[SPARK-21923][CORE]Avoid calling reserveUnrollMemoryForThisTask for every record #19135
Conversation
|
Hi, @cloud-fan @jerryshao Would you mind take a look ? Thanks a lot |
|
Here https://github.com/apache/spark/pull/19135/files?diff=unified#diff-870cd3693df7a5add2ac3119d7d91d34L373, we call |
|
Sorry I'm not so familiar with this part, but from the test result seems that the performance just improved a little. I would doubt the way you generate RDD Also I see you use 1 executor with 20 cores to do test. In the normal usage case we will not allocate so many cores to 1 executor, can you please test with 2-4 cores per executor, I guess with less cores, the contention of MemoryManager lock should be alleviated, and the performance might be close. |
|
Firstly, Serialization time did not take a long time. You can see follow: Secondly, I do not think that every executor in a distributed system should be set to very little core and memory. Because the more the process also means that more communication between the process, which means more data serialization and deserialization. Thirdly, only when there are enough concurrent threads, thread synchronization will cause performance problems. In the server, we have 70 to 80 cores, concurrent tasks more than this. This change is really small, the proportion of the entire task is also very small, so the impact on the total time is not so big, but in this test case, still increased by 5%. |
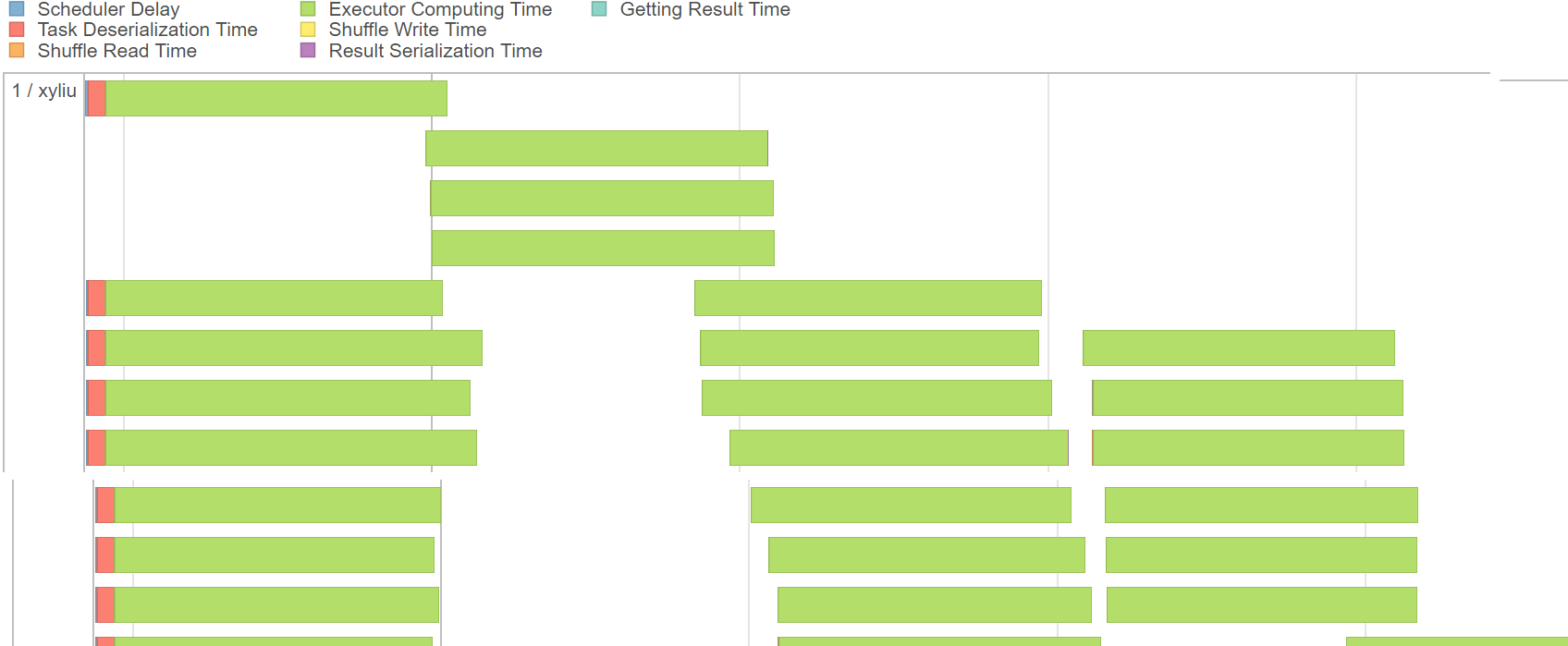
|
Does this patch has regressions? It seems to me that allocating more memory may starve other tasks/operators and reduce the overall performance. |
|
hi @cloud-fan, The previous writing is the same as |
|
It would be great to test the perf on executors with various corsPerExecutor settings to ensure we don't bring in regressions by the code change. |
|
@jiangxb1987 Ok, I can test it later. The following picture is when I run kmeans and put the source data into the offheap memory, and you can see the CPU time occupied by |
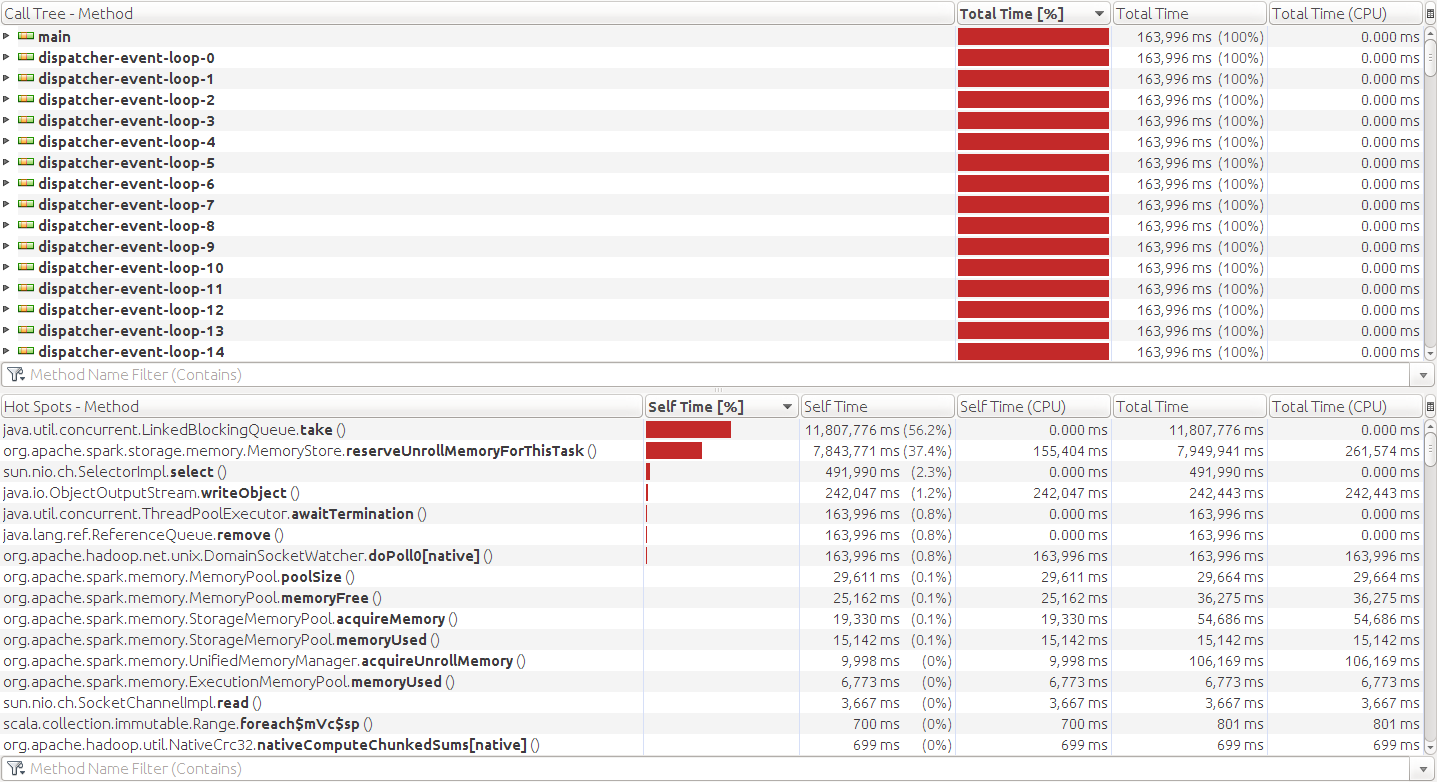
|
is it better to do batch unrolling? i.e., we can check memory usage and request memory for like every 10 records, instead of doing it for every record. |
|
@cloud-fan Very sorry to reply so late. I updated the code followed your suggestion. Does this need performance test? If needed, I will test it late. |
|
Hi @cloud-fan , @jiangxb1987 . The follow is the test result, I have modified the test to server.
