build_docs.py
+RUN python tools/docs/build_docs.py
RUN touch /ok.txt
# -------------------------------
diff --git a/docs/BUILD b/tools/docs/BUILD
similarity index 100%
rename from docs/BUILD
rename to tools/docs/BUILD
diff --git a/tools/docs/Readme.md b/tools/docs/Readme.md
new file mode 100644
index 0000000000..7c574e5ad8
--- /dev/null
+++ b/tools/docs/Readme.md
@@ -0,0 +1,19 @@
+## 1. Generated API docs
+
+[tensorflow.org/addons/api_docs/python/tfa](https://tensorflow.org/addons/api_docs/python/tfa)
+
+`build_docs.py` controls executed this docs generation. To test-run it:
+
+```bash
+# Install dependencies:
+pip install -r tools/install_deps/doc_requirements.txt
+
+# Build tool:
+bazel build //tools/docs:build_docs
+
+# Generate API doc:
+# Use current branch
+bazel-bin/tools/docs/build_docs --git_branch=$(git rev-parse --abbrev-ref HEAD)
+# or specified explicitly
+bazel-bin/tools/docs/build_docs --git_branch=master --output_dir=/tmp/tfa_api
+```
diff --git a/docs/build_docs.py b/tools/docs/build_docs.py
similarity index 100%
rename from docs/build_docs.py
rename to tools/docs/build_docs.py