diff --git a/.gitignore b/.gitignore
index 9b888ef6..8a8d76bb 100644
--- a/.gitignore
+++ b/.gitignore
@@ -325,3 +325,6 @@ cython_debug/
# Others
docs/api/
!/docs/api/index.rst
+
+# requirements.txt
+!*/requirements.*.txt
\ No newline at end of file
diff --git a/README.md b/README.md
index dfed7640..9145d9b7 100644
--- a/README.md
+++ b/README.md
@@ -56,7 +56,7 @@
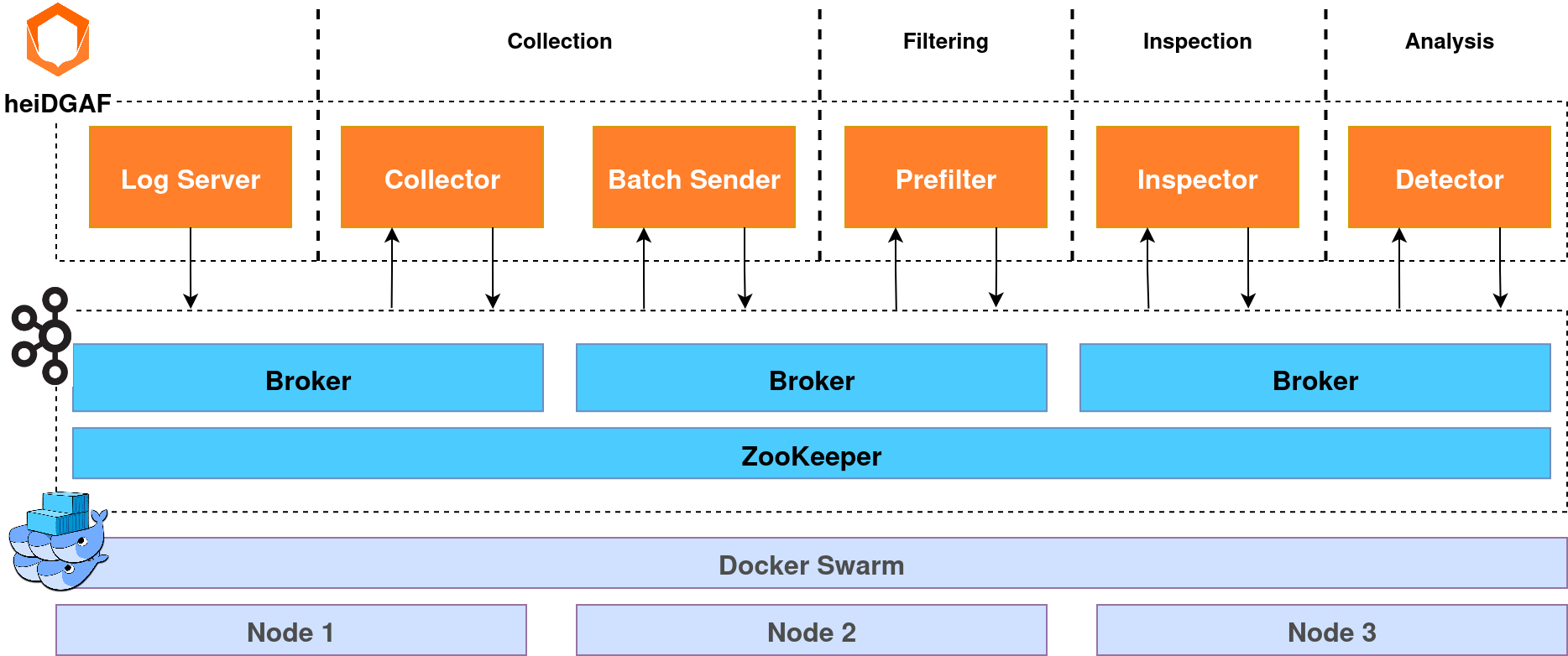
## About the Project
-
+
## Getting Started
@@ -276,6 +276,31 @@ This will create a `rules.txt` file containing the innards of the model, explain