20 cores with 150GB memory:
50 cores with 150GB memory
|
|
So it somehow reflects that CPU core contention is the main issue for memory pre-occupation , am I right? AFAIK from our customer, we usually don't allocate so many cores to one executor, also avoid big executor (many cores + large heap memory) to reduce GC and other memory/cpu contentions. |
|
Hi @jerryshao thanks for your reviewing.
I have modified the code, now it will not request more memory, it just reduce the times of calling Yeah, its impact will be small with small cores. In the above test results, it doesn't bring any regressions, and also better for many cores. For machine learning, we need cache the source data to OFF_HEAP in order to reduce the gc problem. For the configuration, I think the different application scenarios may be different. |
| // Number of elements unrolled so far | ||
| var elementsUnrolled = 0L | ||
| // How often to check whether we need to request more memory | ||
| val memoryCheckPeriod = 16 |
There was a problem hiding this comment.
This is the same approach we used in putIteratorAsValues. One thing still missing is memoryGrowthFactor, can we add that too?
There was a problem hiding this comment.
in the future we should do some refactor between putIteratorAsValues and putIteratorAsBytes, to reduce duplicated code.
There was a problem hiding this comment.
OK, I'll add it. I think I can take a try to refactor it. Do you need a separate pr?
There was a problem hiding this comment.
yea definitely not in this PR.
| // Number of elements unrolled so far | ||
| var elementsUnrolled = 0L | ||
| // How often to check whether we need to request more memory | ||
| val memoryCheckPeriod = 16 |
There was a problem hiding this comment.
Should this be made configurable? Or can we make sure it's the best magic number that we can choose?
There was a problem hiding this comment.
it's hard coded in putIteratorAsValues too, we can improve it later.
There was a problem hiding this comment.
I have just made it configurable. I'm not sure if this writting is reasonable.
| val initialMemoryThreshold = unrollMemoryThreshold | ||
| // How often to check whether we need to request more memory | ||
| val memoryCheckPeriod = 16 | ||
| val memoryCheckPeriod = conf.getLong("spark.storage.unrollMemoryCheckPeriod", 16) |
There was a problem hiding this comment.
we should move these 2 configs to org.apache.spark.internal.config and add some documents. They should be internal config I think.
There was a problem hiding this comment.
OK, moved. Pls take a took.
| private[spark] val UNROLL_MEMORY_CHECK_PERIOD = | ||
| ConfigBuilder("spark.storage.unrollMemoryCheckPeriod") | ||
| .doc("The memory check period is used to determine how often we should check whether " | ||
| + "there is a need to request more memory when we try to put the given block in memory.") |
|
retest this please |
|
LGTM except one minor comment |
|
|
||
| private[spark] val UNROLL_MEMORY_CHECK_PERIOD = | ||
| ConfigBuilder("spark.storage.unrollMemoryCheckPeriod") | ||
| .doc("The memory check period is used to determine how often we should check whether " |
There was a problem hiding this comment.
let's call .internal() here, to make them internal configs, as we don't expect users to tune it.
|
Test build #81868 has finished for PR 19135 at commit
|
|
Hi @cloud-fan, thanks for reviewing. The code has updated, pls take a look. |
|
retest this please |
|
Test build #81878 has finished for PR 19135 at commit
|
|
thanks, merging to master! |
What changes were proposed in this pull request?
When Spark persist data to Unsafe memory, we call the method
MemoryStore.putIteratorAsBytes, which need synchronize thememoryManagerfor every record write. This implementation is not necessary, we can apply for more memory at a time to reduce unnecessary synchronization.How was this patch tested?
Test case (with 1 executor 20 core):
Test result:
before
| 27647 | 29108 | 28591 | 28264 | 27232 |
after
| 26868 | 26358 | 27767 | 26653 | 26693 |